はじめに
Amazon Bedrockに触れてみよう!の第三弾です。
少し番外編となりますが、これまでAWSのコンソール画面やSDKを使用してBedrockの検証を行ってきましたが、StreamlitというPythonのフレームワークを用いて簡易的なチャットボットを作ってみようと思います。
検証する上でもオリジナルなUIがあるとやる気が出ます。笑
第一弾ブログはこちら -> Amazon Bedrockと触れ合おう 〜コンソール画面を眺めよう〜
第二弾ブログはこちら -> Amazon Bedrockと触れ合おう 〜RAKUにRAGを構築しよう〜
目次
Streamlitとは?
PythonのWebアプリケーション向きのフレームワークといえば、DjangoやFlaskが有名かと思います。
弊社でもFlaskを採用しアプリ開発の実績もございます。(少し宣伝)
Streamlitは、機械学習やデータサイエンス向きのWebアプリケーション開発に向いているようで
PoCでサクッとグラフ描画をしたい!のような場面で大活躍するフレームワークになります。
HTMLやCSSを書く必要もなく、オシャレな画面を作ることが出来ます。
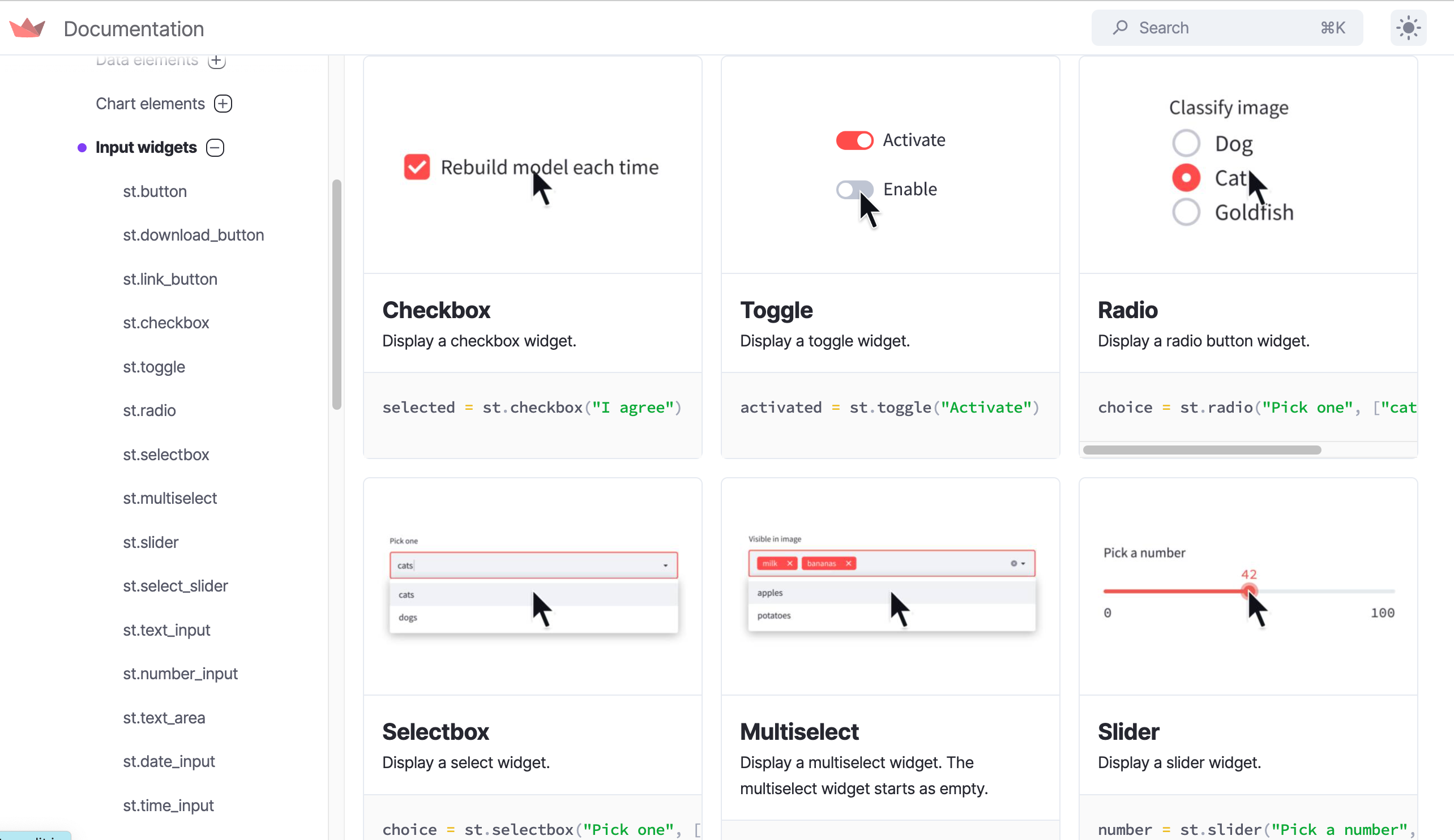
ドキュメントはこちらです。
APIリファレンスを眺めてるだけでも楽しいです。
このような形でイメージ付きで記載してあるため非常に実装が楽です。
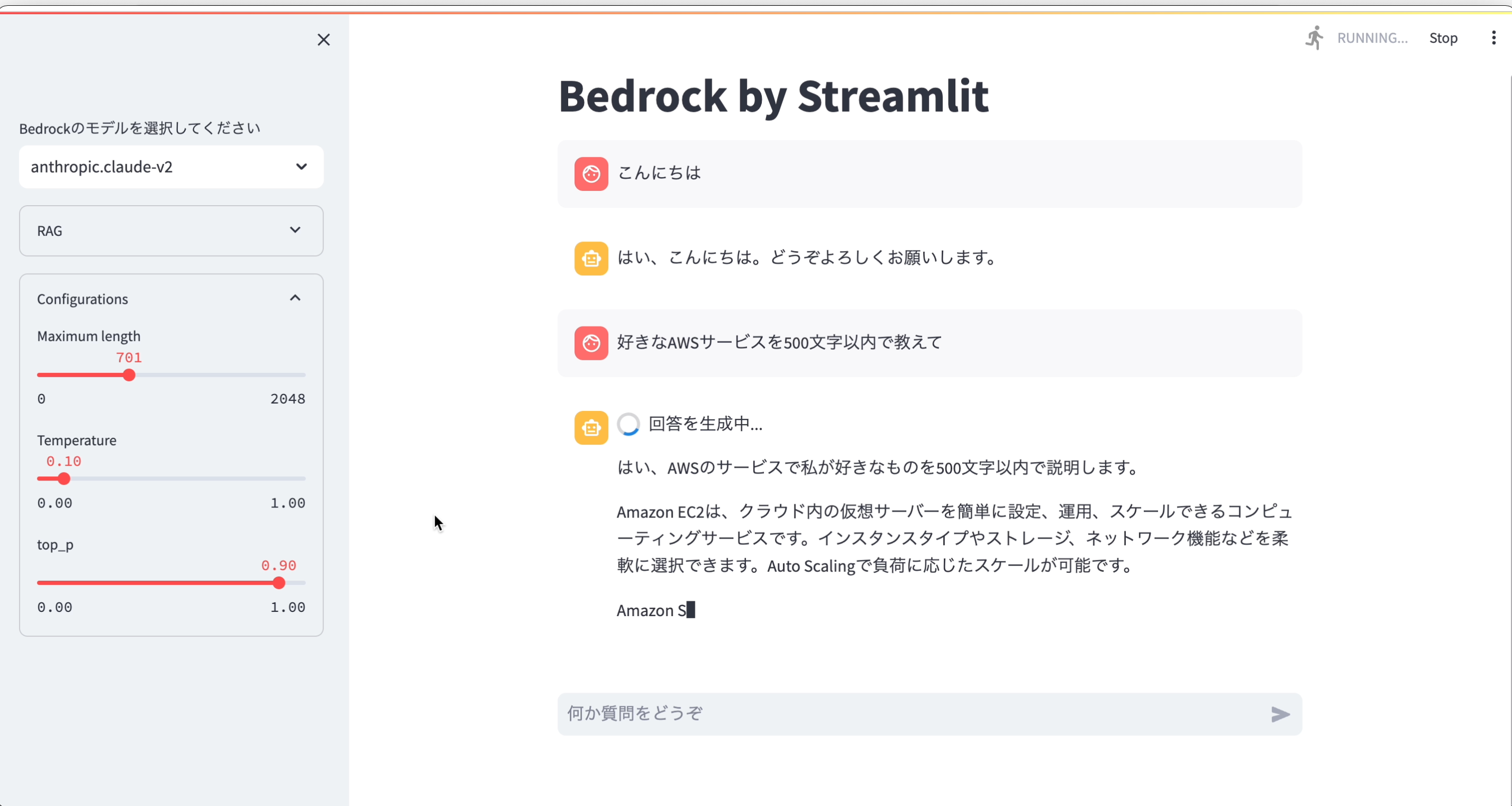
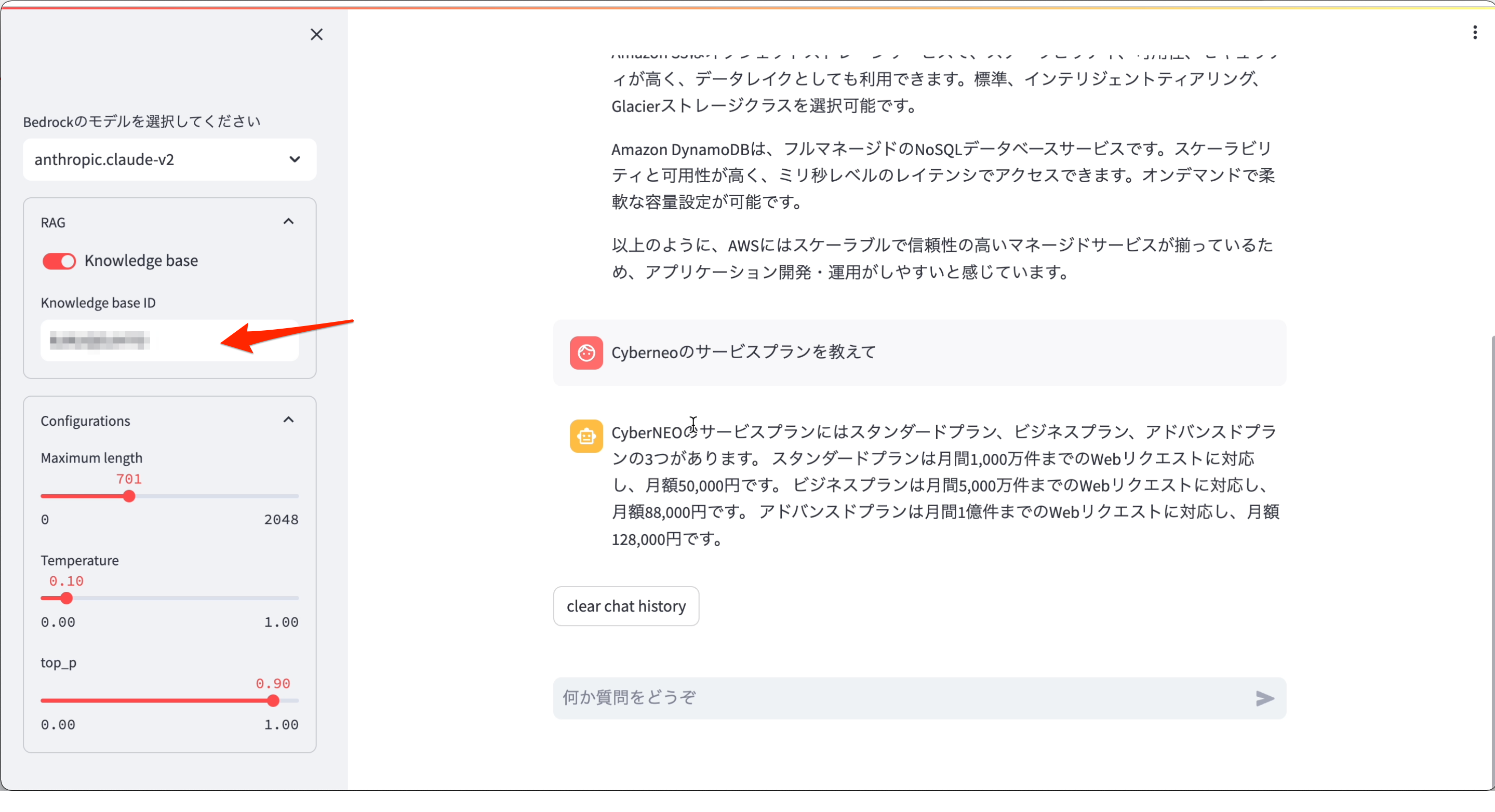
完成イメージ
まずは完成イメージです。
通常のチャットボット機能
- セレクトボックスよりBedrockの基盤モデルを選択します
- ConfigurationsでレスポンスMaxトークンやTemperature、Top_pの値を設定
- 入力欄からpromptを入力し、チャットボットを開始
RAG参照機能
- RAGの使用有に選択し、Knowledge base IDの入力(Bedrockのコンソール画面よりコピペ)
- あとは通常の手順と同様
早速作ってみた
