
こんにちは、幅広い視野を持つエンジニアを目指しています田中と申します
今日はAWS Batchを文字通りバッチ処理とスケジューラとして使ってみます
ECRとECS, dockerを使用します(単語の定義程度の理解で問題ありません)
TL;DR
目次
はじめに
皆さんはJenkinsやTravis CIなどでバッチジョブを作ったことがありますか?
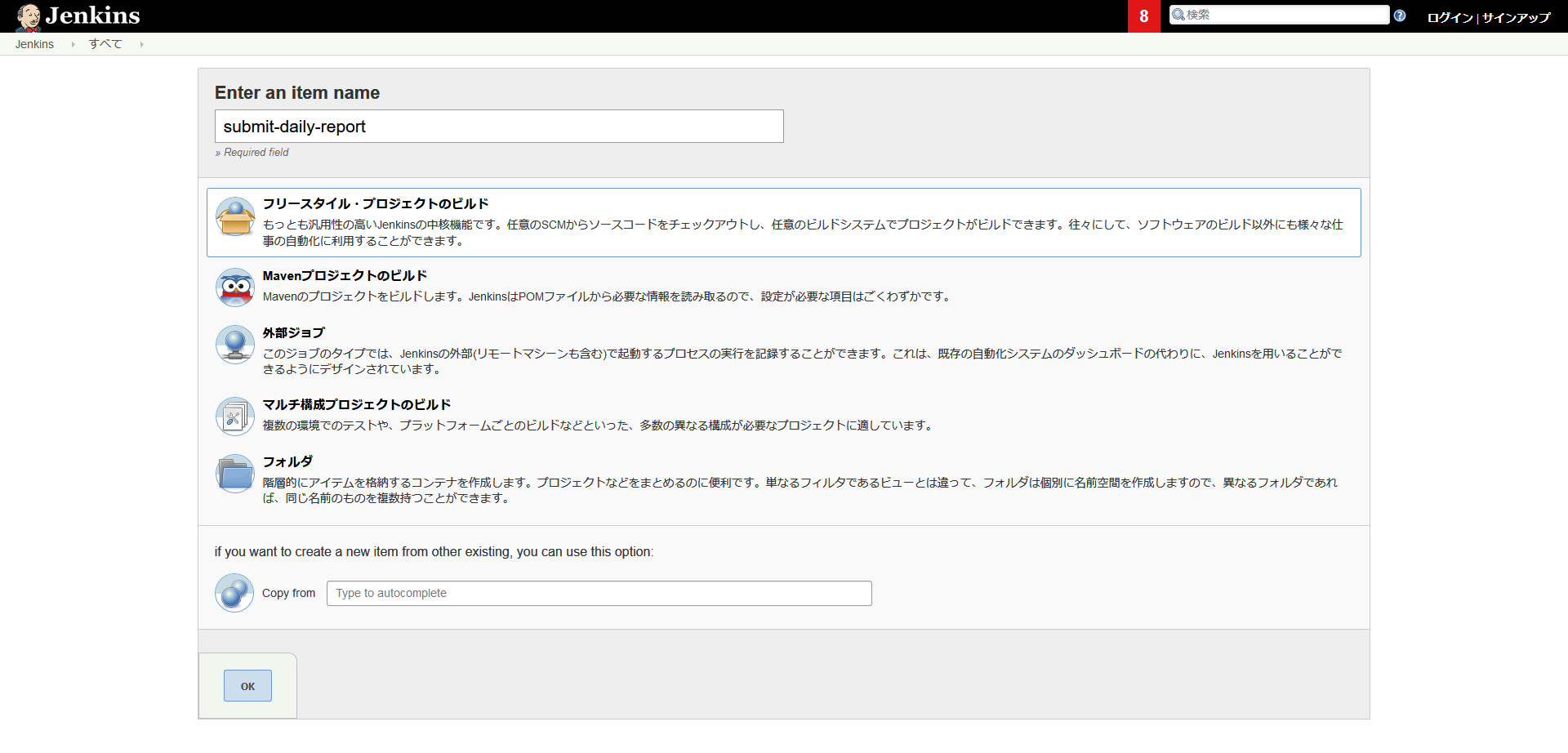
例えばJenkinsではcronのように定時バッチが設定できます。夜中にテストを回したり、レポートを半自動生成したり…仕事の自動化に一役買ってくれます
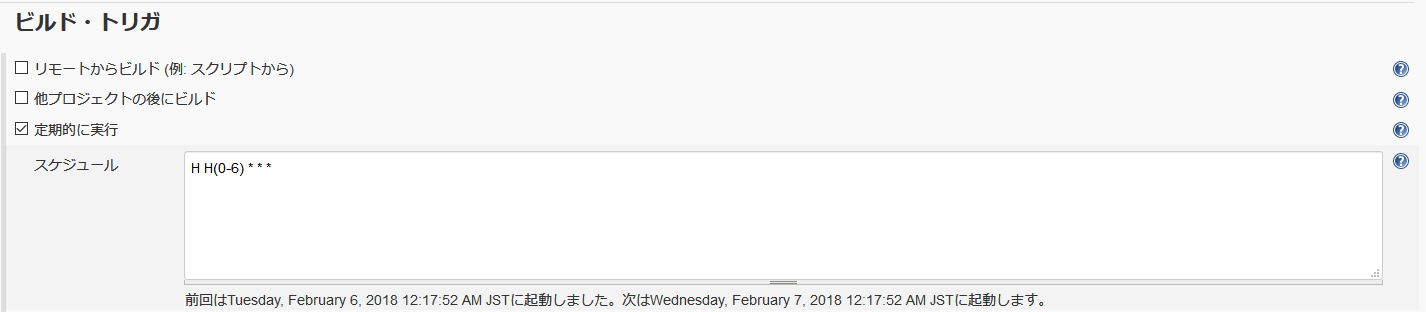
ユニットテストやソースコードのコンパイル、デプロイなどのバッチ処理にとても便利ですね!
