
はじめに
社内で利用している、各種生成AIモデルへの問い合わせツールの会話履歴を元にどのようなカテゴリでの利用がされているか、また生成AIへの問い合わせスコアを統計として出力するために、バッチを組みしばらく運用してみたので、まとめます。
目次
構成の概要
統計バッチ
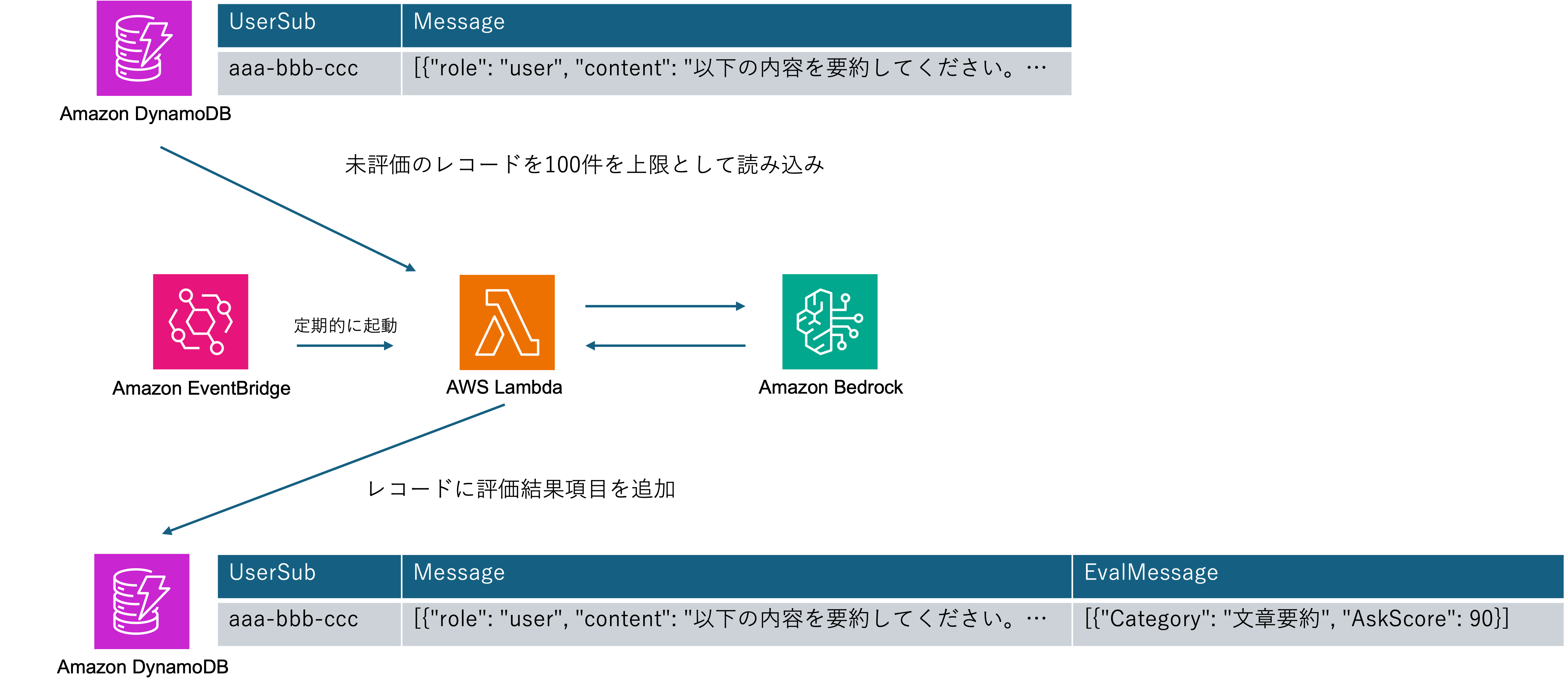
LambdaをEventBridgeで定期的に起動し、未評価レコードを検索し評価結果を同じレコードに項目追加します。
DynamoDBレコードの内容については超簡略ですが、イメージまでに。
統計確認・ダッシュボード
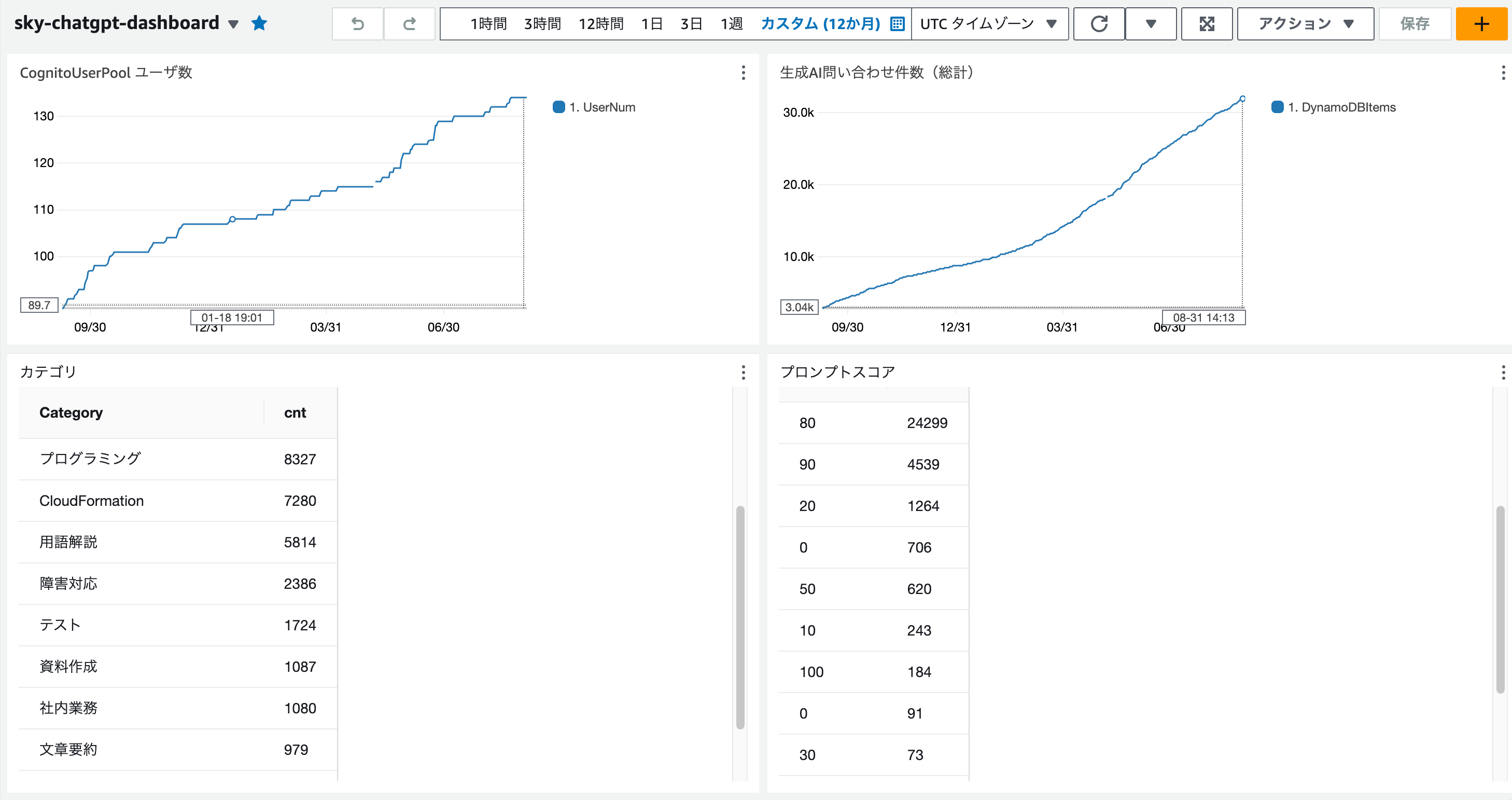
DynamoDBをS3にエクスポートし、Athenaでクエリを実施する事で統計確認を行えるようになっています。
費用について
AWS内部で完結したかったので、基本方針としてはBedrock利用ですが、念の為費用を確認しました。
今回のケースでは入力Tokenはとても多いですが、出力Tokenはとても少ないため、入力Token費用及び出力結果(品質)を意識し下記2つで比べてみました。
2024/7/17現在
gpt-3.5-turbo-0125
- Input $0.00050 / 1K (Batch APIだと24時間以内のレスポンス返却で50% Off)
- Output $0.00150 / 1K (Batch APIだと24時間以内のレスポンス返却で50% Off)
Claude 3 Haiku
- Input $0.00025 / 1K
- Output $0.00125 / 1K
算出するための参考リンク
OpenAI社 Tokenizer
利用するプロンプト+問い合わせる文章でどれくらいのToken数消費予定となるか見通しをつける
https://platform.openai.com/tokenizer
AWS Bedrock 費用
https://aws.amazon.com/jp/bedrock/pricing/
OpenAI 費用
右上に「Show Price per 1K tokens」チェックボックスがあるのでこちらをチェックすると比較しやすいです
https://openai.com/api/pricing/
