本日(2019年8月23日) に AWS で AZ 障害が発生しました。弊社でも多数のアラートを受信しました。弊社以外でも多くのシステムが影響を受けたようです。幸いにもデータ損失などの重大な障害は避けられたようですが。今更ながら影響の大きさを感じます。
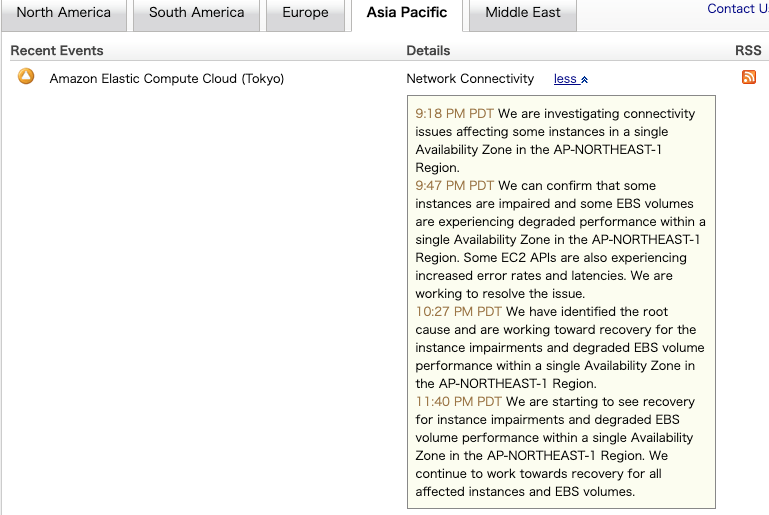
その中でも影響を受けずに生き残ったシステムも存在します。単に運が良かっただけのモノもありますがキチンと対策する事で影響を軽減できた可能性があります。ここで一度リージョンやAZについておさらいしておきたいと思います。
アベイラビリティーゾーンとは
AWSではリージョン(地域)という単位でサービスを提供しています。AWSのサービスは多くの場合リージョンを指定して利用することになります。日本では東京と大阪にリージョンがあります。リージョン内には物理的に離れた複数のデータセンターが配置されて冗長な構成になっています。リージョンが世界中のどこにあるかは以下のサイトで確認することができます。
アベイラビリティーゾーン(以下 AZ)は物理的にリソースが配置される場所です。リージョン内には複数の AZ が配置され物理的に異なる場所にリソースを配置することができるようになっています。
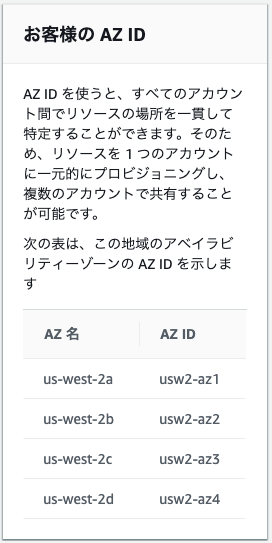
ここで注意が必要なのは、アベイラビリティーゾーン自体も複数のデータセンターから構成されていることです。どのデータセンターに配置されるかはアカウント毎に決まります。データセンターの具体的な場所はセキュリティ上の理由から一般に公開されていませんが、AZ ID というデータセンターを一意に識別する ID が振られています。
通常特に意識する必要はありませんが、VPC シェアリングなど個別に AZ ID が同じことが条件になっているモノもあるので念の為覚えておいたほうが良いでしょう。
今回の障害でも個別のデータセンター、おそらく状況から apne1-az4 で何らかの障害が発生した可能性があると推測しています。
自分のアカウントで AZ と AZ ID を確認するには AWS Resource Access Manager にアクセスして、左のメニューの一番上にある、”Resource Access Manager” をクリックすると、ページの右下あたりに表示されます。
AZ を利用した冗長構成で耐障害性を高める
このように複数の AZ を用意しているのは、今回のようなデータセンター障害が発生した場合に対処するためです。AWSをはじめとするクラウドは何もしなくても非常に高い耐障害性を持っているわけではなく、耐障害性が高める複数の仕掛けを用意していることです。
複数の AZ にリソースを分散してリソースを配置することで今回のような単一データセンター障害の場合でも影響を軽減することができます。AWS でも強くこのような構成が推奨されています。
例えば ELB を利用して負荷分散する場合は、ap-northeast-1a と ap-northeast-1c にインスタンスを配置するようにします。また Amazon RDS などのマネージドサービスでもマルチAZ 構成を指定して、別の AZ にリードレプリカを配置し、障害検出時に自動的に切り替えることができます。オートスケーリングを利用する場合でも、複数の AZ を指定して障害時に自動的に、もしくは主導で切り替えることができます。
もちろんコストとのトレードオフから、冗長性を放棄するという選択もあります。その場合は、今回のような障害が発生した場合は、AWS自身が復旧してくれるのをじっと待つことになります。サービスが停止していることの損害と冗長構成にした場合の追加費用とのトレードオフをよく検討する必要があります。
その場合でも AMI などのバックアップを作成しておき、障害発生時に別の AZ で起動することでリカバリすることも考えられます。
より広範囲での障害に備えて別リージョンにコールドスタンバイの災対環境を用意しておくことも有効でしょう。従来であれば海外に DR 環境を用意することは、コスト的にも技術的にも難しかったと思いますが、AWS を利用することで簡単に DR環境を海外に用意することができます。
以上、駆け足ですが対策を紹介させていただきました。