目標
CIツールのジョブと同等のことをAWS Batchを使って実現する
概要
AWS Batchとは?
気軽に使えて効率的なバッチコンピューティング機能(公式引用)
https://aws.amazon.com/jp/batch/
なるほどcronですね・・・
の10ページによるとcronのような定時バッチの処理エンジンではないとのこと。残念
でもタスクスケジューラとして使いたい!
まずは使ってみる
手順
まずAWSコンソールからコンピューティング→AWS Batchを選びましょう
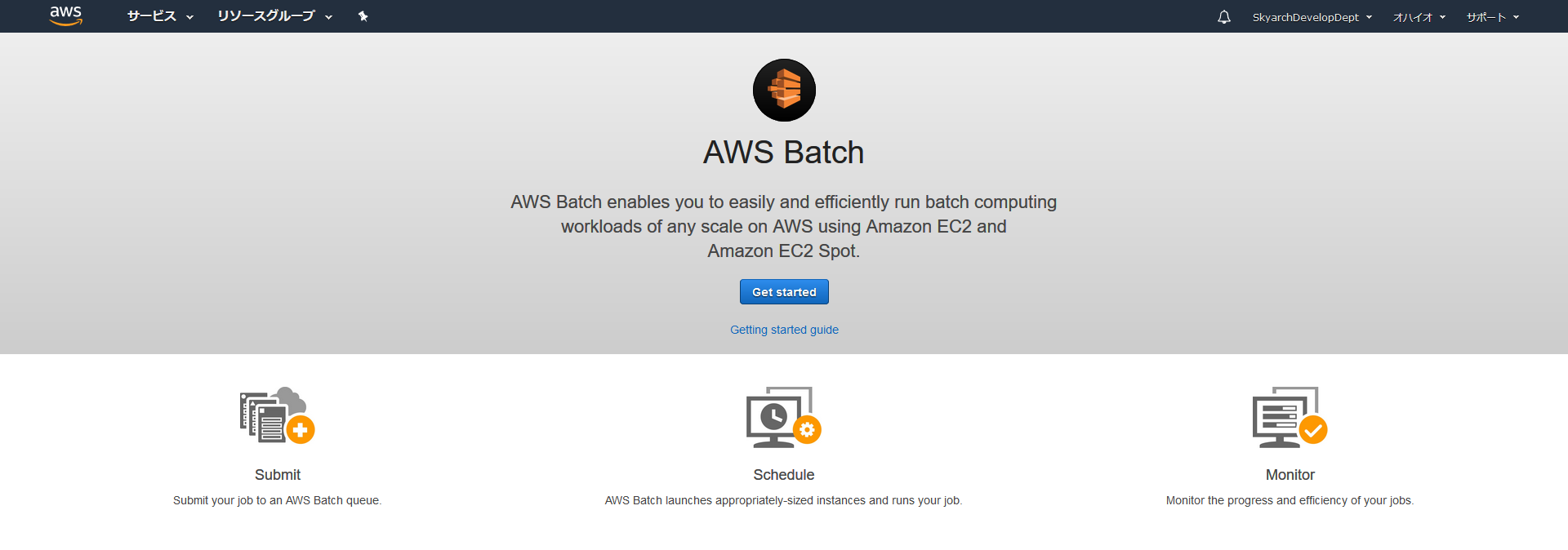
使用例見る限りタスクスケジューラとしても使える?
AWSマネージドのタスクスケジューラ、ナイスです!
構成要素として以下があるようです、順に見ていきます
- コンピューティング環境
- ジョブキュー
- ジョブ定義
- ジョブ
コンピューティング環境
AWS Batchを実行するECS環境の設定のこと
左メニューからCompute environmentsを選択、Create environmentを押下
コンピューティング環境設定1
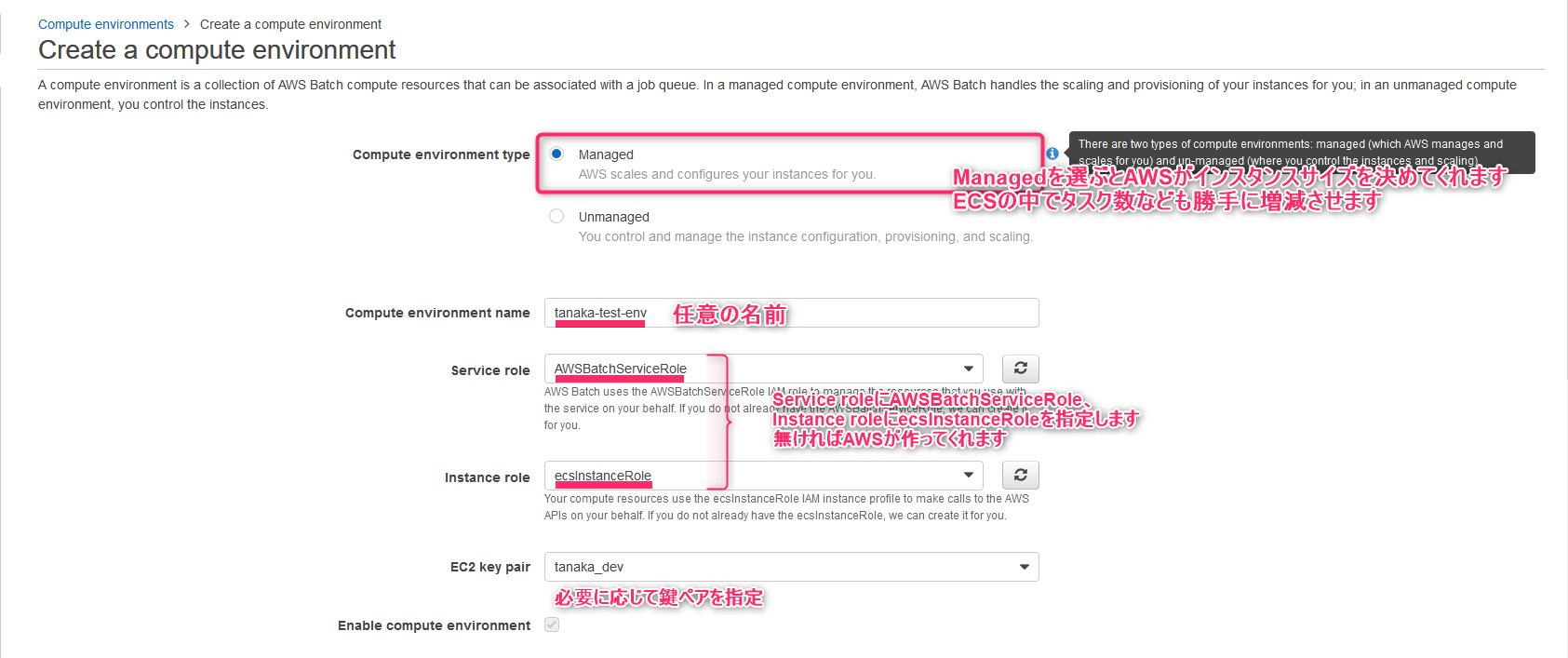
- Compute environment typeはManagedを選択します(UnmanagedにするとAPIでインスタンス設定を操作することができます)