詳細
Lambdaバッチ
プロンプトについて
今後のモデル、XMLタグ、etc... で変わっていくと思いますが
当初 「下記JSONFormat で回答して」 とシンプルに書いていた所、崩れたJSON、理由が含まれた長いテキストでレスポンスが返却されてしまったので
「厳格に下記JSONFormatのみで回答して下さい。理由等は不要」 としたら良い結果が得られました。
また、壊れたJSONが帰ってくる事や、稀に指定していないカテゴリも帰ってくるため
精度が求められる場合には当然ですが、レスポンスをしっかり検証する必要があります。
|
1 2 3 4 |
下記メッセージのカテゴリ(以下のどれかを判断)と生成AIへの問い合わせスコアを1-100で採点し、厳格に下記JSONFormatのみで回答して下さい。理由等は不要です。 カテゴリ: テスト,文章要約,用語解説,CloudFormation,CDK,プログラミング,障害対応,問題作成,資料作成,顧客対応,社内業務... JSONFormat: [{"Category": "判断したカテゴリ", "AskScore": "採点した点数"}] 以下メッセージ |
Glueデータカタログ/Athenaクエリ
DynamoDBをS3にエクスポートする際には Amazon Ion (JSON のスーパーセットであるオープンソースのテキスト形式) を選択し任意のS3バケットにエクスポートした後、下記テーブルを作成しクエリを実施しています。
DynamoDBには実際に下記のようなデータが入っている前提です。

テーブル作成
DynamoDBのエクスポートデータから統計を取るために必要な項目でテーブル作成
(一部抜粋)
|
1 2 3 4 5 6 7 8 9 10 11 12 |
CREATE EXTERNAL TABLE <code>dynamodb_export_table_with_evaluate</code>( unixtimestamp</code> decimal(38,18), evalmessage</code> string ) ROW FORMAT SERDE 'com.amazon.ionhiveserde.IonHiveSerDe' WITH SERDEPROPERTIES ( 