AWS re:Invent 2022にて発表された、Amazon OpenSearch Serverless プレビュー版を利用しPythonスクリプトでのデータ投入、OpenSearch UIでの検索を試してみました。
続々と増える「Serverless」をサービス名に入れたよりスケーラビリティが高く、マネージド領域の広いサービス、今年中頃のAuroraServerless v2も好感触でしたので、期待を込めて触ってみました。
目次
はじめに
下記2本立てでお送りします
- Amazon OpenSearch Serverless(プレビュー) にPythonスクリプトからデータ投入をしてみました (本記事)
- Amazon OpenSearch Serverless(プレビュー) からPythonスクリプトでデータ取得をしてみました
今回のプレビュー版利用にあたり参考にした/利用したものは下記となります。
内部アーキテクチャ図含む全容の参考
- Getting started with Amazon OpenSearch Serverless (Workshop)
https://catalog.us-east-1.prod.workshops.aws/workshops/f8d2c175-634d-4c5d-94cb-d83bbc656c6a/en-US
Pythonからのデータ投入プログラム参考
- Amazon OpenSearch Serverless による手軽なログ分析
https://aws.amazon.com/jp/blogs/news/log-analytics-the-easy-way-with-amazon-opensearch-serverless/
投入(サンプル)データ
- 郵便番号データ
https://www.post.japanpost.jp/zipcode/download.html
前職でお世話になったデータで10年ぶり位に触れ合いましたが、変換等使い回しは以前と変わらずですねぇ...
利用準備
従来版のドメイン(クラスタみたいな概念)に当たる部分がコレクション(s)という名称になったようです。
タイプとして、時系列(TimeSeries)、全文検索(Search)を選択出来るようですが、後者を選択し、テストを簡易的に実施出来るように取り急ぎPublicで作成しました。
VPCTypeでエンドポイント経由アクセスも出来そうですね。
Amazon OpenSearch Service (Serverless) へアクセス
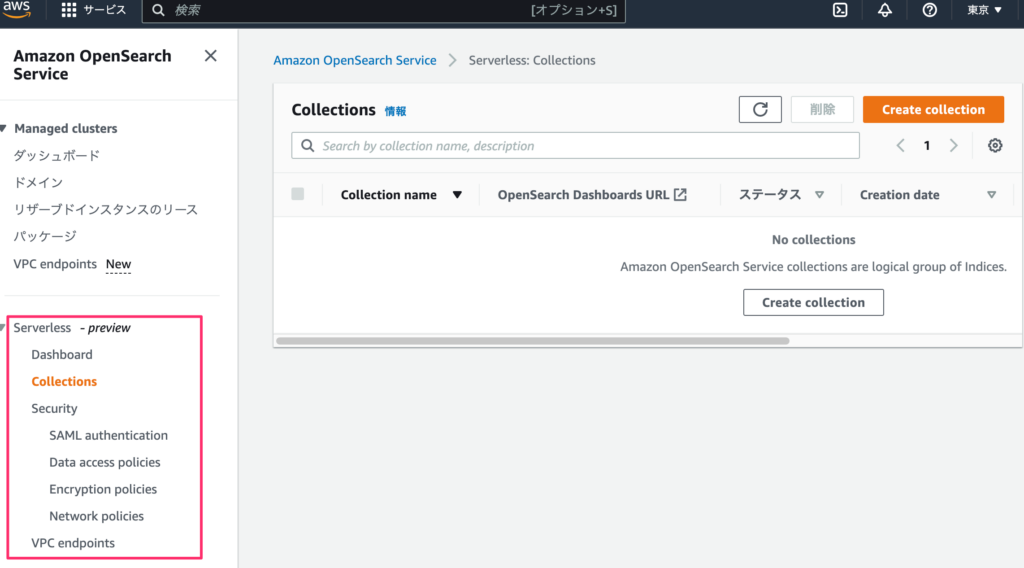
コレクションの作成
Typeとして全文検索(Search)を選択、ネットワークのアクセスタイプでPublicを選択
作成された事を確認 (作成に5分程かかりました)
アクセスポリシー設定
Security の Data Access Policiesへアクセスし、コレクションにアクセス出来るIAMユーザを設定
※こちらを実施しないと、UIにログインできてもデータ挿入・Read等操作が行えませんので要注意
今回作成したコレクション内の全てのデータへのフルアクセスを許可
