

AWS Glueとは?
re:Invent 2016 DAY3 keynote にて発表された新サービスとなります。
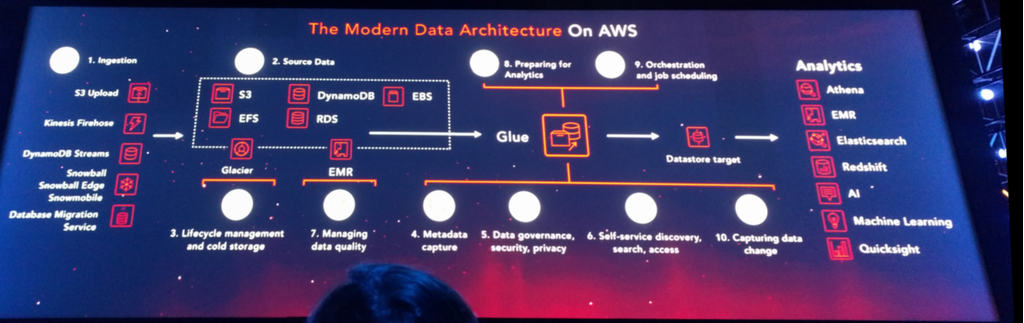
サービス名の由来は、下図に記載の「モダンデータアーキテクチャ」(AWSの表現)構築のために必要な各種サービスの繋ぎ込みを行う際に、糊 のように動作するサービスとの事です。
※会場では製品名が発表された際に笑いにつつまれた事を注記させて頂きます
公式リンク
https://aws.amazon.com/jp/glue/
AWS Glue はフルマネージドの ETL サービスです。
困難で時間のかかるデータの発見、変換、マッピング、およびジョブスケジューリングのタスクを簡素化し、自動化します。
使いやすいコンソールでデータを移動するプロセスをガイドし、データソースの理解、分析のためのデータの準備、データソースから宛先への信頼性の高いロードに役立ちます。
※ETLとは Extract/Transform/Load(データの抽出、変換、ロード)を行うツール - wikipedia
動作手順
Step 1. データカタログの構築
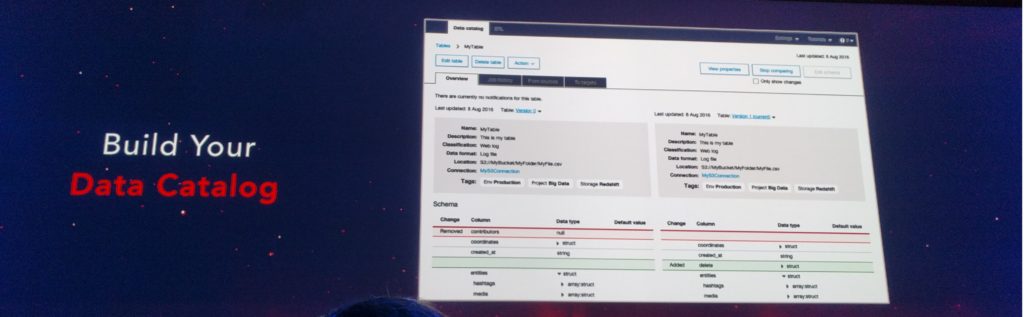
AWS管理コンソールを使用して、AWS Glueでデータソースを登録します。 AWS Glueは、JSON、CSV、Parquetなど、多くの一般的なソースフォーマットやデータタイプに対して、あらかじめ作成された分類子を使用してデータソースをクロールし、データカタログを構築します。また、独自のクラシファイアを追加したり、AWS Glueコミュニティからクラシファイアを選択してクロールに追加することもできます。(google翻訳)
Step 2. データ変換ルールをコードで記載
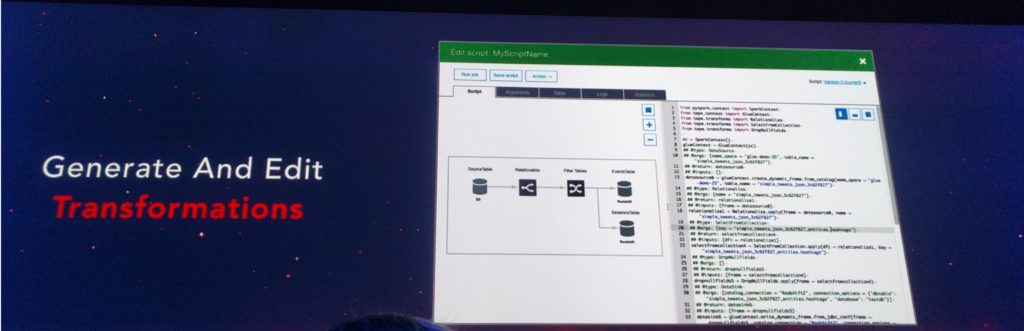
データソースとターゲットを選択すると、AWS GlueはPythonコードを生成してソースからデータを抽出し、ターゲットスキーマと一致するようにデータを変換し、ターゲットにロードします。自動生成コードは、データやハードウェアの不良などの一般的なエラーのケースを処理します。このコードは、お気に入りのIDEを使用して編集し、独自のサンプルデータでテストすることができます。また、他のAWS Glueユーザーと共有しているコードをブラウズして、自分の仕事に引き込むこともできます。(google翻訳)
Step 3. スケジュールの作成・実行
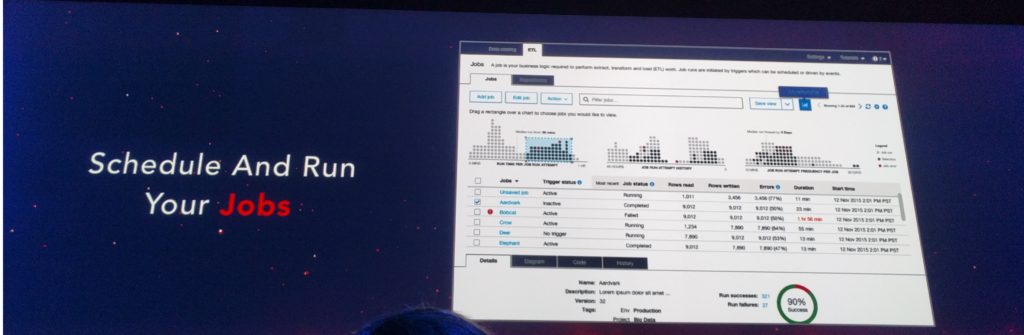
AWS Glueの柔軟なスケジューラを使用して、定期的に、トリガに応じて、またはAWS Lambdaイベントに対応してフローを実行できます。 AWS GlueはETLジョブをApache Sparkノードに自動的に配布するため、データ量が増えるにつれてETLの実行時間が一定に保たれます。 AWS Glueはジョブの実行を適切な順序で調整し、失敗したジョブを自動的に再試行します。 AWS Glueは、時間通りにジョブを完了し、コストを最小限に抑えるために必要なインフラストラクチャをスケーラブルに拡張します。(google翻訳)
まとめ
データ変換・取り込みのために同じような処理を記載したり、CSVフォーマットが変更されるたびにプログラム変更を実際に現場で行っている事もあり
そのような処理の手助けを行ってくれるという事で、非常に楽しみなサービスです(まだcoming soonとなっております)
Pythonコード生成や、データが増えてもスケーラブルに対応、処理結果の可視化も大きな魅力と感じました。














