はじめに
Amazon Transcribe と Amazon Comprehend を使用して、会議の疑似的な議事録を作成してみようと思います。
今回の検証をするにあたり、用意するものは以下の一点です。
- 会議の音声データ
- 対面でのオフライン会議であればレコーダーを用い、zoom 等オンライン会議であれば会議全体を録画して音声ファイルに変換しておきます。
次に、今回使用する各サービスの概要です。
Amazon Transcribe
AWS が提供する自動音声認識サービスです。音声を解析し、テキストデータとして出力することができます。話者ごとにラベルを設けたり、機密情報がある場合はマスキングも可能です。
Amazon Comprehend
AWS が提供する自然言語処理サービスです。構文解析やキーフレーズ抽出、言語解析や感情分析等、多様な機能を利用することができます。
手順
1. 会議の音声データを S3 へアップロードする
実際の会議の音声は使用できないので、今回は Amazon Polly というテキスト読み上げ機能を駆使し、それっぽいデータを作成しました。
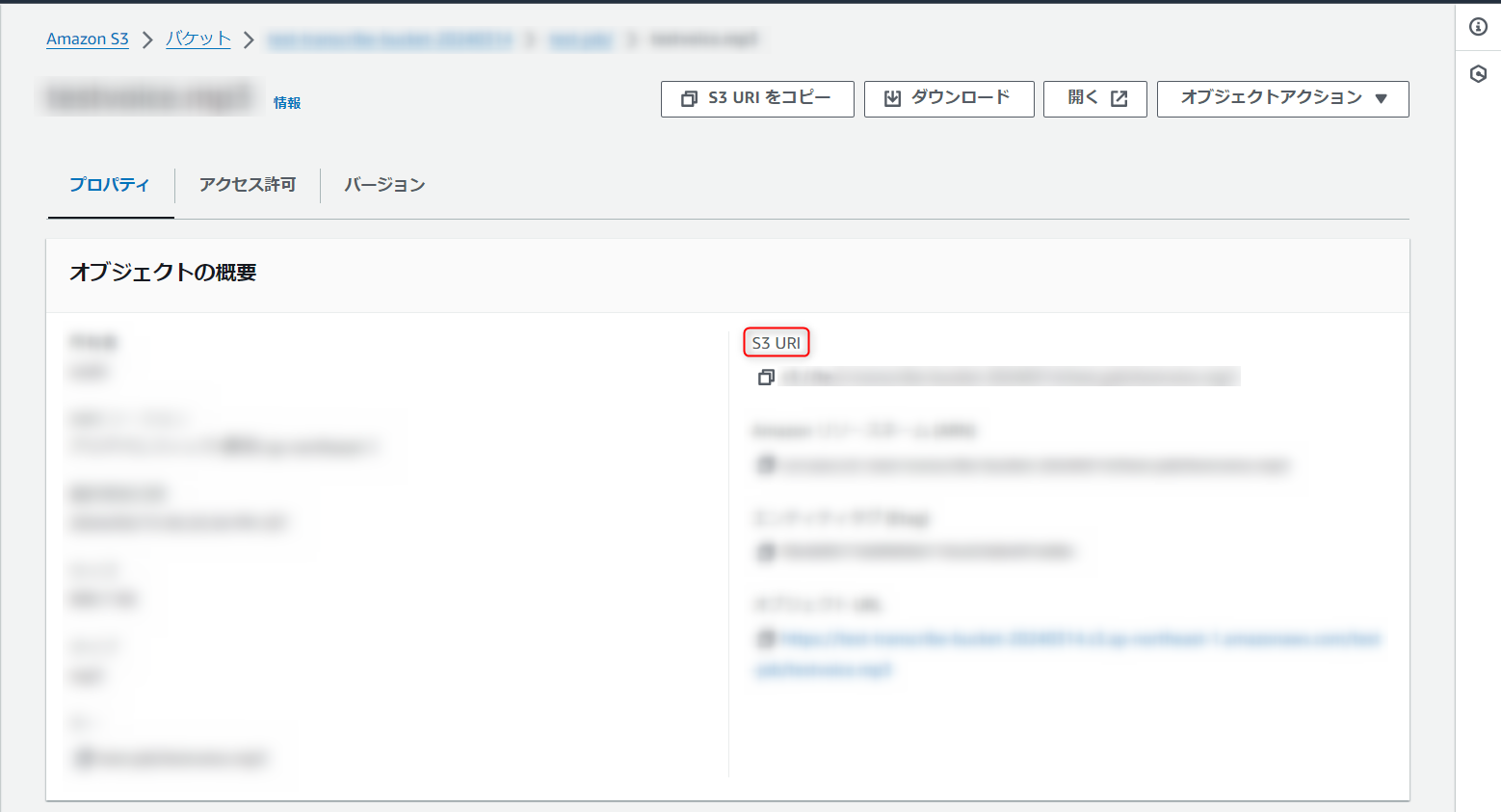
アップロード後、音声ファイルの URI は後々使うので、メモとして控えておきます。
2. Amazon Transcribe でジョブを作成する
Amazon Transcribe のコンソール画面へアクセスします。
左のメニューから「トランスクリプションジョブ」を選択し、「ジョブを作成」を押下して設定へと進みます。
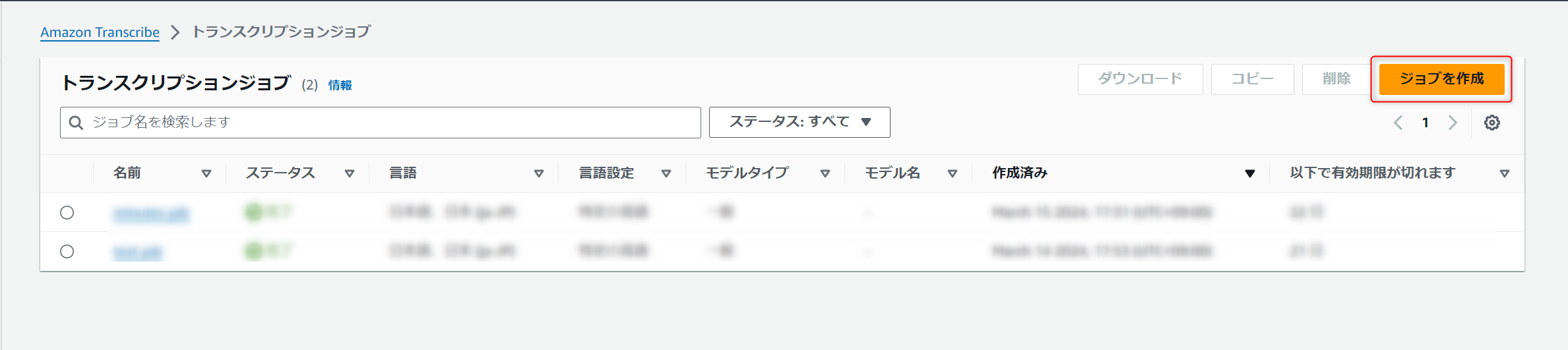
ジョブの設定は以下のようにします。
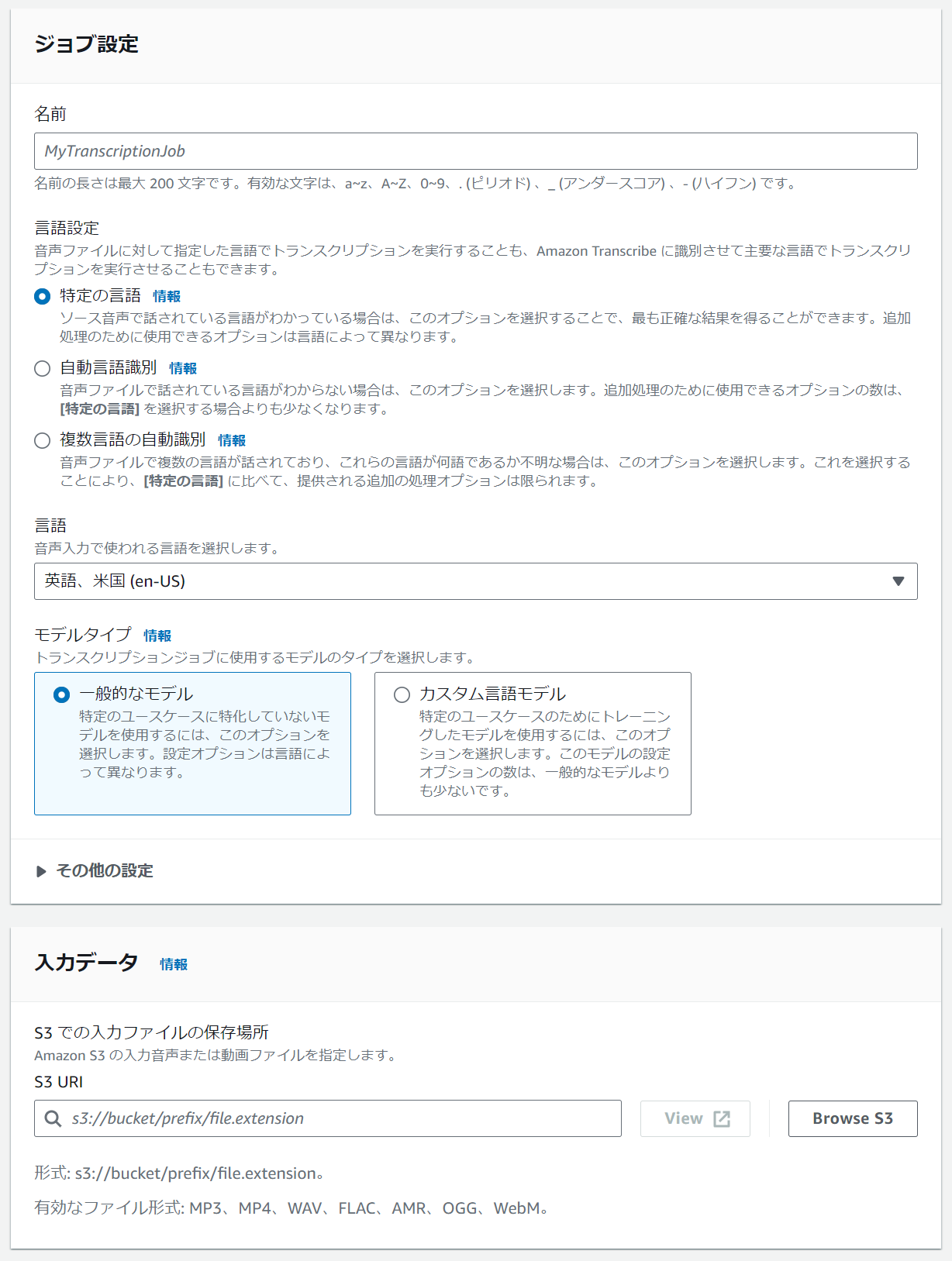
- 名前
- 任意です。わかりやすいものを付けます。
- 言語設定
- 自動識別も使用できますが、今回は言語がわかっているので「特定の言語」を選択します。
- 言語
- 「日本語」を選択します。
- モデルタイプ
- 「一般的なモデル」を選択します。