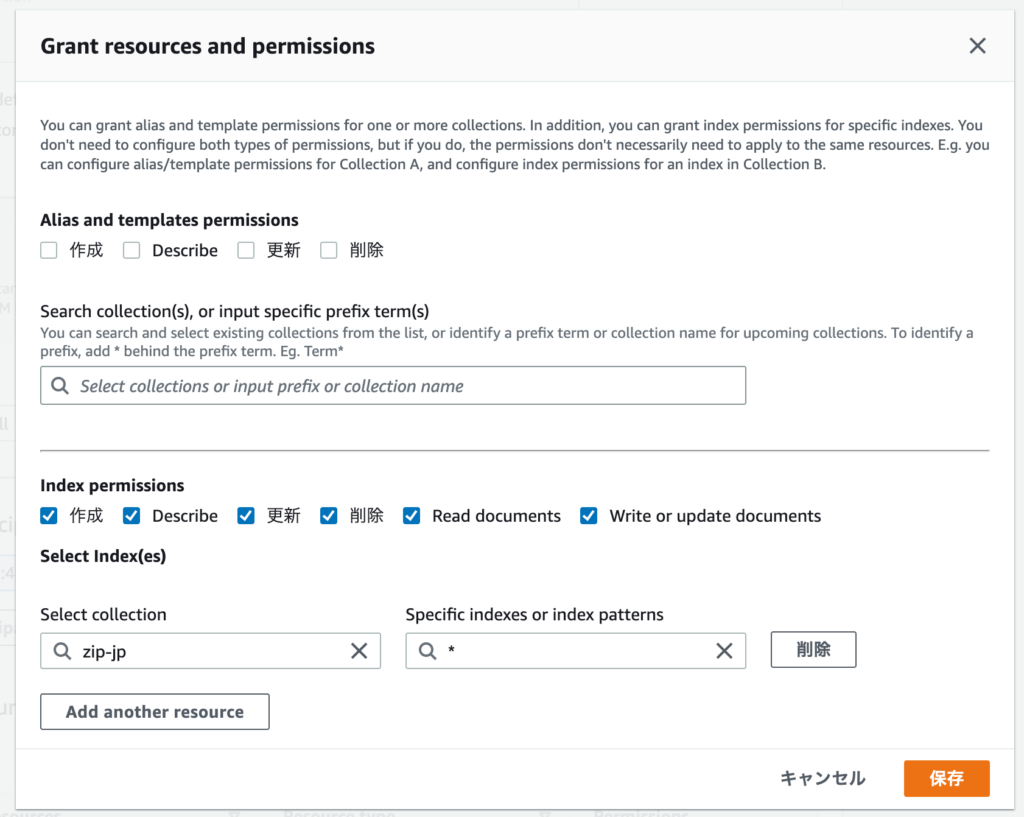
対象のIAMユーザを設定済み
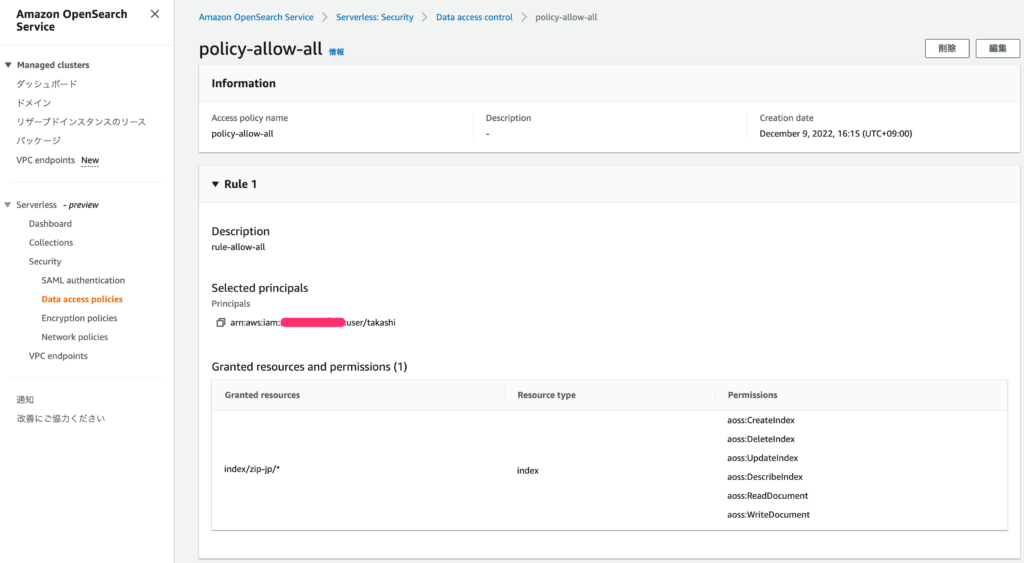
作成されたAccessPolicy
UIにアクセスしてみる
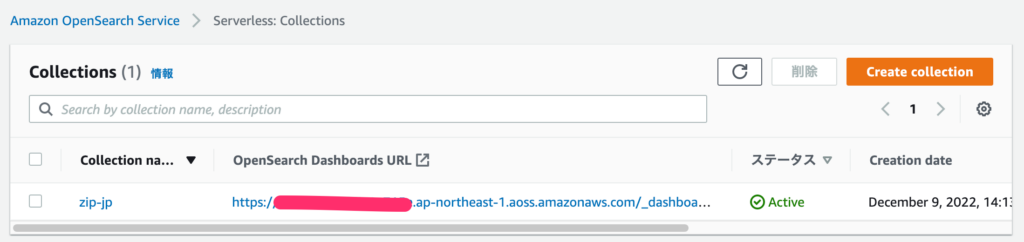
コレクション一覧画面から、ダッシュボードURLへアクセスし、アクセスポリシーで許可したユーザのIAMAccessKey/SecretKeyを利用しログインします。
コレクション一覧画面のURL記載場所 (OpenSearch Dashboards URL)
こちらのログイン認証情報で、アクセスポリシーで許可したユーザのIAMAccessKey/SecretKeyを利用します
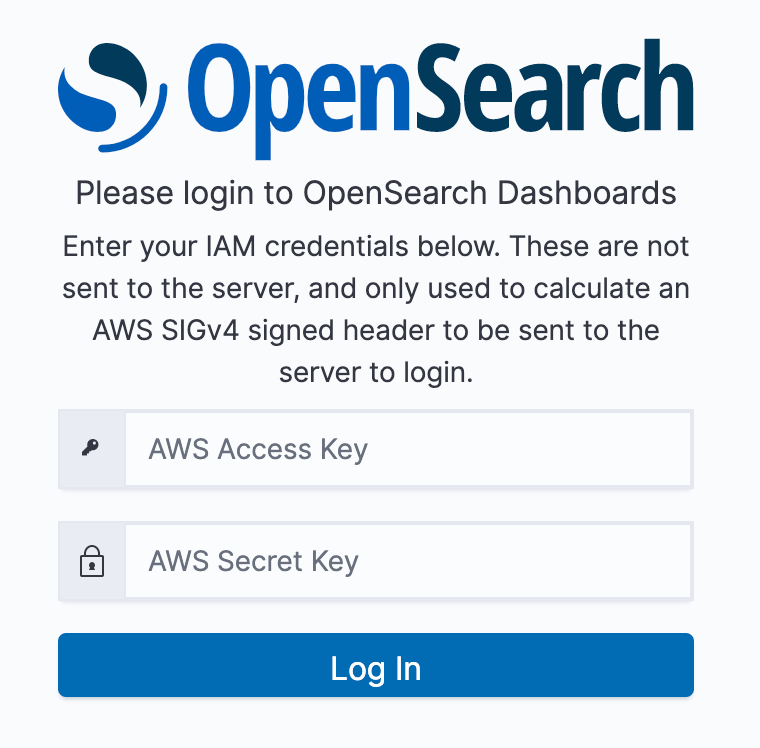
色々と機能がありそうで、サンプルデータ追加・ダッシュボード作成も出来そう(ですが、Add dataでエラーが出てしまったので試せておりません)
データ投入
下記ブログのサンプルプログラムを参考にデータ投入をしてみました。
https://aws.amazon.com/jp/blogs/news/log-analytics-the-easy-way-with-amazon-opensearch-serverless/
郵便番号データ変換&Pythonスクリプトでデータ投入
郵便番号データを入手し変換
UTF-8に変換&半角カナを全角カナに変換
|
1 2 |