通常であればローカルでも問題なく開発&動作確認が出来るのですが、私のマシン側の問題により動作確認が取れなかったためCloud9を使って開発&動作確認を行いました。
エンジニアとしては原因を突き止めるべきですが、早く動かしてみたい欲が強く早々に調査を諦めました(言い訳)
Cloud9を構築後、どうやらスペックが小さいことが原因ようでライブラリのインストールで何度か止まってしまったので「t3.small」にスケールアップさせました。
また検証で使用する8080ポートを特定IPのみ許可のSGをアタッチさせます。
次に下記ライブラリをインストールして準備は完了です。
|
1 2 |
streamlit==1.29.0 boto3==1.34.10 |
下記ソースコードは、サイドバーの設定処理の抜粋になります。
たったこれだけでサイドバー部分の実装は終わりになります。
基盤モデルの設定値をセッションに詰めて、後ほど呼び出すBedrockのパラメータに渡す形になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def init_page(): st.set_page_config(page_title="ChatBot", page_icon="  ") ") # サイドバーを表示 st.sidebar.title("基盤モデル設定") # 左サイドバー with st.sidebar: bedrock_model = st.selectbox("Bedrockのモデルを選択してください", (BEDROCK_MODEL_LIST)) st.session_state["bedrock_model"] = bedrock_model with st.expander(label="RAG", expanded=False): rag_on = st.toggle("Knowledge base") if rag_on: st.session_state["knowledge_base_id"] = st.text_input(label="Knowledge base ID", type="default") st.session_state["rag_on"] = rag_on with