はじめに
前回、Amazon Transcribe と Amazon Comprehend で”疑似”議事録を作成するという記事をかいたのですが、Amazon Bedrock に議事録を作成する機能があると知り、使用してみたところより精度の高い議事録を作成することができたので紹介させていただきます。
※内容的には前回の記事で作成した関数に新しく Bedrock を追加するというものになっているので、記載が被る部分は一部省略しています。
Amazon Bedrock とは?
Amazon Bedrockは、機械学習(ML)モデルを簡単に構築、管理、デプロイするためのプラットフォームです。生成AIを用いて、様々なシーンで業務を効率化することができます。詳しくは AWS の公式ページをご参照ください。
手順
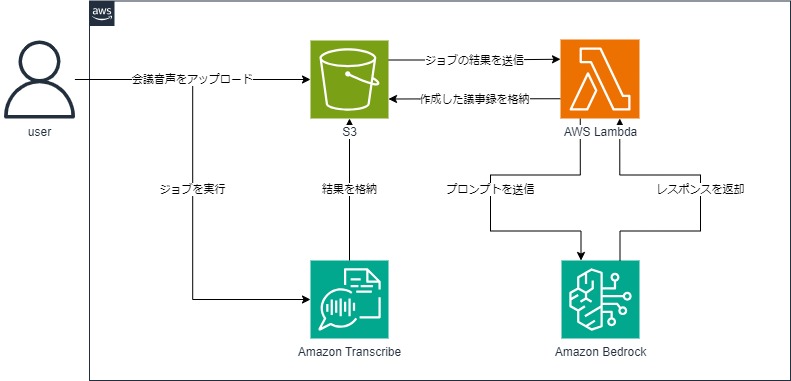
前回の手順は、
- 会議の音声データを S3 へアップロードする
- Amazon Transcribe でジョブを作成する
- Lambda を使用して議事録を作成する
というものでした。今回も2番までは前回と同様です。
3番の Lambda で使用する関数に手を加え、Bedrock を使用するように修正します。
修正後の関数が以下です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
import json import boto3 # 変数 s3_bucket = '出力データをアップロードしたバケット名' s3_key = '出力データのプレフィックス' region = 'ap-northeast-1' encode = 'utf-8' # client s3_client = boto3.client('s3', region_name=region) bedrock_client = boto3.client('bedrock-runtime', region_name=region) def lambda_handler(event, context): try: # S3からファイルを読み取る response = s3_client.get_object(Bucket=s3_bucket, Key=s3_key) file_content = response['Body'].read().decode('utf-8') minutes_job = json.loads(file_content) items = minutes_job['results']['items'] # 議事内容の取得 transcript = minutes_job['results']['transcripts'][0]['transcript'] # 日付の処理 meeting_date = s3_client.head_object(Bucket=s3_bucket, Key=s3_key) date_and_time = meeting_date['LastModified'] # 議事をbedrockで処理する minutes_ja = minutes_function(transcript) # 議事録作成 result_job = create_minutes_function(date_and_time,minutes_ja) return { 'statusCode': 200, 'body': "議事録を作成しました。" } except Exception as e: return { 'statusCode': 500, 'body': str(e) } def minutes_function(transcript): try: prompt = f"""会議の記録です:{transcript}:上記の記録から以下の項目を含む議事録をMarkdown記法で作成してください。