- Compute environment nameには任意の名前を指定できます
- Service roleにはAWSBatchServiceRoleを、Instance roleにはecsInstanceRoleを指定します(存在しなければ作られます)
コンピューティング環境設定2
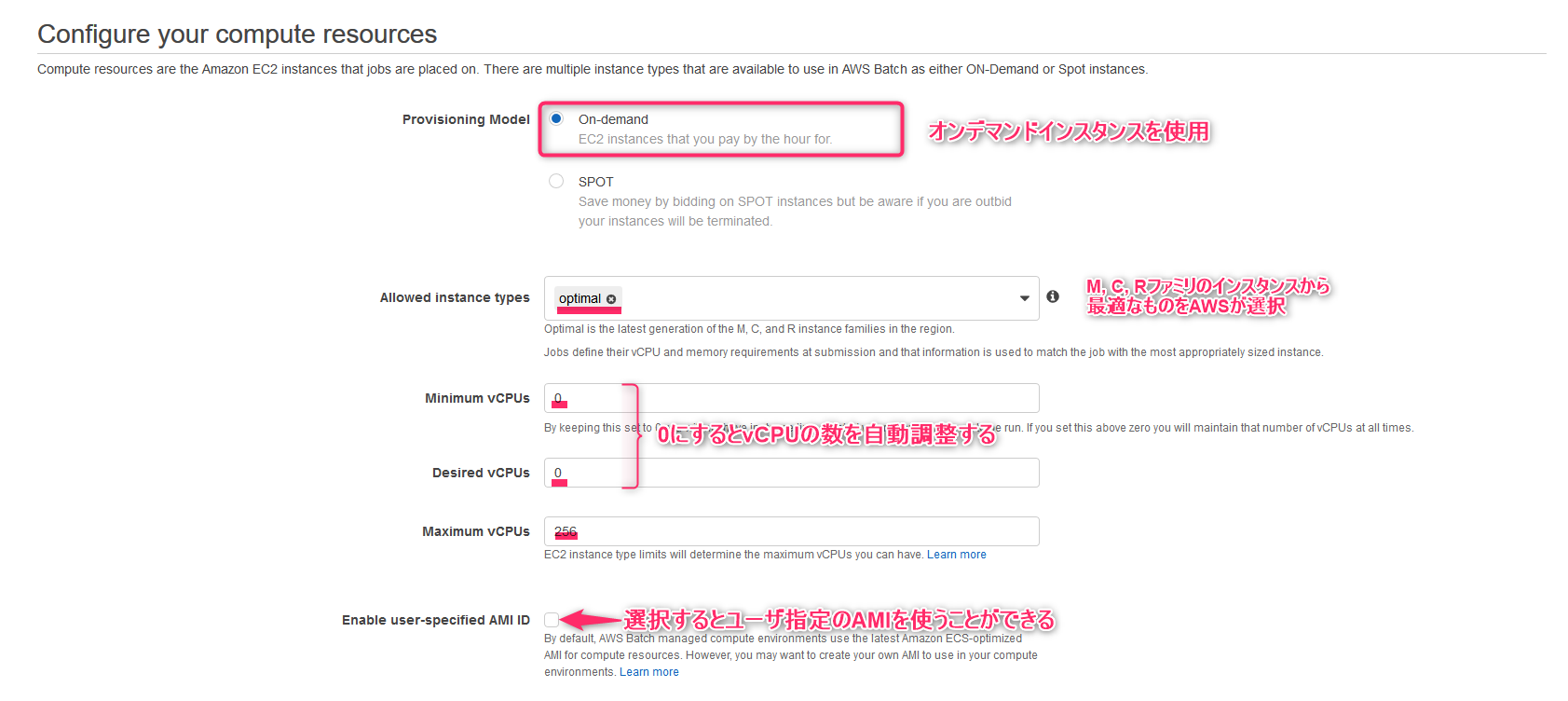
- Provisioning ModelはOn-demendを選択します(SPOTにするとスポットインスタンスを動的に購入して使うこともできます)
- Allowed instance typeにはEC2インスタンスサイズを指定できます。デフォルトのoptimizedはM, C, Rファミリのインスタンスサイズから最適なものが割り当てられます
- Minimum vCPUsおよびDesire vCPUsには最小vCPU数と希望vCPU数、Maximum vCPUsには最大vCPU数を指定します
- Enable user-specified AMI IDを選択するとユーザAMIを使うことができます(Compute environment typeがUnmanagedの時のみ)
他の設定項目についてはEC2と同じため省略します。