$ iconv -f SHIFT_JIS -t UTF-8 KEN_ALL.CSV > KEN_ALL_UTF8.csv $ uconv KEN_ALL_UTF8.CSV -x '\p{katakana} Halfwidth-Fullwidth' -o KEN_ALL_UTF8_ZENKAKU.CSV |
Pythonスクリプトでデータ投入
認証情報はDefaultの物を利用しますので、ご注意下さい。
requirements.txt
|
1 2 3 |
opensearch-py requests_aws4auth boto3 |
import.py
from opensearchpy import OpenSearch, RequestsHttpConnection
from requests_aws4auth import AWS4Auth
import boto3
import json
import csv
host = '[作成したコレクションに応じた識別子].ap-northeast-1.aoss.amazonaws.com' # OpenSearch Serverless collection endpoint
region = 'ap-northeast-1' # e.g. us-west-2
service = 'aoss'
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, region, service,
session_token=credentials.token)
# Create an OpenSearch client
client = OpenSearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
# Specify index name
index_name = 'zip-jp-index'
# 列定義
keys = ('code', 'zip5digits', 'zip7digits','PrefKana','CityKana','TownKana','PrefName','CityName','TownName','flg0','flg1','flg2','flg3','flg4','flg5')
# CSVtoJSON
count = 0
with open('KEN_ALL_UTF8_ZENKAKU.CSV', 'r') as f:
for row in csv.DictReader(f, keys):
count=count+1
json_document = []
json_document.append(row)
# Index Documents
print(json_document[0])
response = client.index(
index = index_name,
body = json_document[0]
)
# 取り急ぎ必要な分のデータだけ送信
if count > 99:
exit()
実行結果
下記のような感じでゆるゆるとデータが入って行きます。
本来であれば、Bulkで実施すべきですが、単発リクエストでどのくらいの秒数が掛かるのか検証がてら実施してみた所、1レコード0.5秒掛かっていました。
