はじめに
毎月行うレポート作業にて、レポート作成後の確認を行うのですが、
値確認の際に再度監視ツールへアクセスし目視確認する、という作業が地味に工数がかかっています。
今回は、Amazon Textractを使用し画像データからのテキスト抽出を試して、
これが改善案の1つとして有効かどうか検証しようと思います。
目次
Amazon Textractとは
https://aws.amazon.com/jp/textract/ より
Amazon Textract は、スキャンしたドキュメントからテキスト、手書き文字、レイアウト要素、データを自動的に抽出する機械学習 (ML) サービスです。単純な光学文字認識 (OCR) のレベルにとどまらず、ドキュメントから特定のデータを識別、理解、抽出します。今日、多くの企業は、PDF、画像、表、フォームなどのスキャンされたドキュメントから、または手動設定 (多くの場合、フォームが変更されたときに更新する必要があります) を必要とする単純な OCR ソフトウェアを介して、データを手動で抽出しています。これらのコストがかかる手動のプロセスをなくすために、Textract では機械学習を利用しています。手作業なしで、あらゆる種類のドキュメントを読み取って処理し、テキスト、手書きの文字、表などのデータを正確に抽出できます。ローン処理を自動化する場合でも、請求書や領収書から情報を抽出する場合でも、事前トレーニング済みまたはカスタム機能を使用してドキュメント処理を迅速に自動化できます。Textract では、お客様のビジネスに特有のドキュメント処理のニーズに合わせて、事前トレーニング済みの機能をカスタマイズできます。Textract は、数時間または数日ではなく数分でデータを抽出できます。
使用するうえで注意する点については、実際に使ってみて確認しようと思います。
試してみた
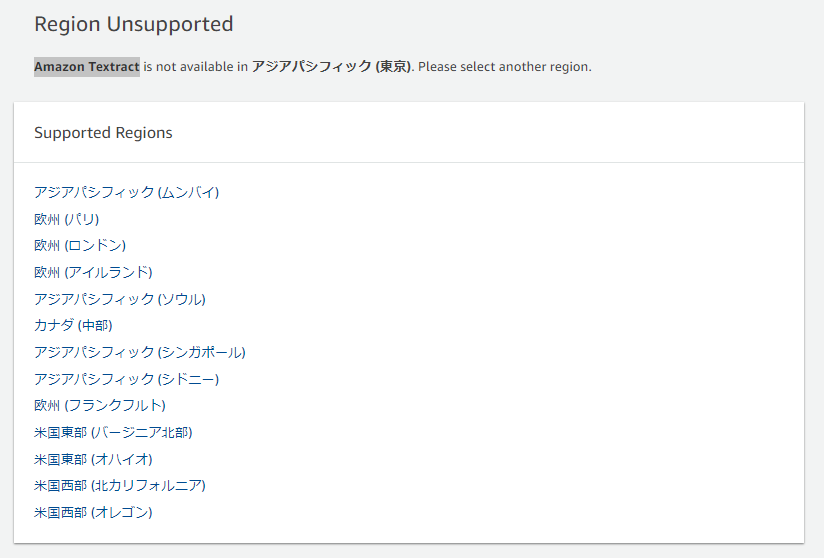
利用可能リージョンについて(2024年10月時点)
AWSコンパネよりTextractへ移動しようとしたところ、添付画像のように表示されました。
2024年10月の時点で、まだ東京リージョンでは利用可能ではないようです。
今回は、us-east-1を選択します。
文書を分析する
今回はメニューより、「文書を分析する」を選択します。
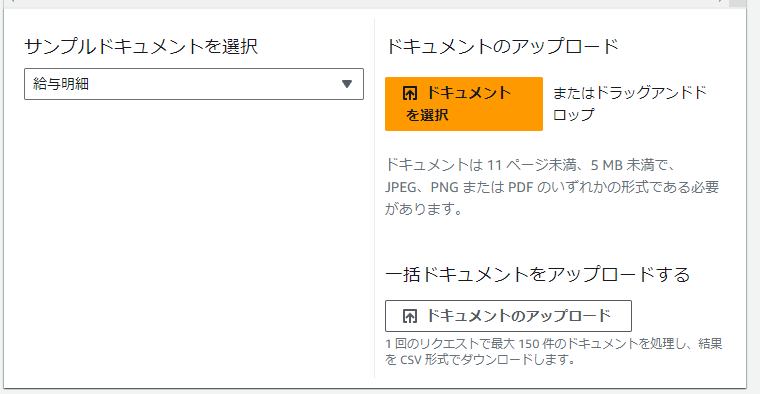
選択すると、サンプルドキュメントがアップロードされた状態で表示されます。

