はじめに
Amazon Bedrock を使って何かしたいなあ、と常日頃考えていたので、簡単なAIカクテルメーカーを作って遊んでみました。せっかくなのでその記録を記事にします。
できたもの
5年ぶりくらいに HTML を書き、自分なりに一生懸命作ったフロント画面が下記です。
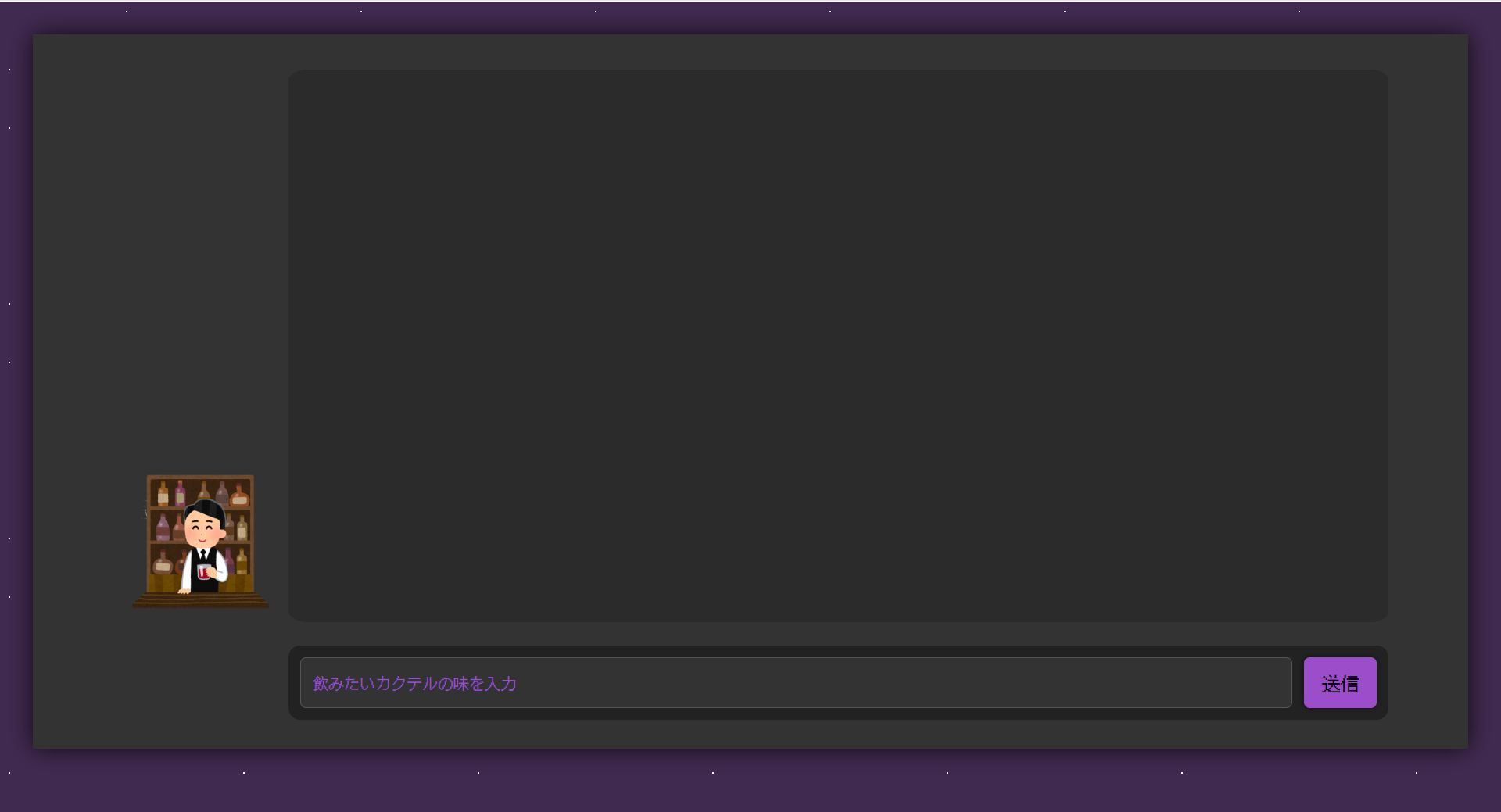
入力欄のみだとなんだか寂しかったのでいらすとやさんからバーテンダーの画像をお借りして配置しました。
表示されている通り「甘いのが飲みたい」や「アルコール強くてとにかく酔うやつがいいな」等、飲みたいカクテルの味を入力すると、Bedrock の応答が表示されます。
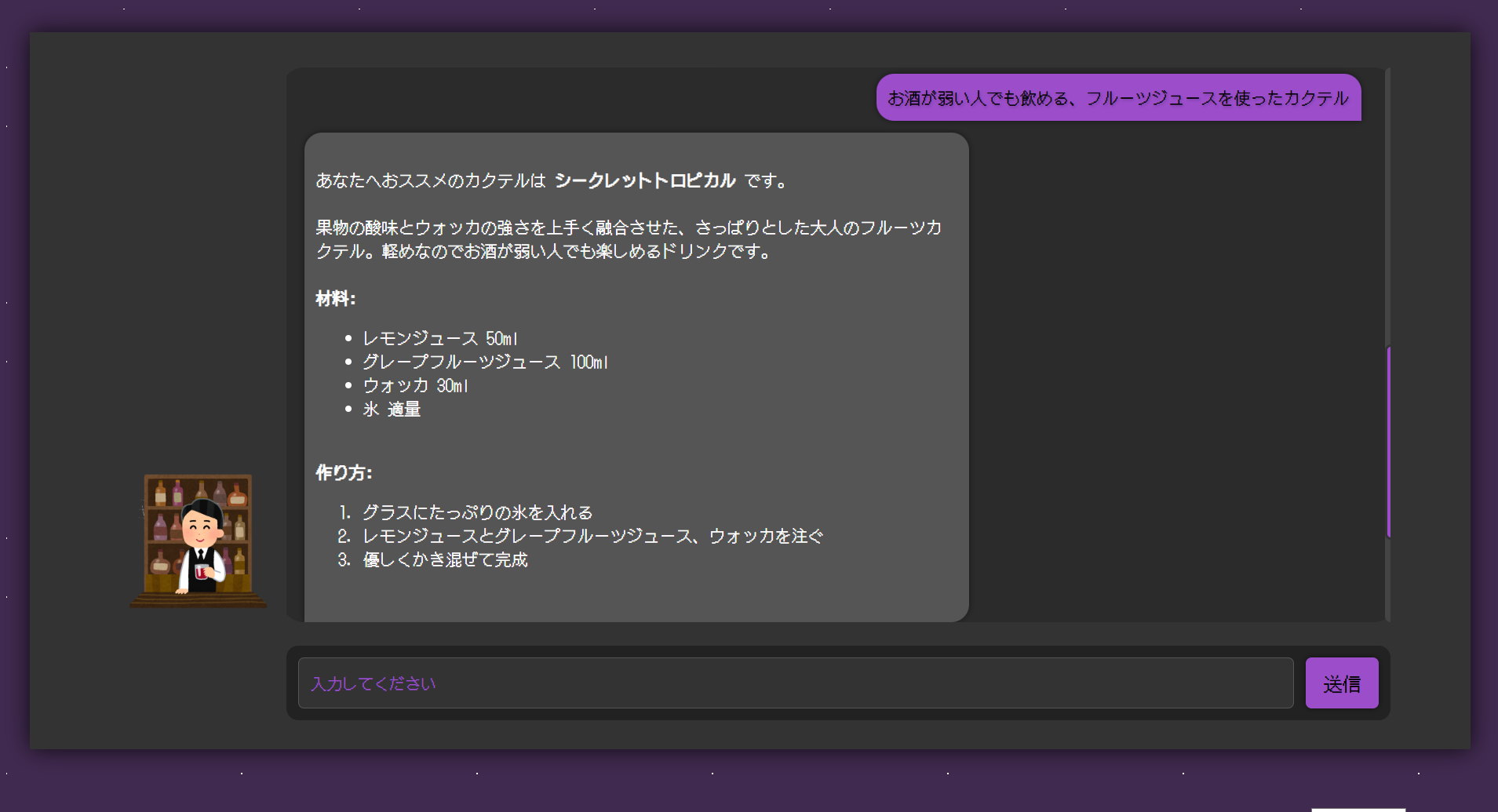
当初はただカクテルのレシピを教えてくれるだけの仕組みにする予定でしたが「それだけならわざわざ作らなくてもChatGPTだけで完結するじゃん(笑)」という声が聞こえたため、苦し紛れでレコメンド機能もどきも搭載しました。
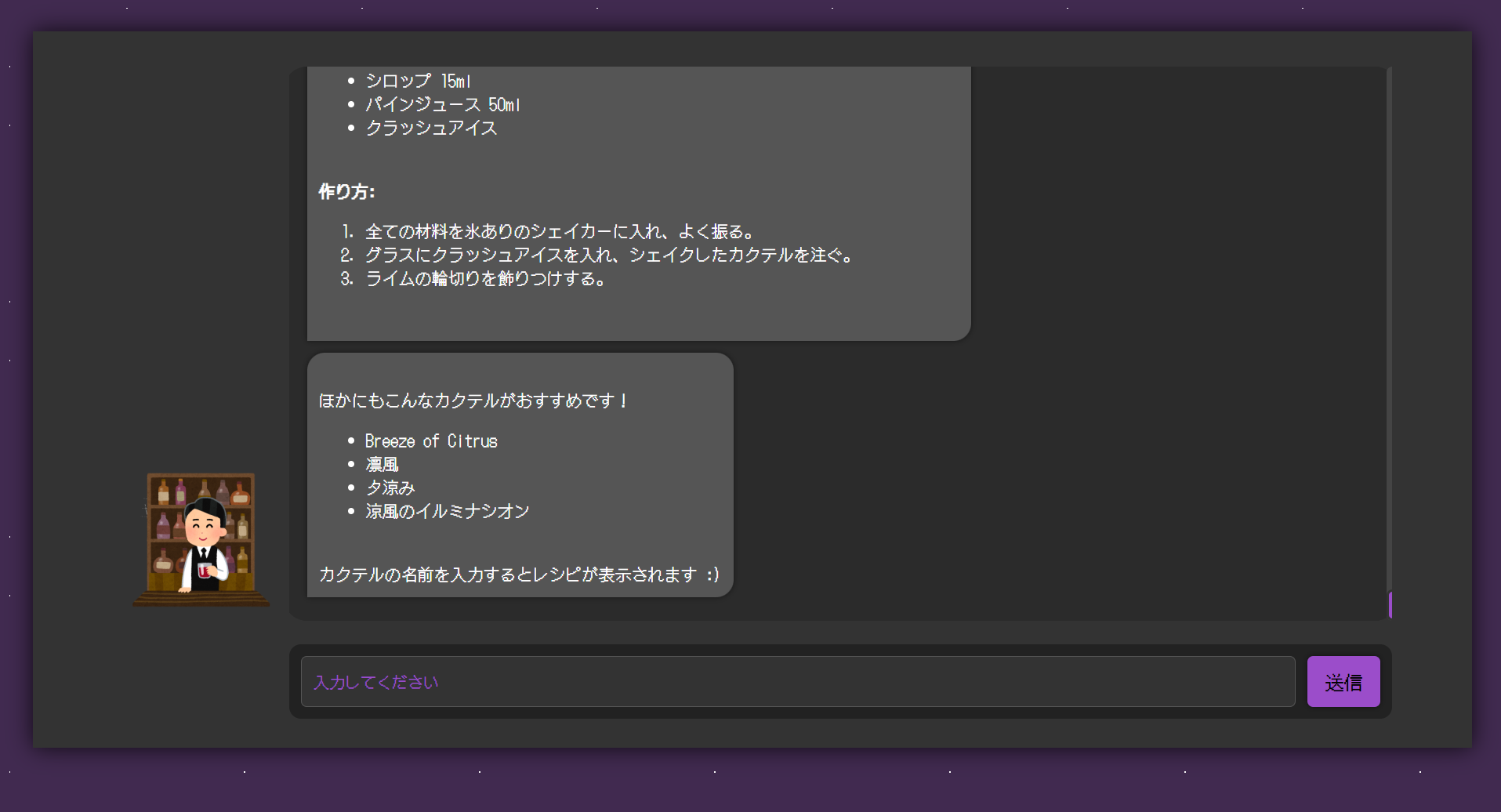
今まで生成されたカクテルのレシピを DynamoDB に保存し、その中から新たに生成されたレシピと同じ味を持つレシピを最大 5 つ表示するようになっています。
カクテル名を入力すると、そのカクテルのレシピが表示されます。
構成
とてもシンプルですが、構成図です。
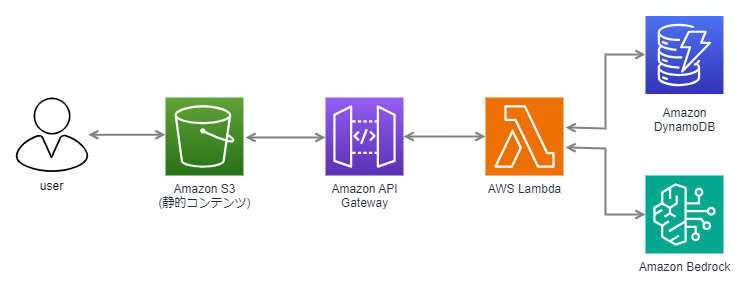
以下、それぞれのサービスの使用用途について説明します。
Amazon S3
静的コンテンツ配置用です。最低限の HTML と CSS が配置されています。