必要項目を全て入力したらCreateを押下します。
これでバッチを実行するECS環境ができました。
ジョブキュー
発行されたジョブを溜めておくキュー
AWS Batchではジョブの並列実行が可能です(複数のコンピューティング環境を1つのジョブの実行に割り当てることもできます)
通常、多数のジョブを並列実行するため、キューの作成を行う必要があります
左メニューからJob queueを選択、Create queueを押下
ジョブキュー設定
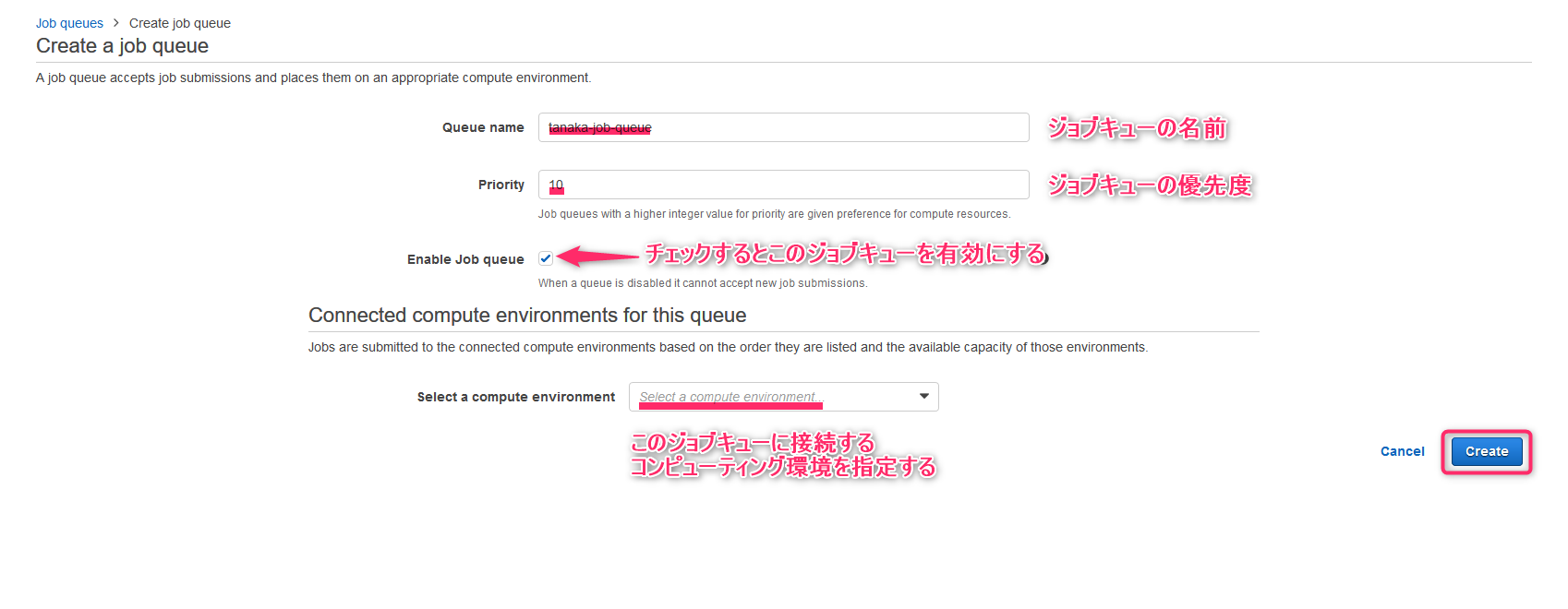
- Queue nameにはキューの名前を指定できます
- Priorityにはジョブキューの優先度が指定できます。(0から2147483647)
- Select a compute environmentに上で作ったコンピューティング環境を指定します
これで発行されたジョブを溜めておくキューができました
ジョブ定義作成
実行するジョブの定義
AWS BatchではECS環境上でタスクとしてジョブを実行します
タスクの実体はコンテナであるため、dockerのDockerfileと同じようにコンテナとその設定を用意する必要があります
ジョブ定義設定1
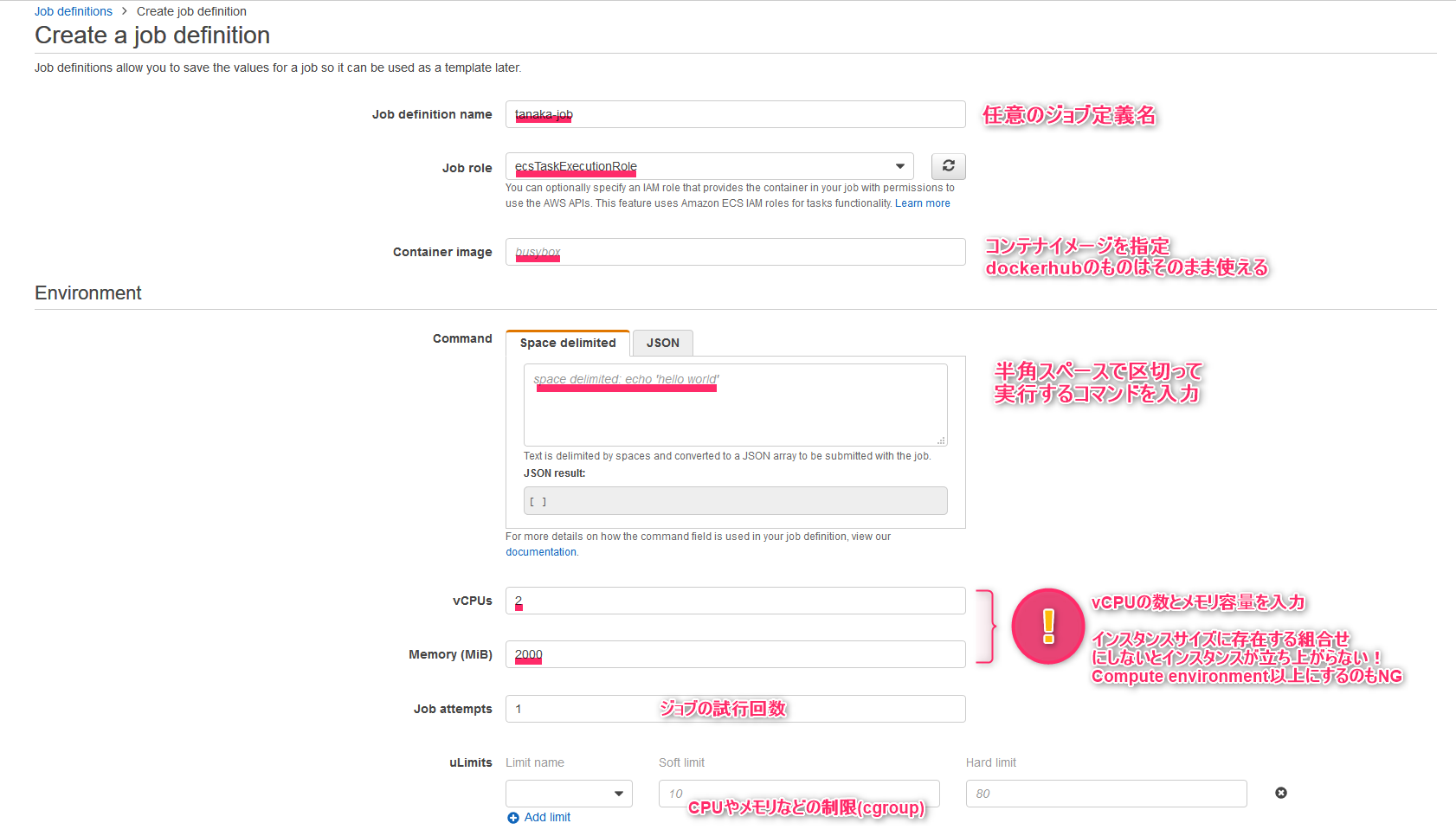
- Job definition nameにはジョブ定義の名前を指定できます