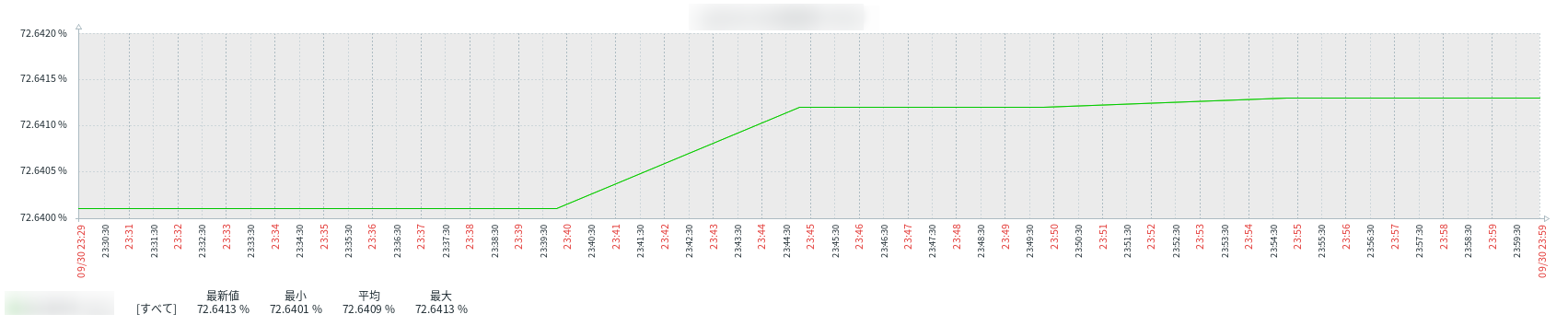
今回は下記画像ファイルを用います。(Zabbixのグラフ画像)
今回必要な値は前月の最後に取得された値なので、
期間を設定後グラフに適用し、最新値を抽出できればOKです。
画像のアップロード
では実際に画像をアップロードしていきます。
ドキュメントの内容についてですが、下記を満たす必要があるようです。
- 11 ページ未満
- 5 MB 未満
- JPEG、PNG または PDF のいずれかの形式
また、最大150件まで一括でドキュメントの処理を行うことも可能のようです。
ドキュメントを設定
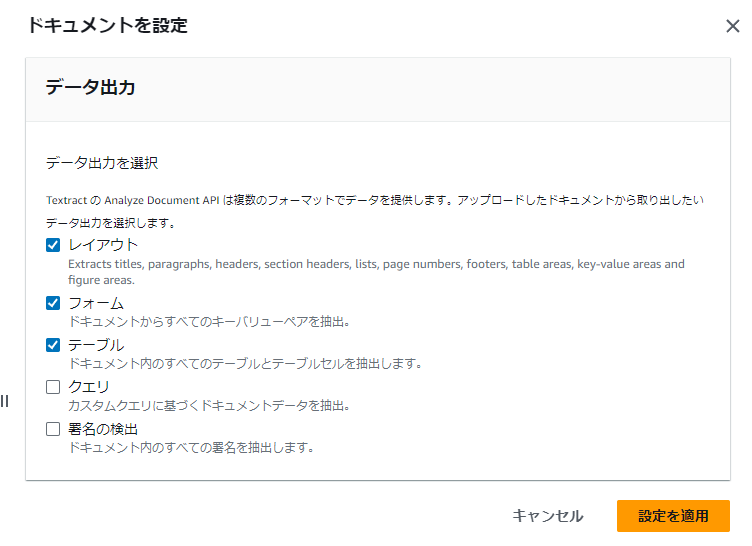
アップロード後、データ出力の選択画面が表示されます。
ここでフォーマットを選択することが可能になります。
今回は画像のように選択しています。
設定適用後
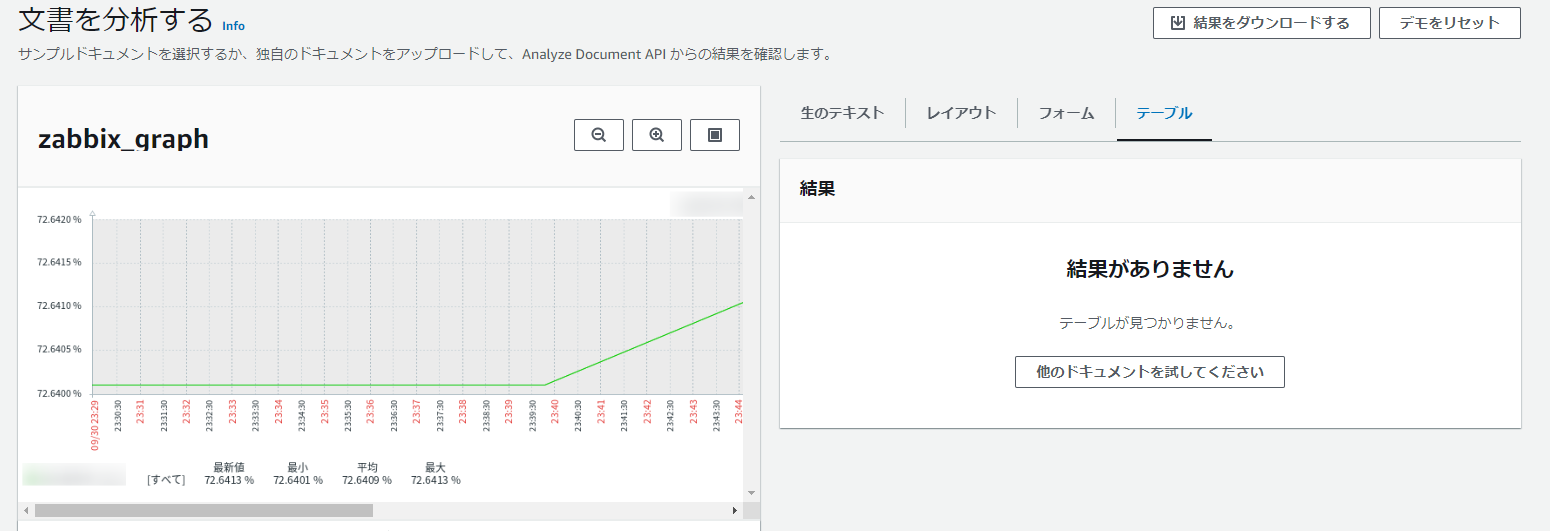
適用後、画像からのテキスト抽出が完了しましたが、
- 生のテキストはわかりにくい
- テーブルは結果が表示されない
上記結果につき、思っていたものとは違う結果となりました…