'ion.unixtimestamp.path_extractor'='(Item unixtimestamp)', 'ion.evalmessage.path_extractor'='(Item evalmessage)' ) STORED AS ION LOCATION 's3://xxxxx/AWSDynamoDB/aaaa-bbbb/data' |
クエリ
分類したカテゴリ、件数の多い順番に並び替え
|
1 2 3 4 5 6 7 8 9 10 11 12 |
select CASE WHEN json_extract_scalar(json_array_get(evalmessage, 0), '$.Category') IS NULL THEN '未分類' ELSE json_extract_scalar(json_array_get(evalmessage, 0), '$.Category') END AS Category, count(*) as cnt from dynamodb_export_table_with_evaluate group by json_extract_scalar(json_array_get(evalmessage, 0), '$.Category') ORDER by cnt desc |
まとめ
膨大なデータ量の場合ですと、アカウント・リージョンのハード制限のため分散する等のテクニックもあるようですが、そこそこのデータ量であっても、Claude 3 Haikuが高速なため、スケールすれば十分な速度で処理出来る事を確認しました。
今回の例では、1レコードあたり 2~3秒で処理してくれ、下記制限を考慮しても並列度を上げる余地がありました。
Anthropic Claude 3 Haiku
- 1,000 リクエスト /1 分あたり
- 2,000,000 Token /1 分あたり
Amazon Bedrock のクォータ
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/quotas.html
また、費用が高い物を利用しても出力もほぼ変わらずメリットが薄いため、適材適所で生成AIモデルを選定していく必要がある事を実感しました。