- Job roleはecsTaskExecutionRoleを指定します(存在しなければ作られます)
- Container imageにはdocker hubのイメージを指定します(今はデフォルトのbusyboxで構いません)
- Commandには半角スペースで区切って実行するコマンドを入力します(EC2のユーザデータと同様です)
- vCPUsとMemoryにはインスタンスサイズとして有効な組み合わせを入力します(なんとデフォルトで指定されているメモリ2GB/2コアは存在しません!さらに性質が悪いことに状態がrunnableから遷移せずエラーもでないため原因に気付きにくいです!!)
- Job attemptsにはジョブの試行回数を指定します(1~10)ジョブが失敗した場合には状態がrunnableになるまで指定回数回の再試行が行われます
- uLimitにはcgroup設定を入力します(メモリやCPUの使用量に制限をかけることができます)
ジョブ定義設定2
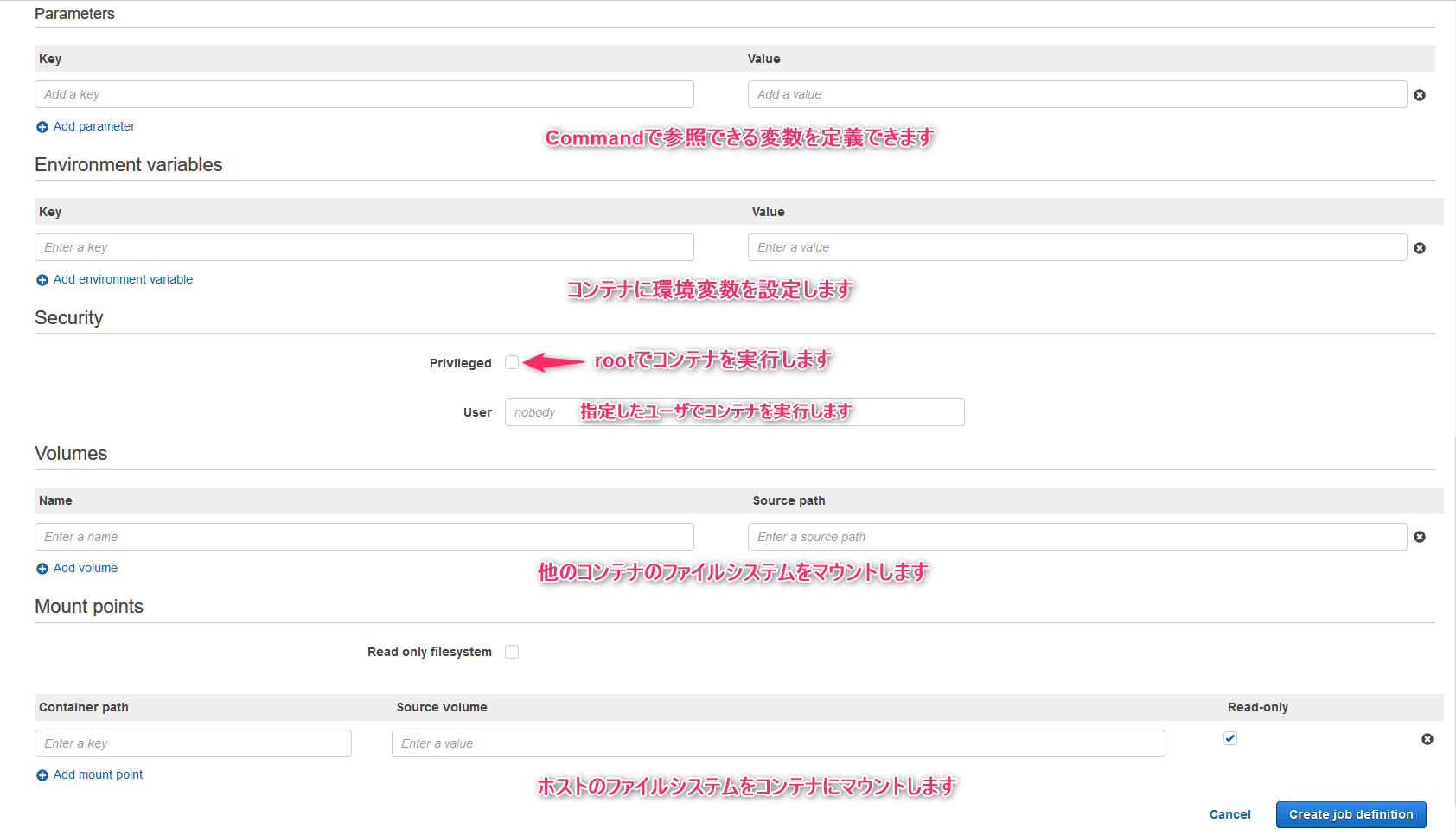
- Parametersにはジョブ定義設定1で指定したCommandに埋め込むことができる変数を設定できます(例:キー(MSG), 値(Hoge)を指定し、Commandでecho Ref::MSGとすろとHogeと表示できます)