|
1 2 3 |
$ python3.10 import.py {'code': '01101', 'zip5digits': '060 ', 'zip7digits': '0600000', 'PrefKana': 'ホッカイドウ', 'CityKana': 'サッポロシチュウオウク', 'TownKana': 'イカニケイサイガナイバアイ', 'PrefName': '北海道', 'CityName': '札幌市中央区', 'TownName': '以下に掲載がない場合', 'flg0': '0', 'flg1': '0', 'flg2': '0', 'flg3': '0', 'flg4': '0', 'flg5': '0'} ... |
Index定義
Index Patterns画面から取り込んだデータを選択してみると、Index自動生成を良い感じに実施してくれるようでした。
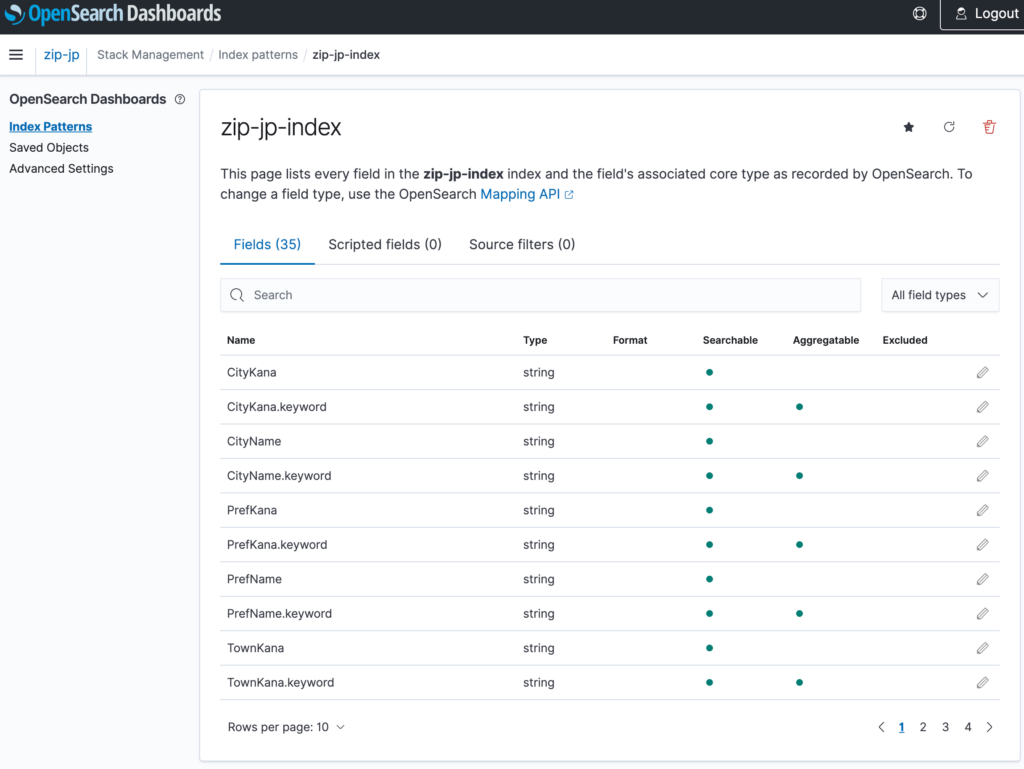
Discoverより取り込んだデータ確認ができました
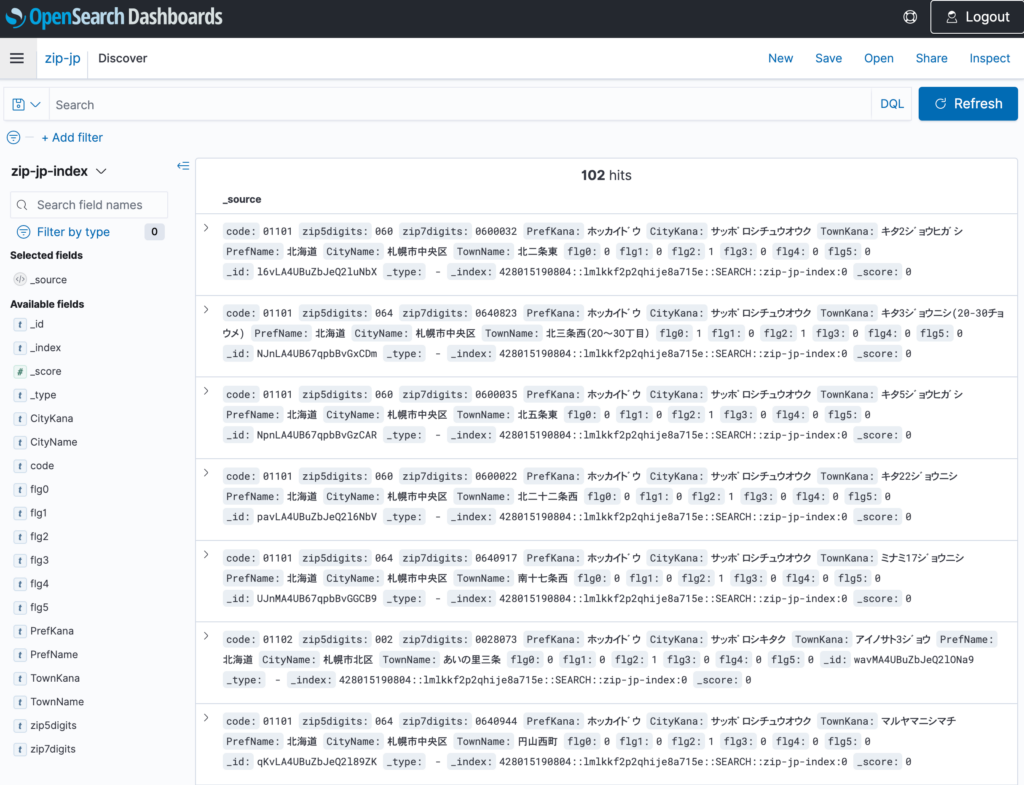
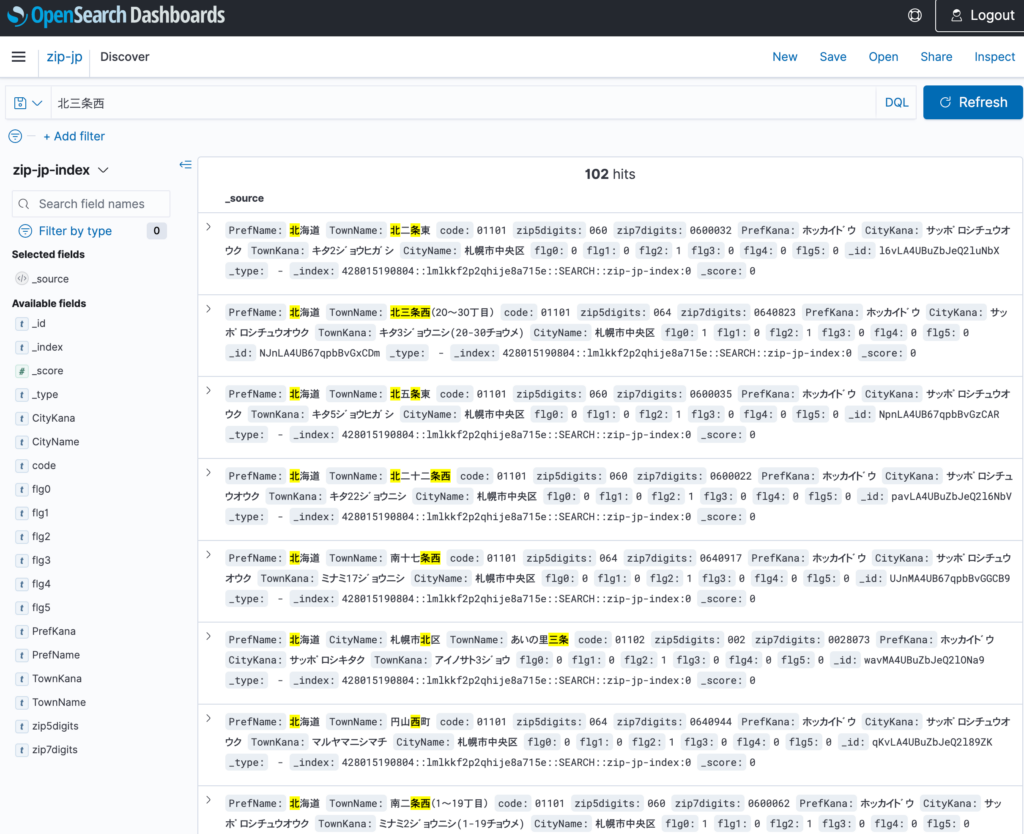
検索・クエリしてみる
上記DiscoverUIより全文検索が出来る事を確認
Dev Tools検索
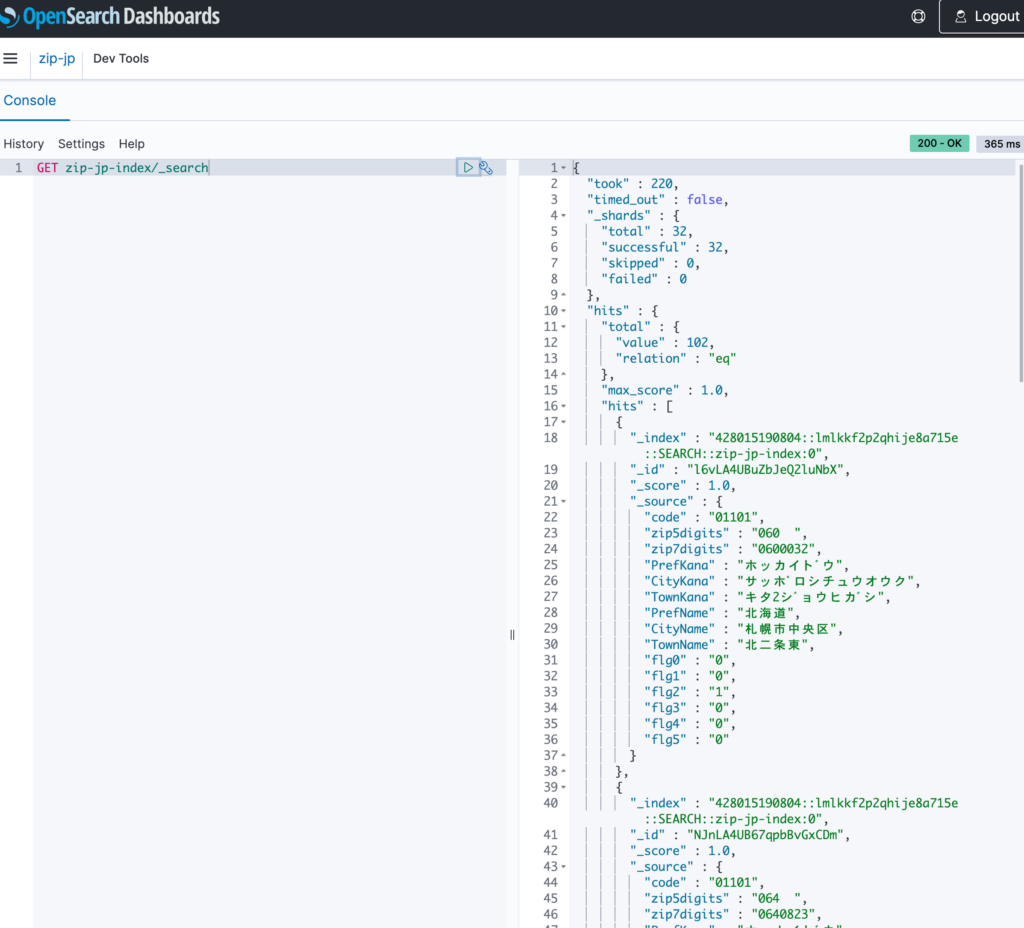
GET zip-jp-index/_search
{