st.expander(label="Configurations", expanded=True): max_tokens_to_sample = st.slider(label="Maximum length", min_value=0, max_value=2048, value=300) st.session_state["max_tokens_to_sample"] = max_tokens_to_sample temperature = st.slider(label="Temperature", min_value=0.0, max_value=1.0, value=0.1, step=0.1) st.session_state["temperature"] = temperature top_p = st.slider(label="top_p", min_value=0.00, max_value=1.00, value=0.90, step=0.01) st.session_state["top_p"] = top_p |
次にチャットボットのI/F部分になります。
こちらもStreamlitの部品を最大限に利用しています。
RAGの使用有無によって呼び出す関数を分けています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
def show_page(): # ユーザーからの新しい入力を取得(Bedrock用) if prompt := st.chat_input("何か質問をどうぞ"): st.session_state.messages.append({"role": "Human", "content": prompt}) with st.chat_message("Human"): st.markdown(prompt) with st.chat_message("Assistant"): with st.spinner("回答を生成中..."): message_placeholder = st.empty() full_response = "" if st.session_state["rag_on"]: full_response = _retrieve_and_generate(prompt, message_placeholder) else: full_response = _invoke_model_with_response_stream_claude(prompt, message_placeholder, full_response) st.session_state.messages.append({"role": "Assistant", "content": full_response}) st.session_state.Clear = True # チャット履歴のクリアボタンを有効にする .... |
RAGを使用しない場合の呼び出し方法です。
ストリーミング応答可能なAPIを使用して、画面表示もそれっぽく工夫しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
def _invoke_model_with_response_stream_claude(input, message_placeholder, full_response): # Bedrockからのストリーミング応答を処理 bedrock = boto3.client(service_name="bedrock-runtime", region_name=REGION_NAME) messages = [m["role"] + ":" + m["content"] for m in st.session_state.messages] body = json.dumps( { "prompt": "\n\n" + "\n\n".join(messages) + "\n\nAssistant:", "max_tokens_to_sample": st.session_state["max_tokens_to_sample"], "temperature": st.session_state["temperature"], "top_p": st.session_state["top_p"], } ) response = bedrock.invoke_model_with_response_stream(modelId=st.session_state["bedrock_model"], body=body) stream = response.get("body") if stream: for event in stream: chunk = event.get("chunk") if chunk: full_response += json.loads(chunk.get("bytes").decode())["completion"] message_placeholder.markdown(full_response + "▌") message_placeholder.markdown(full_response) return full_response |
RAGを使用する場合の呼び出し方法です。
こちらはストリーミング応答可能なAPIが見つからなかったので、レスポンス結果から必要な部分を抜き出して、画面表示させています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
def _retrieve_and_generate(input, message_placeholder): # BedrockからのRAG応答を処理 bedrock_agent_runtime = boto3.client("bedrock-agent-runtime", region_name=REGION_NAME) full_response = bedrock_agent_runtime.retrieve_and_generate( input={"text": input}, retrieveAndGenerateConfiguration={ "type": "KNOWLEDGE_BASE", "knowledgeBaseConfiguration": { "knowledgeBaseId": st.session_state["knowledge_base_id"], "modelArn": f'arn:aws:bedrock:{REGION_NAME}::foundation-model/{st.session_state["bedrock_model"]}', }, }, )["output"]["text"] message_placeholder.markdown(full_response) return full_response |
少し省略してご紹介していますが全部で150行程度でこのようなチャットボットを作成することが出来ます。
お好みのデザインで実装してぜひトライしてみてください。
展望
ここまでで簡単にチャットボットシステムが作れることはお分かりになったかと思いますが、実際に本番運用する上では足りていない機能がいくつかあるかと思います。(PoCでサクッと作る分には申し分ないですが)
StreamlitをAWS上に構築するなら、このようなシステム構成で構築がベストかなと考えていますので解説していきます。
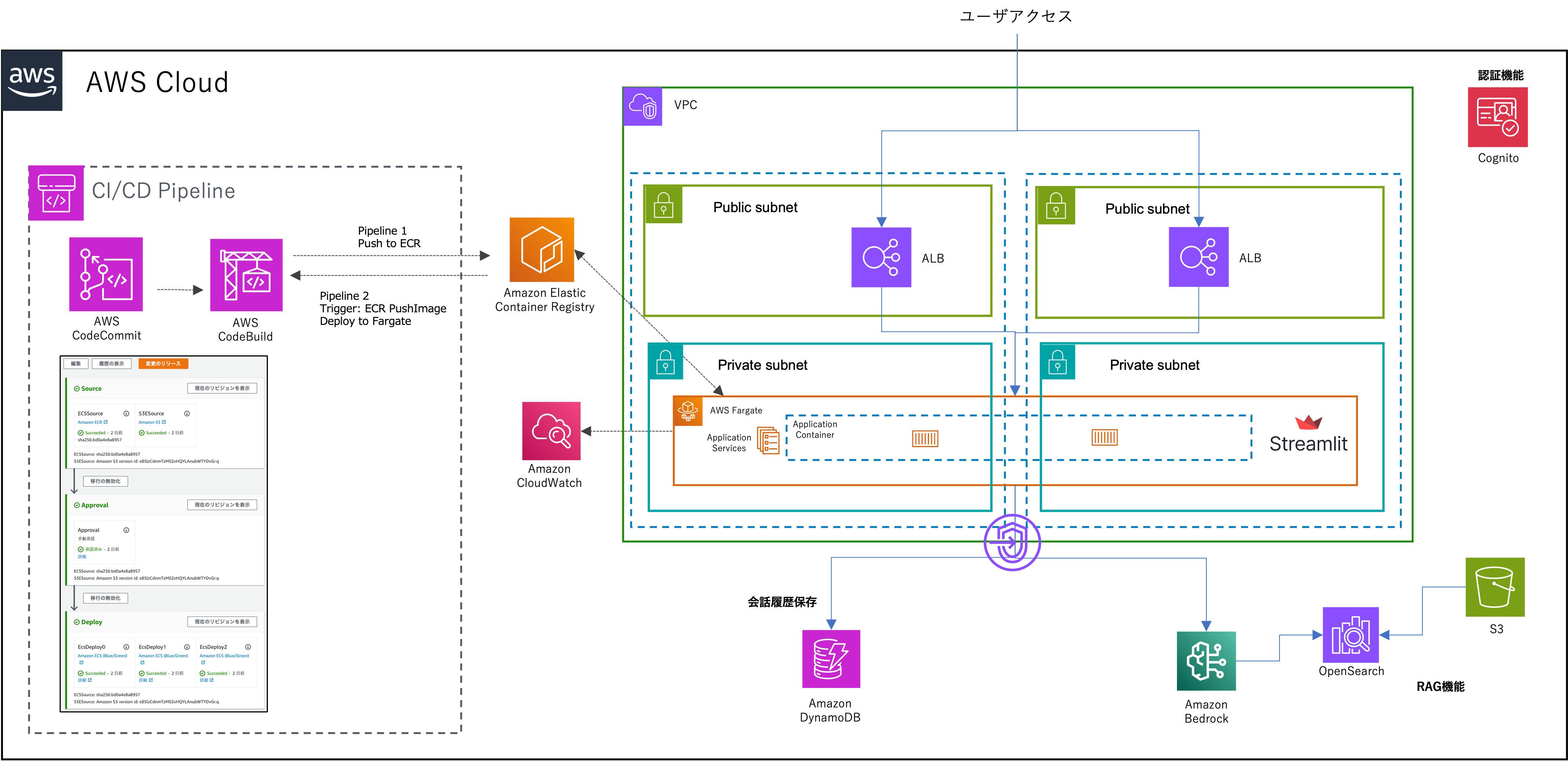
- ALB -> ECS on Fargate:StreamlitをPrivateサブネットのFargate上で動作
- Code兄弟:コンテナイメージの作成及びFargateへのデプロイ
- DynamoDB:会話の履歴保存のために使用
- VPCエンドポイント:DynamoDBやBedrock、CloudWatchへは全てAWS内経由でアクセス
- Cognito:認証機能
ざっと思いつく限りで書いてみましたがこのような形がベストでしょうか。
CDKで定義しておいて、チャットボットシステムとしてすぐに環境構築が出来れば完璧ですね。
Streamlitを使う機会がある方に少しでも参考になれば幸いです。
投稿者プロフィール
-
2021/2にスカイアーチネットワークスにJoin。
(前職ではAIのシステム開発やPoCなどを主に担当)
2024 Japan AWS Top Engineers (Services)
2024 Japan AWS All Certifications Engineers
現在の業務では主にクラウドネイティブなWebアプリケーション/APIのインフラ構築から開発まで幅広く担当。
好きなAWSサービス:AWS CDK、Amazon Bedrock
趣味:読書と競馬鑑賞