- 入力データ
- 先ほどメモした音声ファイルの URI を入力します。または「Browse S3」で直接ファイルを選択することもできます。
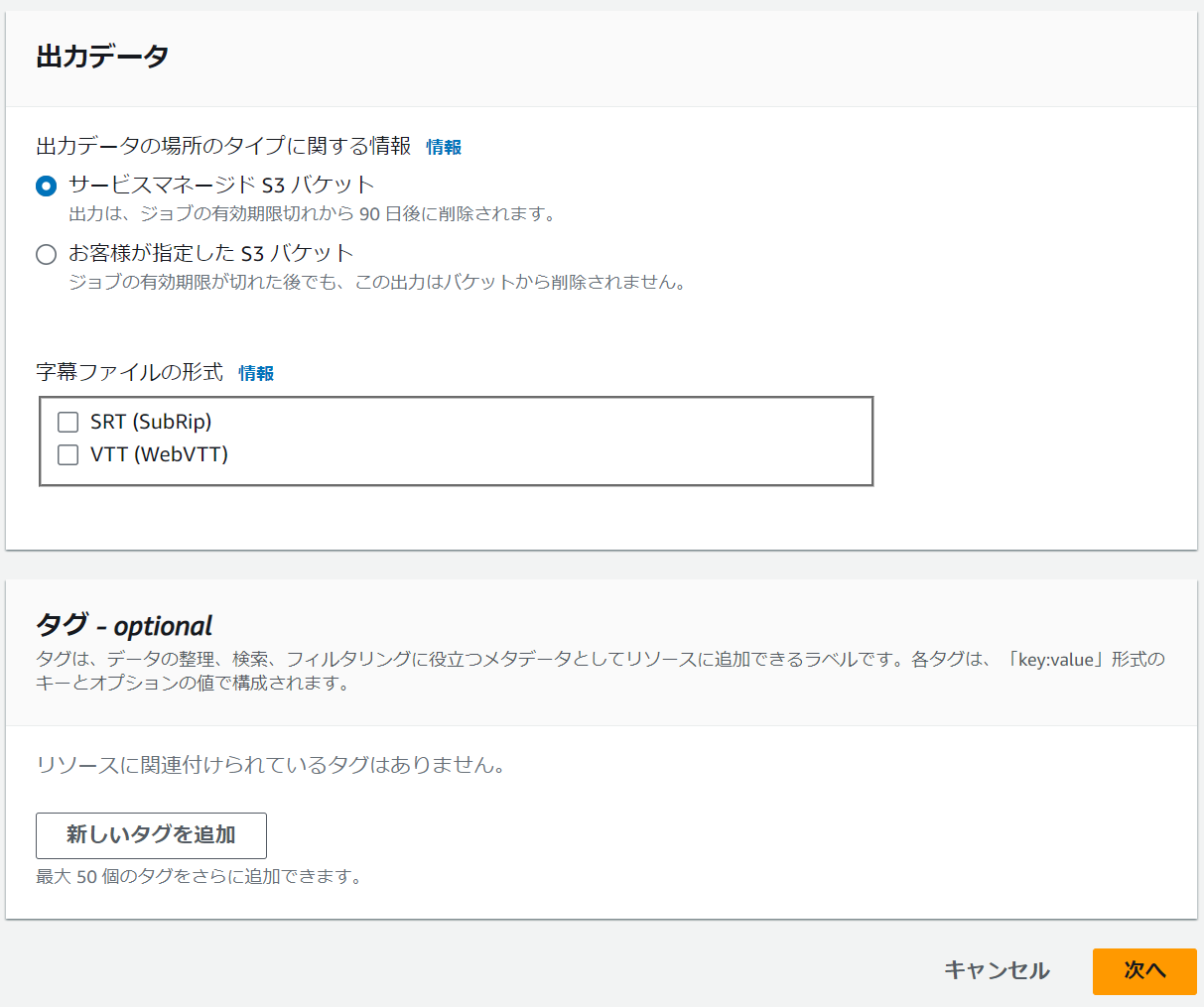
- 出力データ
- 音声の解析結果を格納するバケットを選択します。どちらでも構いませんが「サービスマネージドS3バケット」を選択した場合は有効期限切れになるとファイルが削除されるため、注意が必要です。
- タグ
- 任意です。
ここまで入力したら「次へ」を選択します。
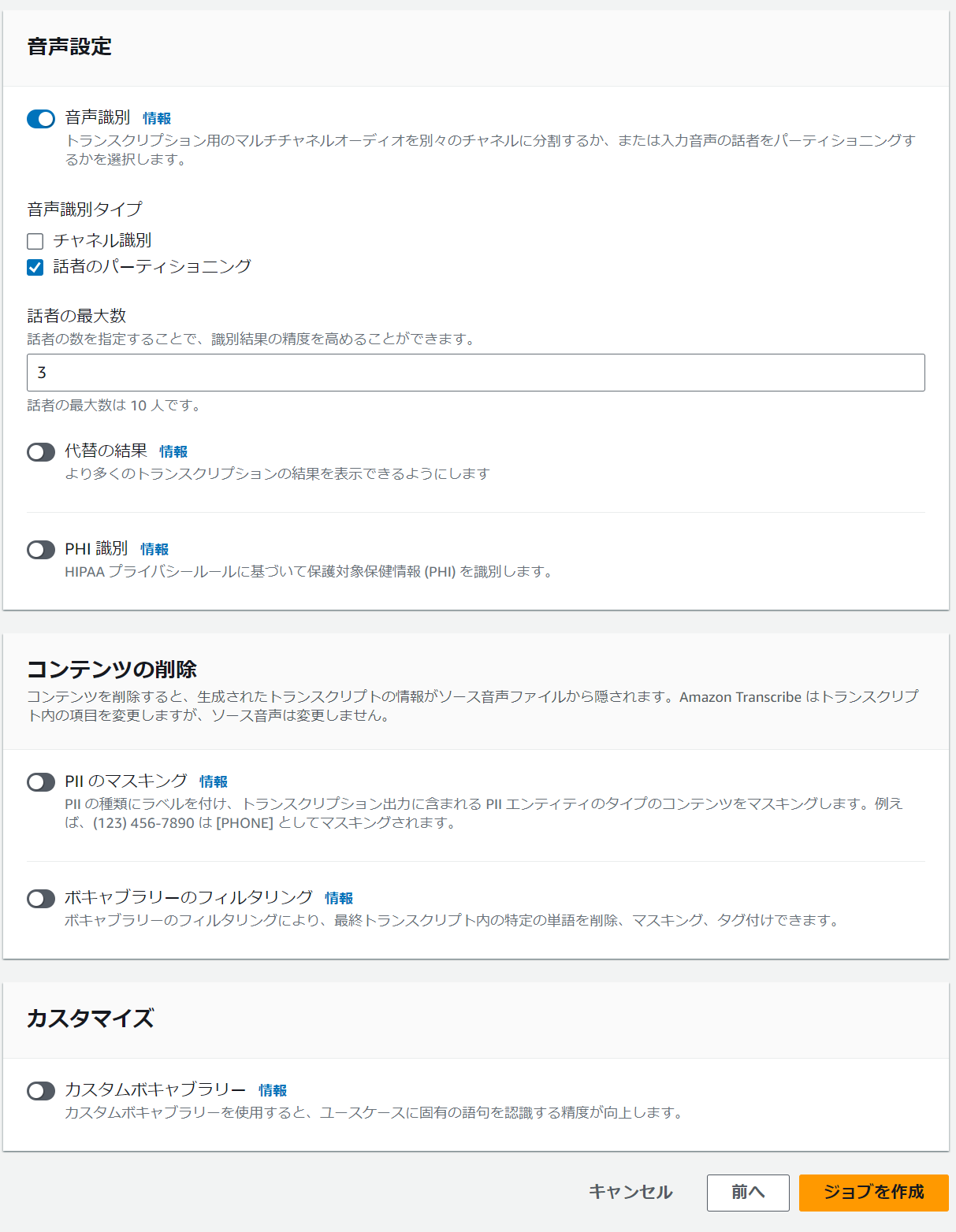
以下のように設定します。
- 音声識別
- 会議の参加人数がわかっている場合は、音声識別を利用して話者のパーティショニングを行います。これにより、実行結果に話者ごとの値を持たせ、区別することが可能です。今回は3人で会話をしているデータを使用しているので「3」で設定しています。
今回は検証なので、プライバシールールに基づく設定や、特定の情報に対するマスキングは行っていませんが、気密性の高い会議では利用してみるのも良いかもしれません。
すべて入力出来たら「ジョブを作成」を選択します。
ステータスが完了になると、以下の結果が閲覧できます。
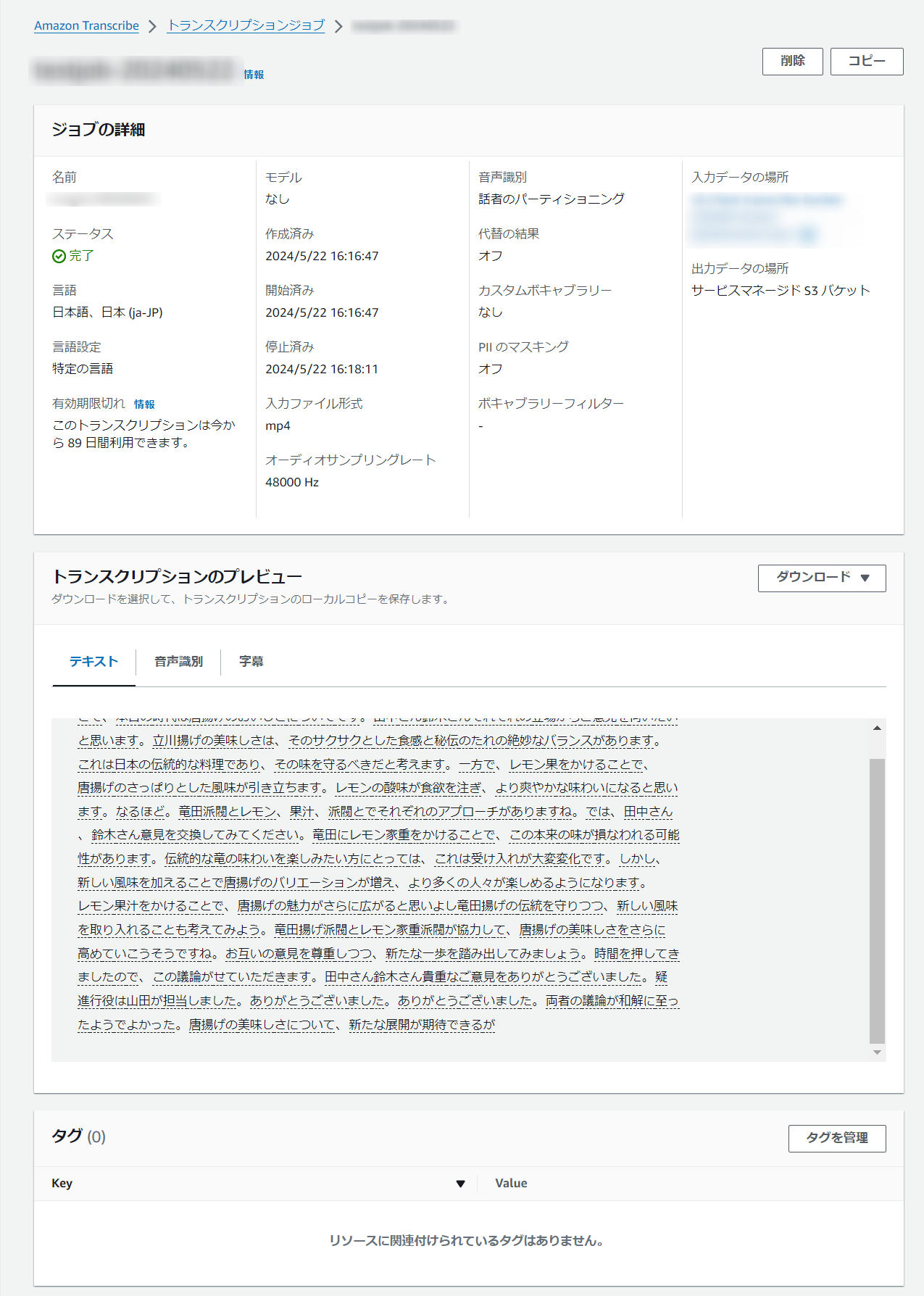
出力データの場所を「サービスマネージド S3 バケット」にしていた場合のみ、トランスクリプションのプレビューで音声データの文字起こしの他、音声識別の結果や字幕を閲覧することができます。
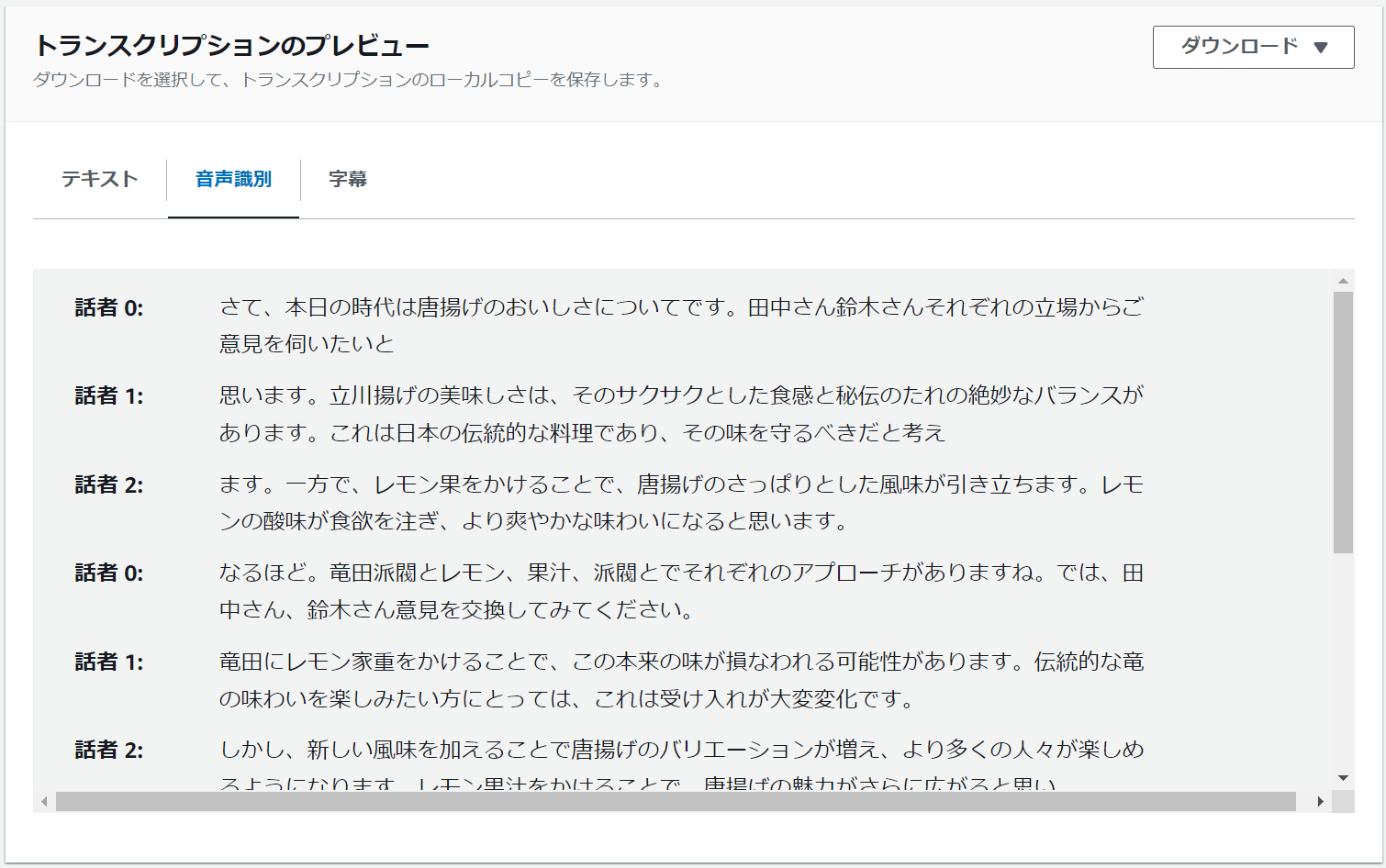
単語の識別や話者の区別については少々誤りが見られますが、内容としては十分に使える程度の差異かなと思います。
※今回は単語を丁寧に発音しつつハキハキと喋ってくれる人工音声を使用しているので、実際の人間の声を使うと結果が異なるかもしれません。
次からは、上記の分析結果を使用して議事録を作っていきたいと思います。
3. Lambda を使用して議事録を作成する