- Environment variablesにはコンテナに設定したい環境変数を指定します(コンテナによりけり、db名だったりAPIキーだったり・・・dockerコマンドのeオプションと同等)
- Securityのprivilegedにチェックを入れるとroot権限でコンテナを実行します。Userにユーザを指定することもできます
- Volumesを指定すると、他のコンテナのファイルシステムをジョブが作成するコンテナにマウントできます(dockerコマンドの--volumes-from)
- Mount pointsを指定すると、ホストのファイルシステムをコンテナにマウントして使うことができます(dockerコマンドの-v host_path:container_pathと同等)
ここまで設定出来たらCreate job definitionを押下してジョブ定義を作成しましょう
ジョブ作成
実行するジョブ
いよいよジョブを作成し、実行しましょう
今まで設定したコンピューティング環境とジョブキューとジョブ定義を使用するジョブを作成します
ジョブ設定1
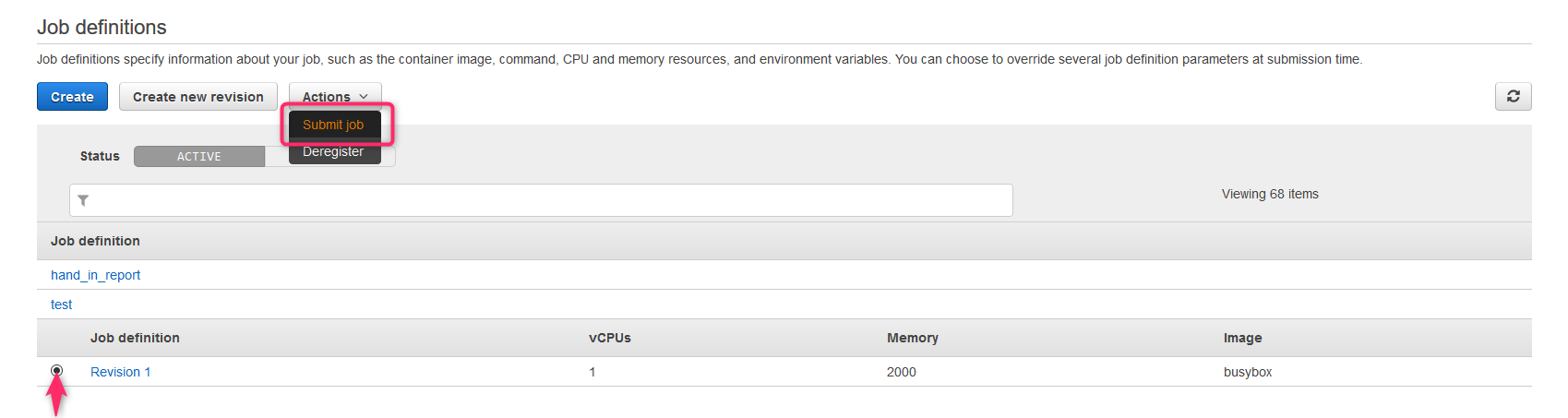
- 先ほど作ったジョブがRevision 1として登録されているので選択し、ActionsからSubmit Jobを選択します(左メニューのJobsからでも可能です)