"query": {
"match_all": {}
}
}
Hit件数を含め、データが表示されました。
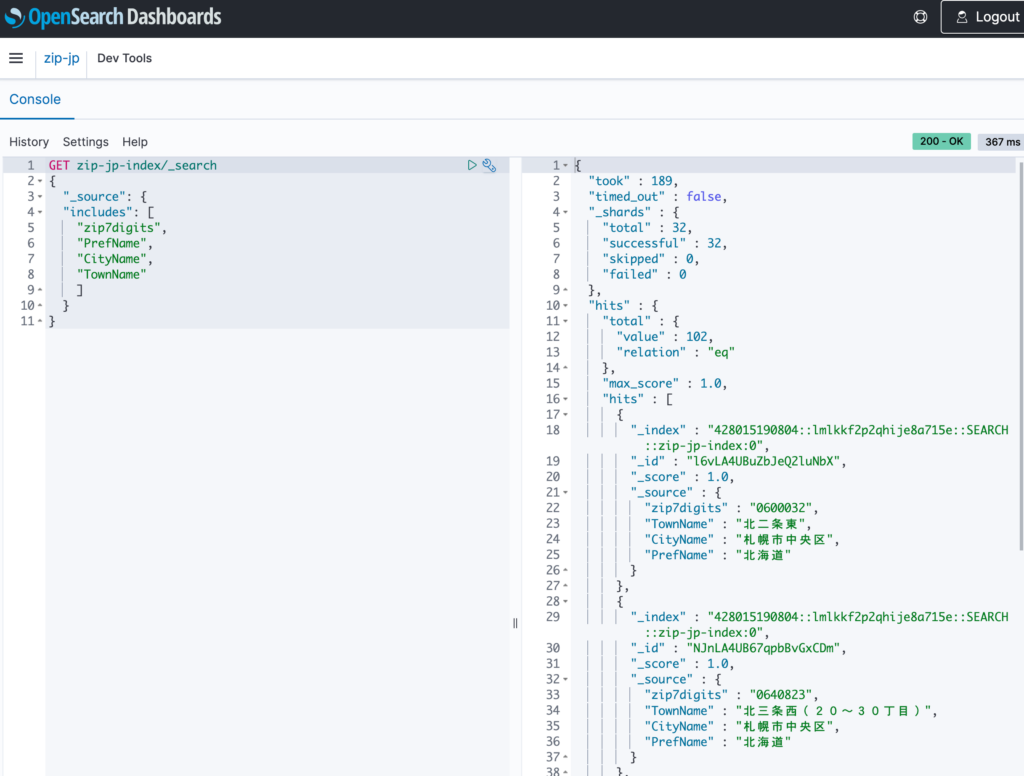
表示項目を絞り検索
GET zip-jp-index/_search
{
"_source": {
"includes": [
"zip7digits",
"PrefName",
"CityName",
"TownName"
]
}
}
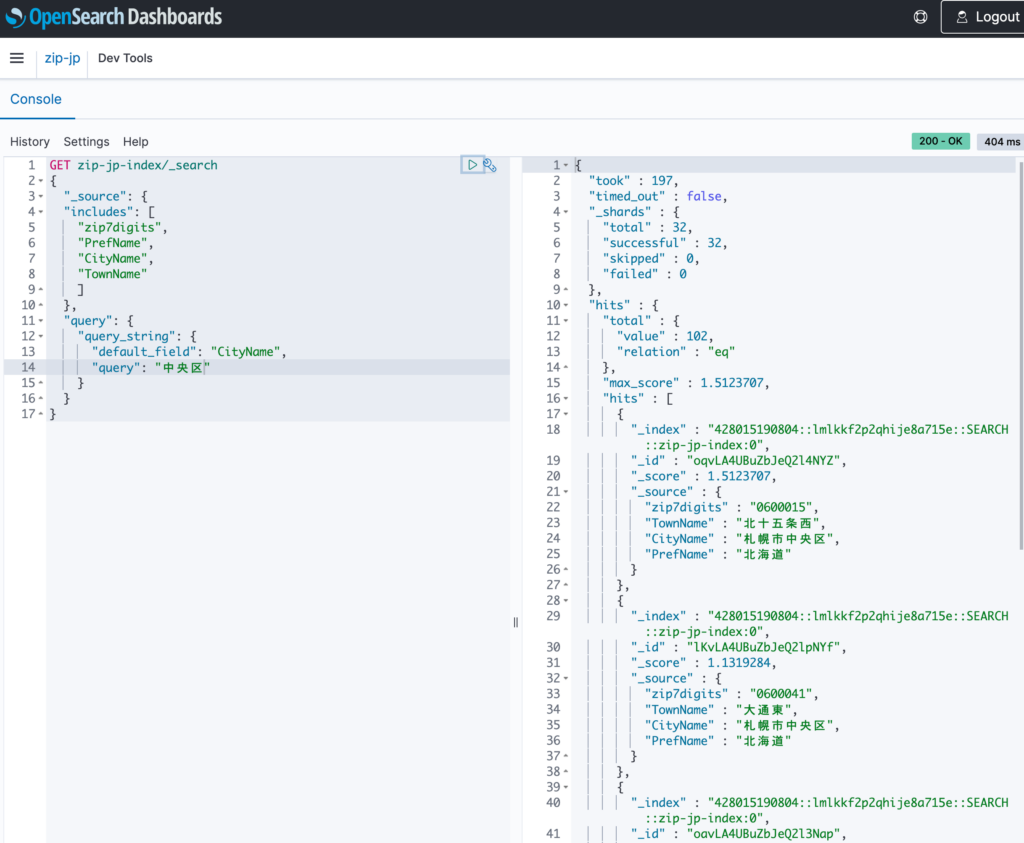
クエリを指定し検索
GET zip-jp-index/_search
{
"_source": {
"includes": [
"zip7digits",
"PrefName",
"CityName",
"TownName"
]
},
"query": {
"query_string": {
"default_field": "CityName",
"query": "中央区"
}
}
}
遭遇したトラブル
しばらく時間を置いた後にデータ投入を試すと、下記エラーに遭遇しました。
Timeoutの変更設定がすぐには見つからなかったのですが、再実行で正常にデータ投入ができました。
opensearchpy.exceptions.ConnectionTimeout: ConnectionTimeout caused by - ReadTimeout(HTTPSConnectionPool(host='xxx.ap-northeast-1.aoss.amazonaws.com', port=443): Read timed out. (read timeout=10))