AWS Amplify の使用も考えたのですが、アプリの規模がそこまで大きくないことに加え、はやく Bedrock を触りたかったノウハウがあまりなかったため、今回は見送りました。
Amazon API Gateway
S3 に配置した静的コンテンツへの入力を Lambda へ送信するためのものです。
特別変わった設定はしていないため、内容については省略します。
AWS Lambda
受け取った入力内容を用いてプロンプトを作成し、Bedrock へ送信します。
また Bedrock の応答を DynamoDB に登録したり、ユーザー入力を基に DB 内のカクテルを検索したりします。
全体の流れは以下の通りです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
def lambda_handler(event, context): # ユーザー入力を取得 user_input = event['body'] user_input_value = ast.literal_eval(user_input) value = user_input_value['taste'] # 既存カクテルの名前なら処理終了 cocktail_recipes = get_cocktails(value) if cocktail_recipes: cocktail_recipe = cocktail_recipes[0] return generate_return(cocktail_recipe, []) # Bedrockに送信するプロンプトを作成 prompt = generate_prompt(value) body = generate_body(prompt) # Bedrock呼び出し bedrock_response = bedrock.invoke_model( modelId='anthropic.claude-3-haiku-20240307-v1:0', contentType='application/json', accept='application/json', body=body ) # レスポンスをJSON形式に変換 response_body = bedrock_response['body'].read() response_data = json.loads(response_body) # Bedrockの応答を出力 cocktail_recipes = response_data['content'][0]['text'] # JSONを辞書に変換しDynamoDBに登録 recipe = json.loads(cocktail_recipes) register_to_dynamodb(recipe) # 類似カクテルを取得 taste = recipe["taste"] recommendation = get_similar_cocktails(taste) # 処理終了 return generate_return(recipe,recommendation) |
関数を含んだ全文は少し長いので、要所要所抜粋して説明します。
プロンプト作成
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
def generate_prompt(user_input): prompt = f""" \n\nHuman:「{user_input}」 こちらの条件に当てはまるオリジナルカクテルを一つ考えてください。指定がない場合、必ずアルコールを含んでください。 