概要
タイトルの通り、「EMRのベストプラクティス」についてのセッションを聞きました。
English Onlyなので聞き逃したことがあるかもしれませんが、まとめてみました。
EMRとは
Hadoopフレームワークが提供された、動的にスケーリング可能なシステムです。
例えば、RDSに保存された顧客情報を解析してある値を計算したり難しいことが出来ます。
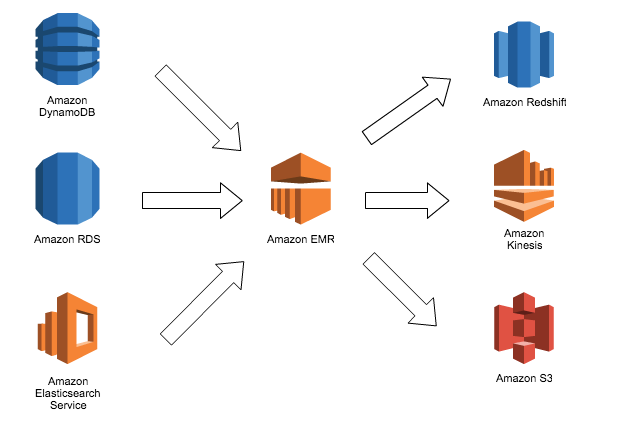
多くのストレージの中からシステムに合うものを利用しましょう
入力元は下記など
- DynamoDB
- RDS
- ElasticSearch
出力先は下記など
- RedShift
- Kinesis
- S3
S3を使用するときのヒント(パーティション、圧縮、およびファイル形式)
- 辞書順でキー名を避ける
- スループットS3リストのパフォーマンスを向上させる
- ハッシュ/ランダム接頭辞を使用するか、日時を逆転する
- S3からEc2までの帯域を最小にするようにデータを圧縮する
- Parquestのようなカラム形式のファイルは、読み込みでパフォーマンスが向上する
セキュリティ
- IAMロールなどを使用して、出来ることを制限する。
- VPCを分けて、クラスタインスタンスに制限をかけましょう。
最後に
EMRのような分散システムはクラウドならではのサービスですね。
上手くEMRの活用が出来る一助になれると幸いです。
MIRAGEという会場が分からず、ラスベガスで一人迷子になったのは良い思い出です・・・
投稿者プロフィール
最新の投稿
 AWS2021年12月2日AWS Graviton3 プロセッサを搭載した EC2 C7g インスタンスが発表されました。
AWS2021年12月2日AWS Graviton3 プロセッサを搭載した EC2 C7g インスタンスが発表されました。 セキュリティ2021年7月14日ゼロデイ攻撃とは
セキュリティ2021年7月14日ゼロデイ攻撃とは- セキュリティ2021年7月14日マルウェアとは
- WAF2021年7月13日クロスサイトスクリプティングとは?