その他、OpenSearch Serverlessではありませんが、下記トラブルシュートページがありました。
- Troubleshooting Amazon OpenSearch Service
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/handling-errors.html
まとめ
実際の大規模データを運用していく事が重要と考えておりますが、まだPreviewという事もあり、取り急ぎデータを貯める場所の作成、データ挿入、データ検索を試してみました。
本リソースの作成にあたり、当然ですがEC2インスタンスやS3バケット等の関連リソースは作成されていませんでした。
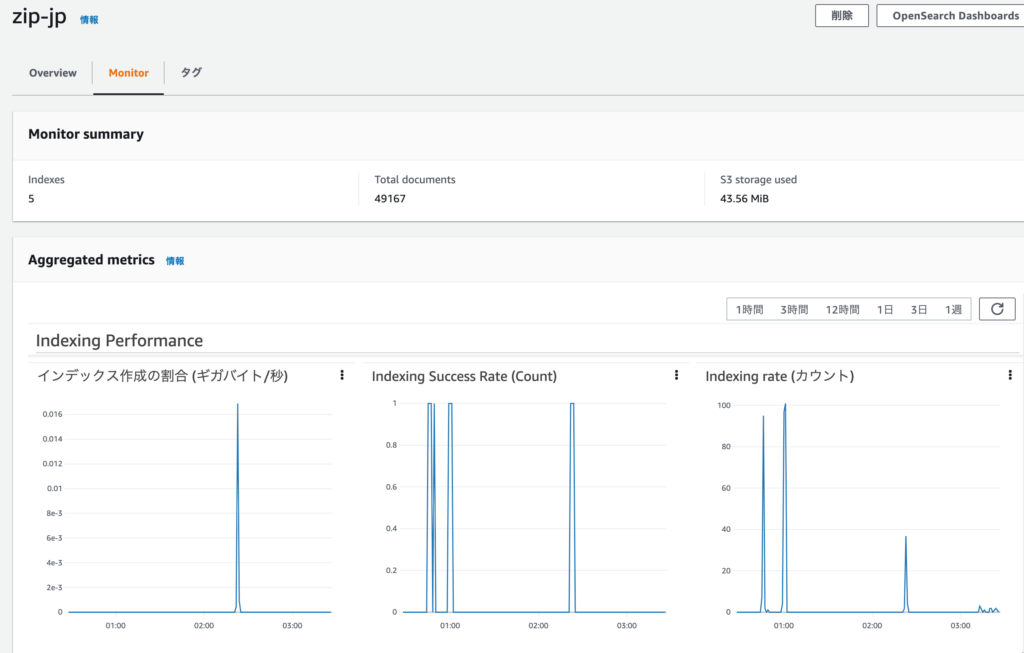
また、コレクション毎にモニタページが用意されており、ドキュメント数、データ使用量等メトリクスを見ることができました。
気軽に利用出来るフルマネージドな全文検索基盤とてもありがたいですね!
また、プレビューが取れGAになりましたら色々と試してみようと思います!!
投稿者プロフィール
-
Japan AWS Ambassadors 2023, 2024
開発会社での ASP型WEBサービス企画 / 開発 / サーバ運用 を経て
2010年よりスカイアーチネットワークスに在籍しております
機械化/効率化/システム構築を軸に人に喜んで頂ける物作りが大好きです。