Lambda 関数を作成する前に、出力データの場所を「サービスマネージド S3 バケット」にしていた場合は「トランスクリプションのプレビュー」から実行結果の JSON ファイルをダウンロードし、任意のバケットに格納しておきます。
※出力データであらかじめバケットを指定していた場合、この作業は必要ありません。
関数作成後、以下のコードをデプロイします。
ランタイムは Python 3.12 を使用しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 |
import json import boto3 from collections import Counter # 変数 s3_bucket = '出力データをアップロードしたバケット名' s3_key = '出力データのプレフィックス' region = 'ap-northeast-1' main_language = 'ja' sub_language = 'en' encode = 'utf-8' # client s3_client = boto3.client('s3', region_name=region) comprehend_client = boto3.client('comprehend', region_name=region) translate_client = boto3.client('translate', region_name=region) def lambda_handler(event, context): try: # S3からファイルを読み取る response = s3_client.get_object(Bucket=s3_bucket, Key=s3_key) file_content = response['Body'].read().decode('utf-8') minutes_job = json.loads(file_content) items = minutes_job['results']['items'] # 議事内容の取得 transcript = minutes_job['results']['transcripts'][0]['transcript'] # 日付の処理 meeting_date = s3_client.head_object(Bucket=s3_bucket, Key=s3_key) date_and_time = meeting_date['LastModified'] # 参加者の処理 participants = participants_function(transcript) # 議題の処理 transcript_en = translate_en_function(transcript) agenda = agenda_function(transcript_en) # 議事の処理 contents = content_function(items) # 懸念事項 concern = concern_function(transcript) # 議事録作成 result_job = create_minutes_function(date_and_time,participants,agenda,contents,concern) return { 'statusCode': 200, 'body': "議事録を作成しました。" } except Exception as e: return { 'statusCode': 500, 'body': str(e) } # 参加者 def participants_function(transcript): # エンティティ分析 entities = comprehend_client.detect_entities(Text=transcript, LanguageCode=main_language) unique_persons = set() for entity in entities['Entities']: # 人名を抽出 if entity['Type'] == 'PERSON': unique_persons.add(entity['Text']) participants_string = ", ".join(unique_persons) return participants_string # 議題 def agenda_function(transcript): # 文章解析 nouns = [] syntax = comprehend_client.detect_syntax(Text=transcript, LanguageCode=sub_language) # 頻出単語を抽出 for token in syntax['SyntaxTokens']: if token['PartOfSpeech']['Tag'] == 'NOUN': nouns_ja = translate_ja_function(token['Text']) nouns.append(nouns_ja) frequentl_aappearing_word = Counter(nouns).most_common(1) agenda = frequentl_aappearing_word[0][0] if frequentl_aappearing_word else None return agenda # 懸念事項 def concern_function(transcript): concern = [] key_phrases_response = comprehend_client.detect_key_phrases(Text=transcript, LanguageCode=main_language) # キーフレーズを取得 key_phrases = key_phrases_response['KeyPhrases'] key_phrases_text = [phrase['Text'] for phrase in key_phrases] # ネガティブなフレーズを抽出 for phrase in key_phrases_text: sentiment = comprehend_client.detect_sentiment(Text=phrase, LanguageCode=main_language) emotion = sentiment['Sentiment'] if emotion == "NEGATIVE": concern.append(phrase) matter_of_concern = ", ".join(concern) return matter_of_concern # 議事 def content_function(items): segmented_transcripts = [] current_segment = [] current_speaker = items[0]['speaker_label'] for item in items: speaker = item['speaker_label'] content = item['alternatives'][0]['content'] if speaker != current_speaker: # 現在のセグメントを文字列に結合してリストに追加 segmented_transcripts.append(''.join(current_segment)) current_segment = [] current_speaker = speaker current_segment.append(content) # 最後のセグメントを追加 if current_segment: segmented_transcripts.append(''.join(current_segment)) # 結果を表示 segmented_transcripts_text = '\n'.join([f" - {segment}" for segment in segmented_transcripts]) return segmented_transcripts_text # 英語翻訳 def translate_en_function(text): response_en = translate_client.translate_text( Text=text, SourceLanguageCode='ja', TargetLanguageCode='en' ) translated_en_text = response_en['TranslatedText'] return translated_en_text # 日本語翻訳 def translate_ja_function(text): response_ja = translate_client.translate_text( Text=text, SourceLanguageCode='en', TargetLanguageCode='ja' ) translated_ja_text = response_ja['TranslatedText'] return translated_ja_text # 議事録作成 def create_minutes_function(date_and_time,participants,agenda,contents,concern): content = f""" # 議事録 ## 日時: {date_and_time} ## 参加者: {participants} ## 議題: {agenda} ## 議事: {contents} ## 懸念事項: {concern} """ # ファイルの作成とアップロード file_name = 'minutes/minutes_' + agenda + '.md' markdown_encode = content.encode(encode) s3_client.put_object(Bucket=s3_bucket, Key=file_name, Body=markdown_encode) |
バケットから出力データを読み取り、議事録に必要な項目を取り出した後、マークダウン方式でテキストファイルを作成し、S3 に配置するという仕組みです。
処理を簡単に説明したいと思います。
日付の処理
議事録に記載する日付の処理です。会議当日に議事録を作成している、という想定で、出力データが S3 にアップロードされた日付を取得しています。
参加者の処理