名前(name)、材料(material)、作り方(making)、説明(summary)、味(taste)の順番にJSON形式で出力してください。 名前(name)は創作性の高い言葉を選んでください。 味(taste)は「甘い」「辛い」等の一つの単語で表してください。 材料(material)はml等の単位を付けてください。 応答は日本語で記述し、JSONのみ返してください。 材料(material)、作り方(making)は配列にしてください。 \n\nAssistant: """ return prompt |
処理を楽にするため、諸々細かく指定しています。
「指定がない場合、必ずアルコールを含んでください。」という一文は、モデルが稀に麻婆豆腐やプリンの作り方を生成したため、予防として入れています。(料理を作らないでください、という指定ではうまくいかず…)
レコメンド機能もどき
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def get_similar_cocktails(taste, max_items): try: response = table.query( IndexName="インデックスの名前", KeyConditionExpression="taste = :taste_value", ExpressionAttributeValues={":taste_value": taste}, Limit=max_items ) recommendation = response.get("Items", []) if not recommendation: print("該当するカクテルは見つかりませんでした。") return [] return recommendation except ClientError as e: print(f"エラーが発生しました: {e.response['Error']['Message']}") return [] |
名前と味だけで構成されるインデックスを参照して、ユーザー入力により新たに生成されたカクテルと同じ味を持つものがあった場合、その情報を返します。
インデックスを使用することで、DB内の総項目数が増加した場合にもスムーズに応答を返すことができます。
DynamoDB
各レシピは以下のような形式で格納されています。
レコメンド用にインデックスを作成している以外、特別な設定はしていません。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
{ "name": { "S": "夜明け前のルミナリエ" }, "making": { "L": [ { "S": "グラスにアイスを入れる" }, { "S": "ブラックスパークリングと白トマトジュースを注ぐ" }, { "S": "ライムを絞り入れ、白砂糖を加えてよく混ぜる" } ] }, "material": { "L": [ { "S": "ブラックスパークリング 150ml" }, { "S": "白トマトジュース 100ml" }, { "S": "ライム 1/2個" }, { "S": "白砂糖 大さじ1" }, { "S": "アイス 適量" } ] }, "summary": { "S": "夜明け前の街を照らす白い光をイメージしたカクテル。トマトジュースとスパークリングの相性が良く、ライムの爽やかな香りが全体を引き締める。" }, "taste": { "S": "爽やか" } } |
Bedrock