「参加者」「会議テーマ」「決定事項」「懸念事項」。""" body = json.dumps({ "inputText": prompt, "textGenerationConfig": { "maxTokenCount": 1000, "temperature": 0.7, "topP": 0.9 } }) response = bedrock_client.invoke_model( body=body, contentType='application/json', accept='application/json', modelId='amazon.titan-text-express-v1' ) response_body = json.loads(response.get("body").read()) minutes = response_body['results'][0]['outputText'] return minutes except Exception as e: return { 'statusCode': 500, 'body': str(e) } # 議事録作成 def create_minutes_function(date_and_time,contents): # 文章整形 symbols = [":", ":"] headlines = ["参加者", "会議テーマ", "決定事項", "懸念事項"] for symbol in symbols: contents = contents.replace(symbol, f"{symbol}\n") for headline in headlines: if headline in contents: contents = contents.replace(headline, f"## {headline}") content = f""" # 議事録 ## 日時: {date_and_time} {contents} """ # ファイルの作成とアップロード file_name = 'minutes/minutes-test.md' markdown_encode = content.encode(encode) s3_client.put_object(Bucket=s3_bucket, Key=file_name, Body=markdown_encode) |
使うサービスが少なくなったことで、コード自体が前回よりも格段に短くなりました。大きな違いは、やはり Bedrock を用いるようにした部分です。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
def minutes_function(transcript): try: prompt = f"""会議の記録です:{transcript}:上記の記録から以下の項目を含む議事録をMarkdown記法で作成してください。