AWS Comprehend のエンティティ分析という機能を使い、会議内容から「人名」のみを取得し「参加者」としています。
議題の処理
AWS Comprehend の構文解析という機能を使い、頻出する単語を特定し、議題として議事録に記載します。こちらの機能は現時点では日本語に対応していないため、AWS Translate を用いて一度文章を英語に翻訳した後に処理をしています。
懸念事項の処理
AWS Comprehend のキーワード抽出という機能を使い、会議内容からいくつかのキーワードを抽出します。さらに Comprehend でそのキーワードの感情を分析し、ネガティブと判断された単語を懸念事項として議事録に記載します。
議事の処理
会議内容を解析し、それぞれの話者が話している内容ごとに区分を設け、議事として記載をします。
また、権限は関数作成時に自動で付与される AWSLambdaBasicExecutionRole に加え、以下三つのリソースに対するアクションが許可されていれば大丈夫です。
- S3
- AWS Comprehend
- AWS Translate
こちらの関数を用い、実際にマークダウン方式で出力された議事録が以下です。
4. 議事録
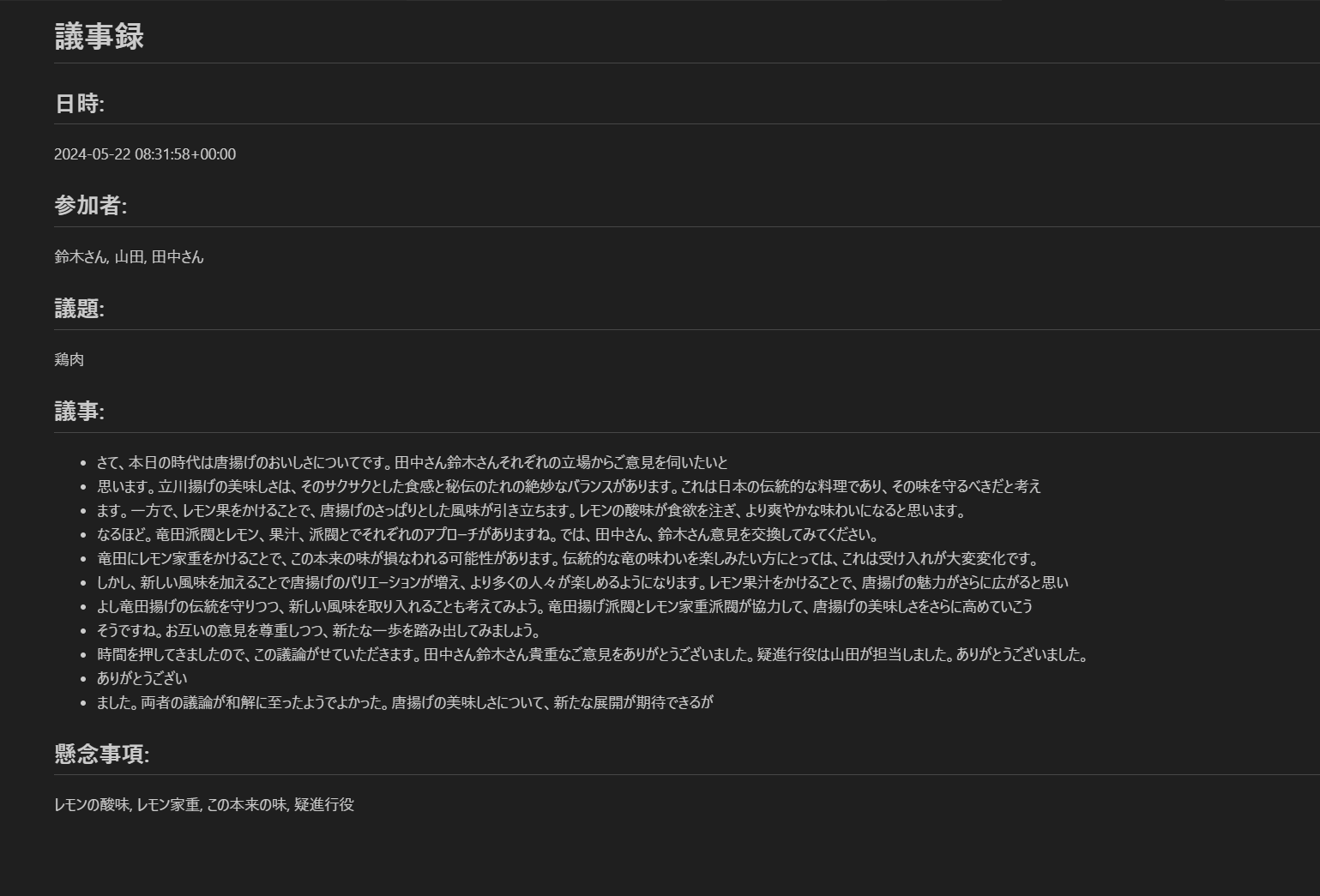
いかがでしょう。
それっぽい仕上がりになっているでしょうか。
まとめ
作っては見たものの、こちらを胸を張って議事録とするためには、更なる改良が必要そうです。
少し考えるだけでも、以下のようにたくさんの改善点が挙げられます。
- 日付の融通が利かない
- 会話中に人名が出てきた場合、問答無用で参加者として認識されてしまう
- 構文解析を使用するために原文を翻訳をしているため、議題が元々のニュアンスと異なる
AWS Comprehend の構文解析が日本語に対応した際には、また手を加えて"疑似"議事録の精度を上げていきたいと思います。
最後まで目を通していただきありがとうございました。
投稿者プロフィール
- AWS の諸々について、初学者目線から書いていけたらいいなと思っています!