ユーザーの入力に基づきオリジナルカクテルのレシピを作成します。
モデルは Claude 3 Haiku を使用しました。
https://aws.amazon.com/jp/blogs/news/anthropics-claude-3-haiku-model-is-now-available-in-amazon-bedrock/
Claudeを触ってみたかったという私情を除くと、以下ふたつの理由から選んでいます。
コストがいい感じ
コストが安価の為「こんなに入力して…いったい月末にいくらの請求が…」と罪悪感におびえることなく使いやすいです。Claudeの他のモデルと比較するとわかりやすいかなと思います。
| モデル名 | 入力トークン 1,000 個あたりの価格 | 1,000 出力トークンあたりの料金 |
|---|---|---|
| Claude Instant | 0.0008 USD | 0.0024 USD |
| Claude 2.0/2.1 | 0.008 USD | 0.024 USD |
| Claude 3 Haiku | 0.00025 USD | 0.00125 USD |
| Claude 3.5 Sonnet | 0.003 USD | 0.015 USD |
引用元:https://aws.amazon.com/jp/bedrock/pricing/
精度というか、文章の奥行でいえばやはりClaude 3.5 Sonnetの方が若干上回るかな…という感じですが、今回のように応答が短文で済む場合には気にならない範囲でした。
クォータの問題
Amazon Bedrock には、他サービスと同じようにサービスクォータが設けられています。