「参加者」「会議テーマ」「決定事項」「懸念事項」""" body = json.dumps({ "inputText": prompt, "textGenerationConfig": { "maxTokenCount": 1000, "temperature": 0.7, "topP": 0.9 } }) response = bedrock_client.invoke_model( body=body, contentType='application/json', accept='application/json', modelId='amazon.titan-text-express-v1' ) response_body = json.loads(response.get("body").read()) minutes = response_body['results'][0]['outputText'] return minutes except Exception as e: return { 'statusCode': 500, 'body': str(e) } |
body
Bedrock に指示を送信するため、Json形式で推論パラメータを含んだデータを作成します。
- inputText
- Bedrock へ送信する内容です。指示の内容を記載します。
- maxTokenCount
- レスポンスで生成されるトークンの最大値です。デフォルトは 512 ですが、今回は 1000 にしています。使用するモデルにより、最大値が異なります。
- temperature
- 低くすると予測が安定し、温度を高くするとより多様でランダムなレスポンスが生成されます。今回はデフォルト値です。
- topP
- 「次に来るトークンの選択肢の幅」を調整することができ、小さい値でより狭い範囲から選び、大きい値でより広い範囲から選ぶことができます。今回はデフォルト値です。
response
Bedrock にデータを送信します。接続には Boto3 のクライアントを使用します。
公式ページはこちらです。
- body
- 本文です。内容には推論パラメータを含んでいる必要があります
- contentType
- リクエストに使用する MIMEタイプです。今回は JSON を指定しています。
- accept
- レスポンスに使用される MINEタイプです。今回は JSON を使用しています。
- modelId
- 使用するモデル ID です。アカウント内で有効になっているもののみ使用できます。現在は下記三種類です。
- amazon.titan-text-express-v1
- amazon.titan-text-lite-v1
- amazon.titan-text-premier-v1
- 使用するモデル ID です。アカウント内で有効になっているもののみ使用できます。現在は下記三種類です。
諸々の項目を決め打ちで設定していた前回とは異なり、生成系AI を都度呼び出すため、レスポンスは一定ではありません。一例ですが、以下のような議事録を作成することができます。
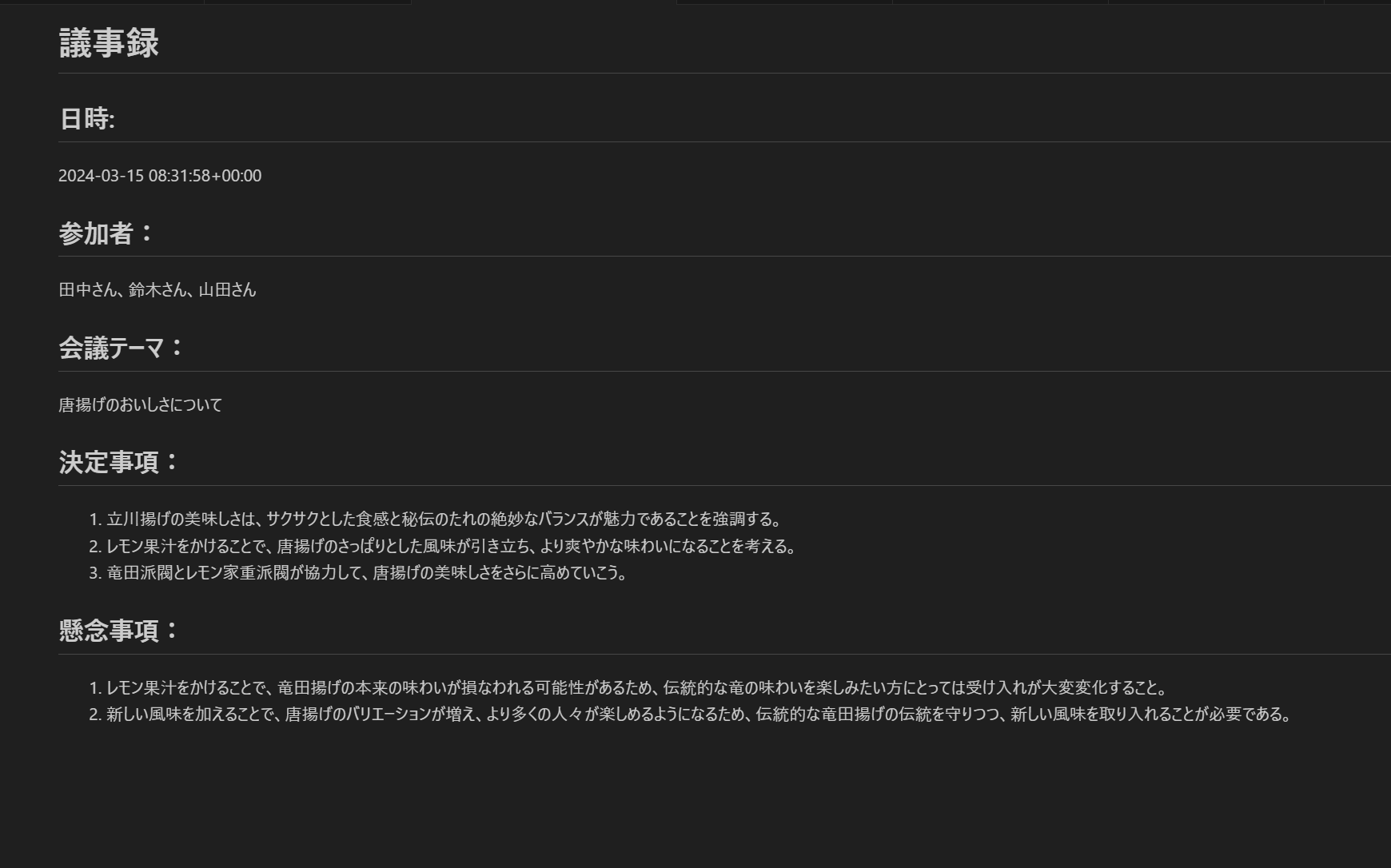
前回のものと比べてみます。
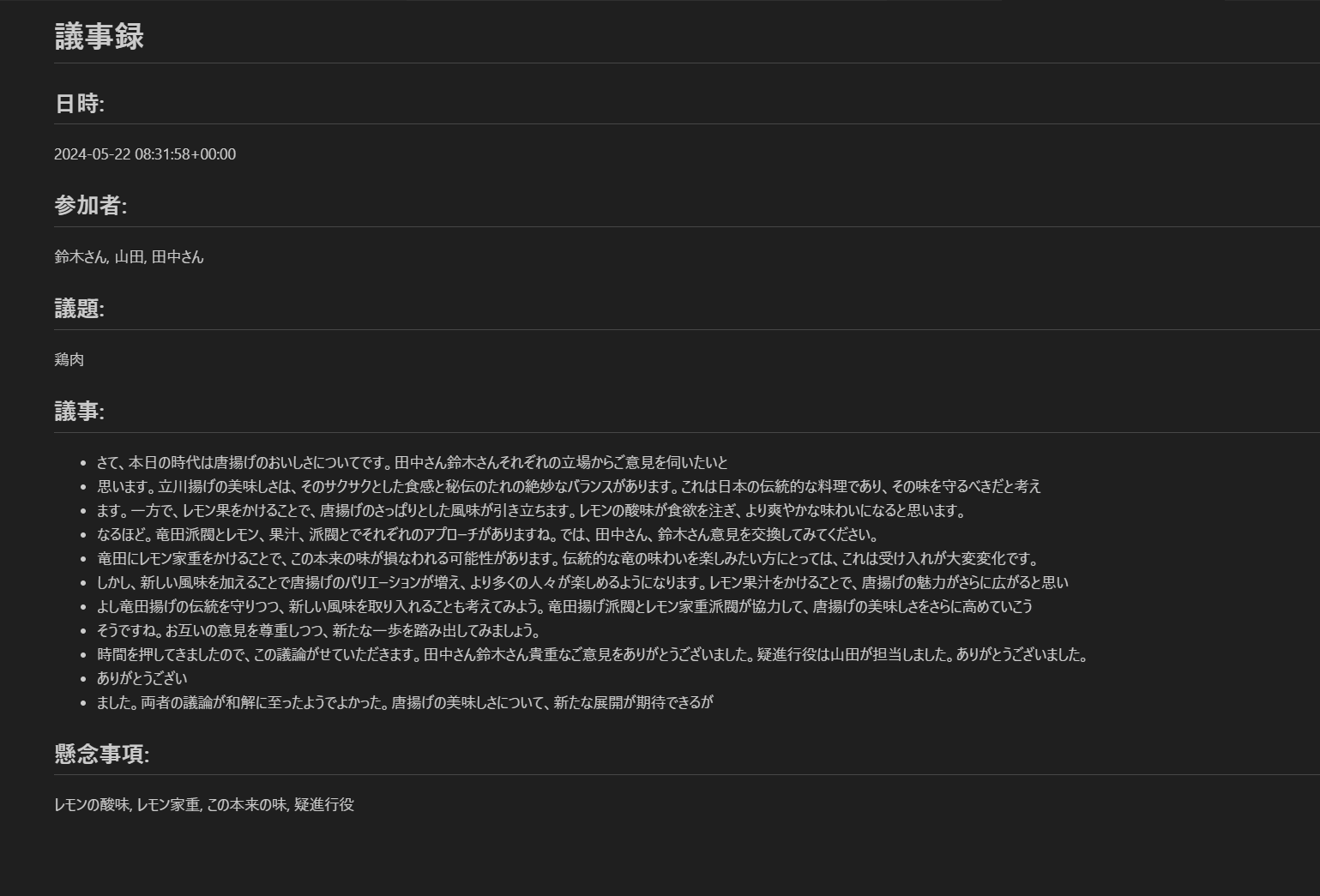
前回の投稿で載せ忘れてしまいましたが、AWS Transcribe で会議音声をもとに生成された文章がこちらです。
|
1 |
さて、本日の時代は唐揚げのおいしさについてです。田中さん鈴木さんそれぞれの立場からご意見を伺いたいと思います。立川揚げの美味しさは、そのサクサクとした食感と秘伝のたれの絶妙なバランスがあります。これは日本の伝統的な料理であり、その味を守るべきだと考えます。一方で、レモン果をかけることで、唐揚げのさっぱりとした風味が引き立ちます。レモンの酸味が食欲を注ぎ、より爽やかな味わいになると思います。なるほど。竜田派閥とレモン、果汁、派閥とでそれぞれのアプローチがありますね。では、田中さん、鈴木さん意見を交換してみてください。竜田にレモン家重をかけることで、この本来の味が損なわれる可能性があります。