ジョブ設定2
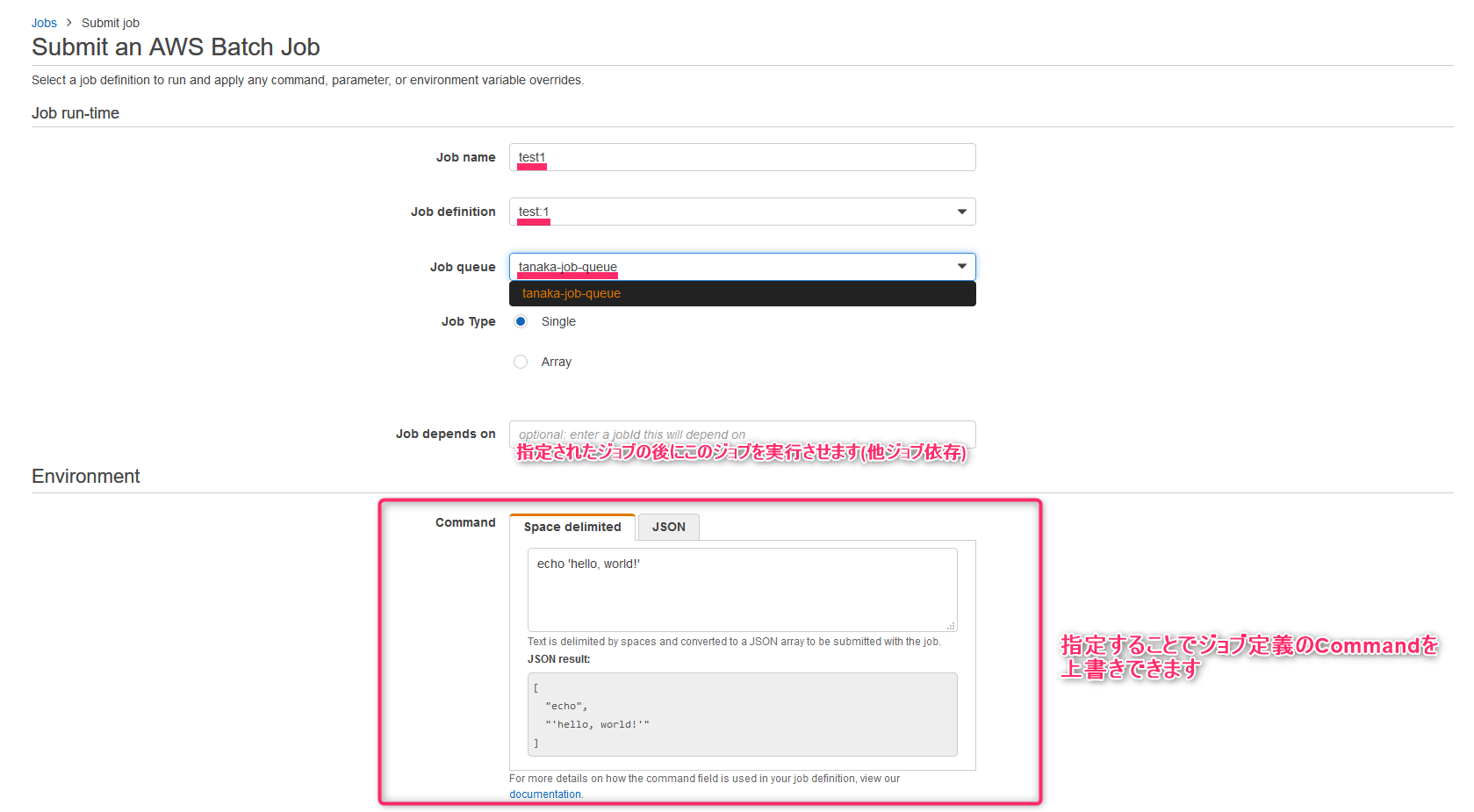
- Job nameにはジョブ名を指定できます
- Job definitionsには先ほど作ったジョブ定義を指定します
- Job typeをArrayにすると配列ジョブとなり子ジョブを指定した数だけ生成します(実行ジョブが非同期実行可能なら並列実行になります)
- Job depends onを指定すると他のジョブが終了した後にこのジョブを実行します
- Command以下ジョブ定義と同様の設定項目がありますが、ここに入力をするとジョブ定義を上書きすることができます(Dockerfileをdockerコマンドで上書きできるのと同じ)
それではSubmit jobを押下しジョブを実行しましょう
ジョブ実行画面
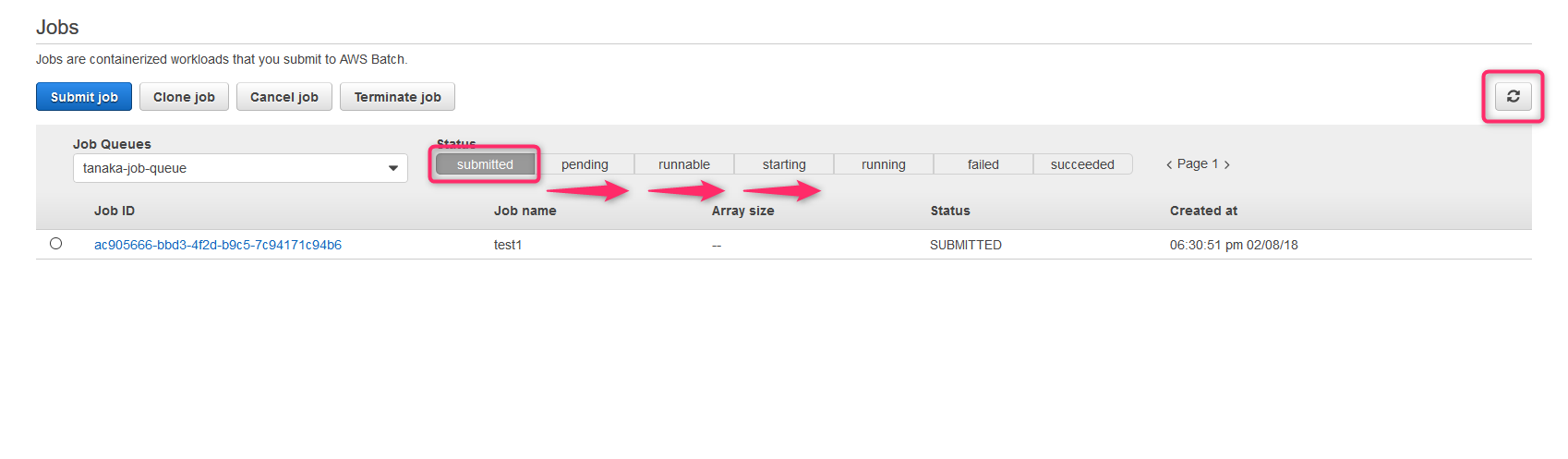
ジョブが発行され状態がsubmittedになっています。この状態で右上の更新ボタンを押すと状態がどんどん変わっていきます
状態がsucceededになったらジョブを選択します
ジョブ結果画面
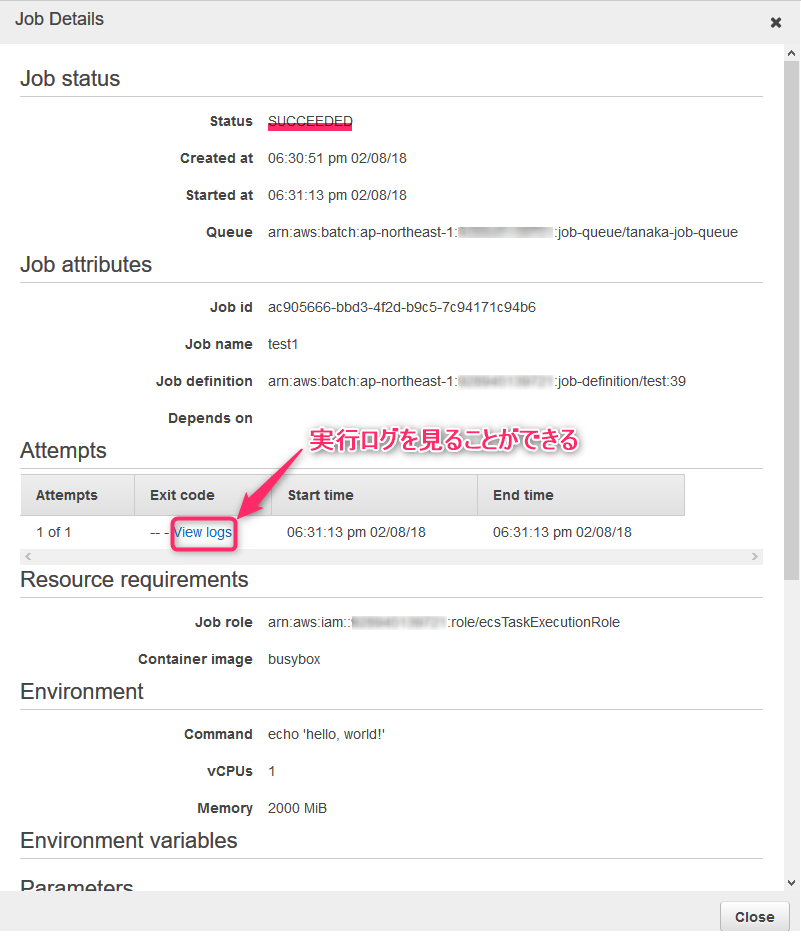
View logsを押下しましょう

見慣れた(?)CloudWatchの画面でジョブの結果を見ることができました!
裏ではECSが動いているようです。タスクがコンテナ。ジョブはサービスとして動的に定義されているようです

Fargateキタ━(゚∀゚)━!
さて文章が多くなったのでこの記事はここまでにします
進捗
ここまでで実現できたことは以下です
- AWS Batchのコンピューティング環境を作った
- AWS Batchのジョブキューを作った
- AWS Batchのジョブ定義を作った
- AWS Batchのジョブを作った
- busyboxコンテナ上で単純なコマンドを実行した
まあ、Hello, world!レベルのことはできましたが、満足はできませんね・・・
記事は後編に続きます
よろしければ、後編もお付き合いください
投稿者プロフィール
最新の投稿
 AWS2021年12月2日AWS Graviton3 プロセッサを搭載した EC2 C7g インスタンスが発表されました。
AWS2021年12月2日AWS Graviton3 プロセッサを搭載した EC2 C7g インスタンスが発表されました。 セキュリティ2021年7月14日ゼロデイ攻撃とは
セキュリティ2021年7月14日ゼロデイ攻撃とは- セキュリティ2021年7月14日マルウェアとは
- WAF2021年7月13日クロスサイトスクリプティングとは?