再度検証
画像の範囲が広いことが原因と思い、使用する画像を切り取って試してみることにします。

再度アップロードしてみると、今度はテーブルよりうまく抽出できていることがわかります。
値についても間違いはなさそうです。
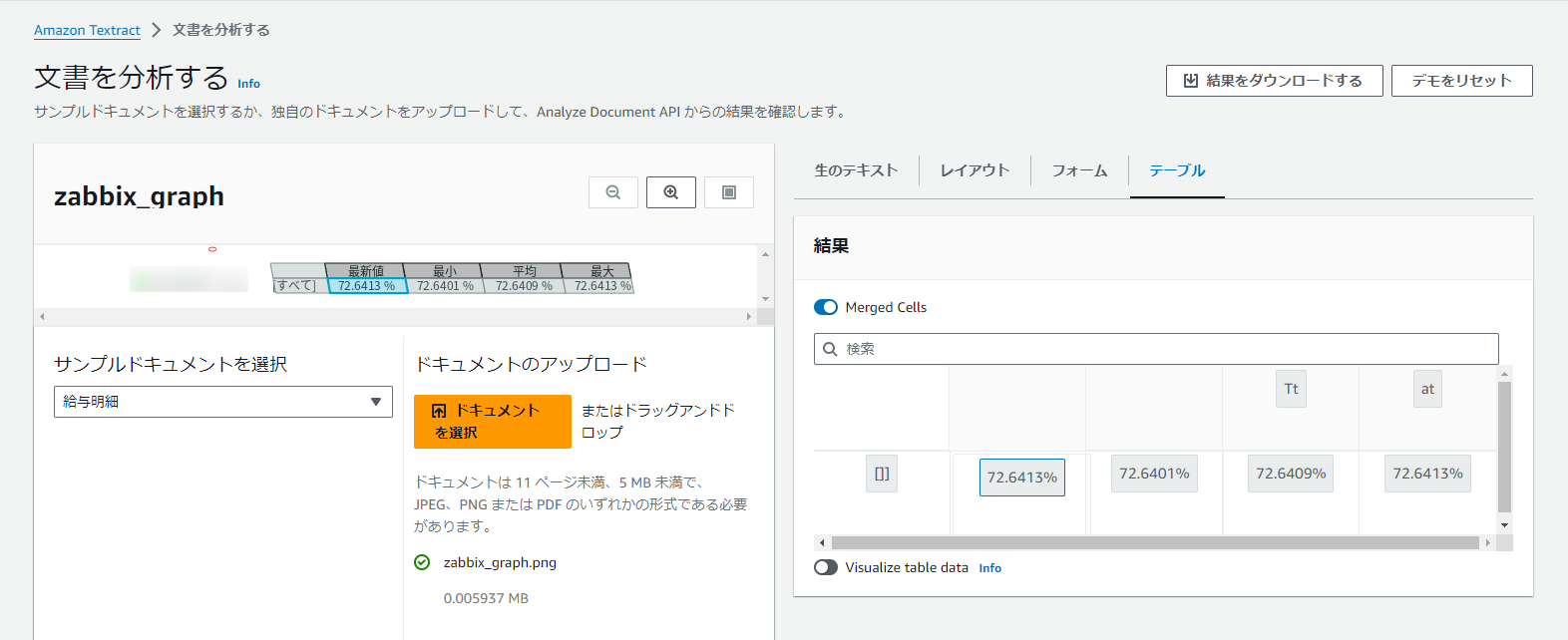
日本語に対応していないため、「最新値」という文字を認識できていないのだと思われますが、
ここで重要なのは最新値列の値が「72.6413%」であると認識している点だと思いました。
単純な文字認識とは違って、どことどこが紐づいているかを認識しているのはいい点だと感じました。
まとめ
今回簡単ではあるものの実際に触ってみて、単純作業を楽にする解決方法の1つとして使えそうなサービスだと感じました。
今回は試していないですが、カスタムクエリを用いることで
精度の高い分析が可能になるのかなと思いました。
こちらについてもまた検証してみたいと思います。
投稿者プロフィール
最新の投稿
 AIサービス2024年10月15日Amazon Textractにて画像からテキストを抽出してみた
AIサービス2024年10月15日Amazon Textractにて画像からテキストを抽出してみた