伝統的な竜の味わいを楽しみたい方にとっては、これは受け入れが大変変化です。しかし、新しい風味を加えることで唐揚げのバリエーションが増え、より多くの人々が楽しめるようになります。レモン果汁をかけることで、唐揚げの魅力がさらに広がると思いよし竜田揚げの伝統を守りつつ、新しい風味を取り入れることも考えてみよう。竜田揚げ派閥とレモン家重派閥が協力して、唐揚げの美味しさをさらに高めていこうそうですね。お互いの意見を尊重しつつ、新たな一歩を踏み出してみましょう。時間を押してきましたので、この議論がせていただきます。田中さん鈴木さん貴重なご意見をありがとうございました。疑進行役は山田が担当しました。ありがとうございました。ありがとうございました。両者の議論が和解に至ったようでよかった。唐揚げの美味しさについて、新たな展開が期待できるが |
議事録を見比べてみると、今回作成したものは要点のみがまとまっており、より議事録っぽくなったのではないでしょうか。
コストについて
前回と今回で、関数の実行にかかるコストを計算してみます。
条件は以下です。
- 実行するのは東京リージョン
- Lambda 以外の無料利用枠は含まない
料金は各サービスの公式ページを参考にしています。
共通部分
- AWS Transcribe
- 1 分ごとに 0.02400USD
- ジョブの実行時間は2分ほどだったので 2 × 0.02400 = 0.048USD
前回の関数
- Amazon Translate
- 1 文字につき 0.000015USD
- 今回は 662 文字だったので 662 × 0.000015 = 0.00993
- 関数内で 2 回使用しているので 0.00993 × 2 = 0.01986USD
- Amazon Comprehend
- 100 文字を 1 ユニットとして計算され、各リクエストにつき 3 ユニット (300 文字) の最低料金が発生する
- 662 文字なので 7 ユニット分の料金がかかる
- 構文解析、エンティティ認識、キーフレーズ抽出、感情分析を使用しているため、それぞれの料金を足す
- 7×(0.00005+0.0001+0.0001+0.0001) = 0.00245
合計:0.07031 USD
今回の関数
- Amazon Bedrock
- 使用しているのは Titan Express
- 入力トークンが 734 ほど
- トークン 1000 個あたり 0.000275USD なので 734 / 1000 = 0.734
- 0.734 × 0.000275 = 0.00020185
- 出力トークンは実行のたび変わるが平均して 400 ほど
- トークン 1000 個あたり 0.000825USD なので400 / 1000 = 0.40
- 0.40 × 0.000825 = 0.00033
-
0.00020185 + 0.00033 = 0.00053185
合計:0.04853185 USD
今回は会議音声や議事録自体も短いのでどちらも 1 ドル未満の結果でしたが、今回改修した関数を使用した方が若干コストがかからないということがわかりました。
まとめ
Amazon Bedrock は手軽に生成系 AI へ触れられるサービスですが、いざ使ってみようと思うと中々手を出しにくい存在なのではないかなと思っています。アプリに組み込んでみたり、今回のようにSDKを通して利用することで、より身近なサービスになるのではないかなと思います。
最後まで目を通していただきありがとうございました。
投稿者プロフィール
- AWS の諸々について、初学者目線から書いていけたらいいなと思っています!