その中にモデルごとのOn-demand InvokeModel requests per minute for {モデル名}という項目があります。これは、一分間にそのモデルを呼び出すことができるリクエスト数の最大値です。
私の持っている環境では初期値から特に手を加えていなかったため、以下の通りになっていました。
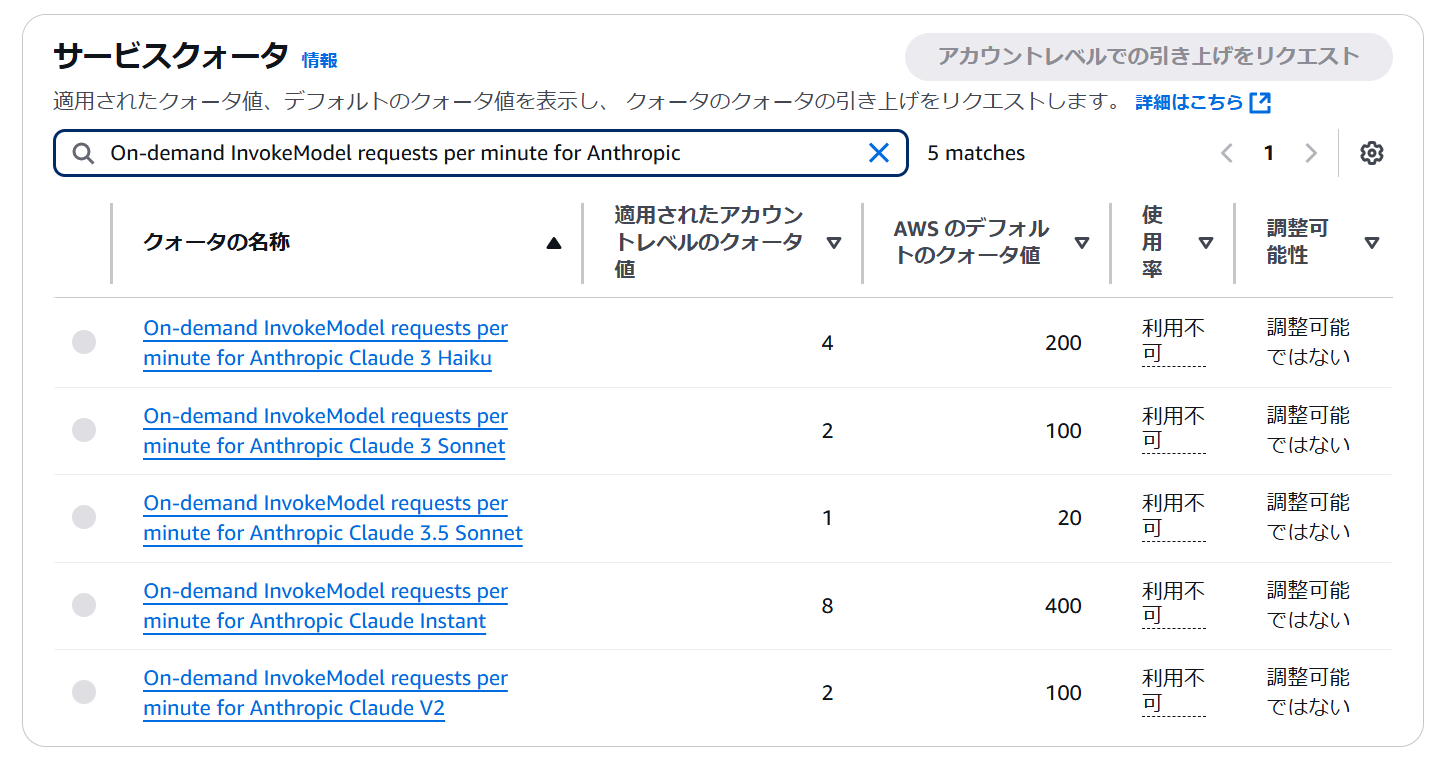
さすがに分間1リクエストだと動作確認の時点でエラーが出てしまいましたが、自分一人で楽しむ分には4リクエストもあれば十分でした。
まとめ
勉強もかねて何か作ってみたいなーと軽い気持ちで始めたことですが、長らく関わりのなかったAmazon API Gateway等のサービスへ久しぶりに触れることができて良い勉強になりました。(コンソールが変わりすぎていてびっくりしました。)
皆様もぜひAmazon Bedrockで遊んでみてください。
最後まで目を通していただきありがとうございました。
おまけ
せっかくなので、Bedrockが提案してくれたカクテル(ノンアルコール)を作って飲んでみました。
その名もドラゴンズアイ
レシピがこちらです。
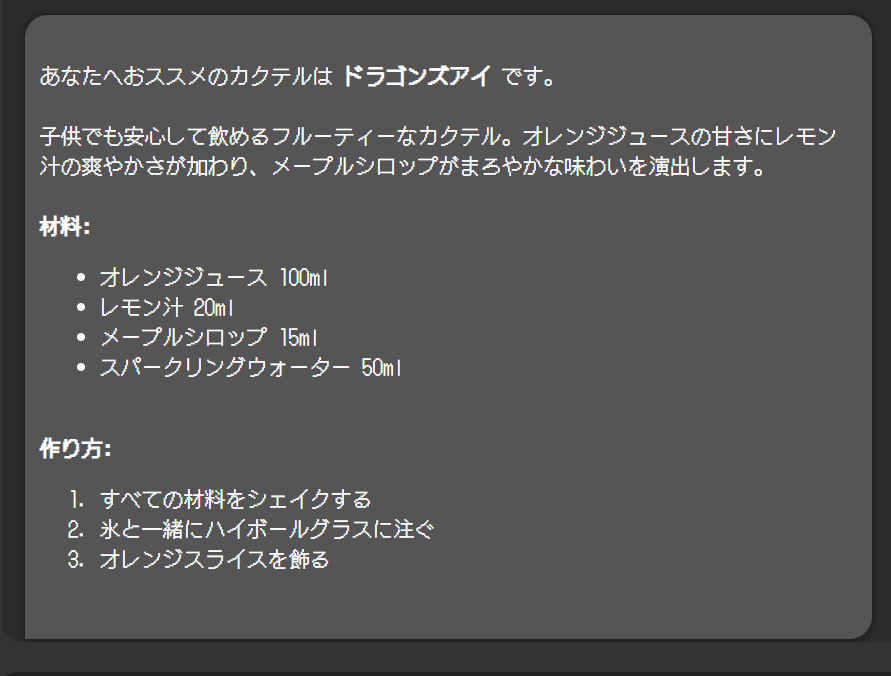
オレンジスライスは用意できませんでしたが、それ以外は分量を含め完璧レシピ通りに作りました。

感想
ビールみたいな見た目に反し、とてもおいしいオレンジジュースでした。レモンのすっぱさとシロップがジュース本来の味を濃くしてくれている気がします。これが「ドラゴンズアイ」か…と思いながら浸らせていただきました。
実際に作ってみることで、AIが生成しているのは適当な回答ではなく、おいしく飲めるレシピであるという検証ができて良かったです。
投稿者プロフィール
- AWS の諸々について、初学者目線から書いていけたらいいなと思っています!