はじめに
前回、AWSアカウントの統合を設定して、AWSのデータをNewRelicへ連携しました。
今回はそのデータを利用して、実際にアラート設定を導入してみようと思います。
アラートを設定するにあたっては、アラートの通知先と通知条件の設定が必要になります。
NewRelic上では、通知先の設定は Destinations および Workflows、通知条件の設定は Alert conditions (Policies) で実施します。
目次
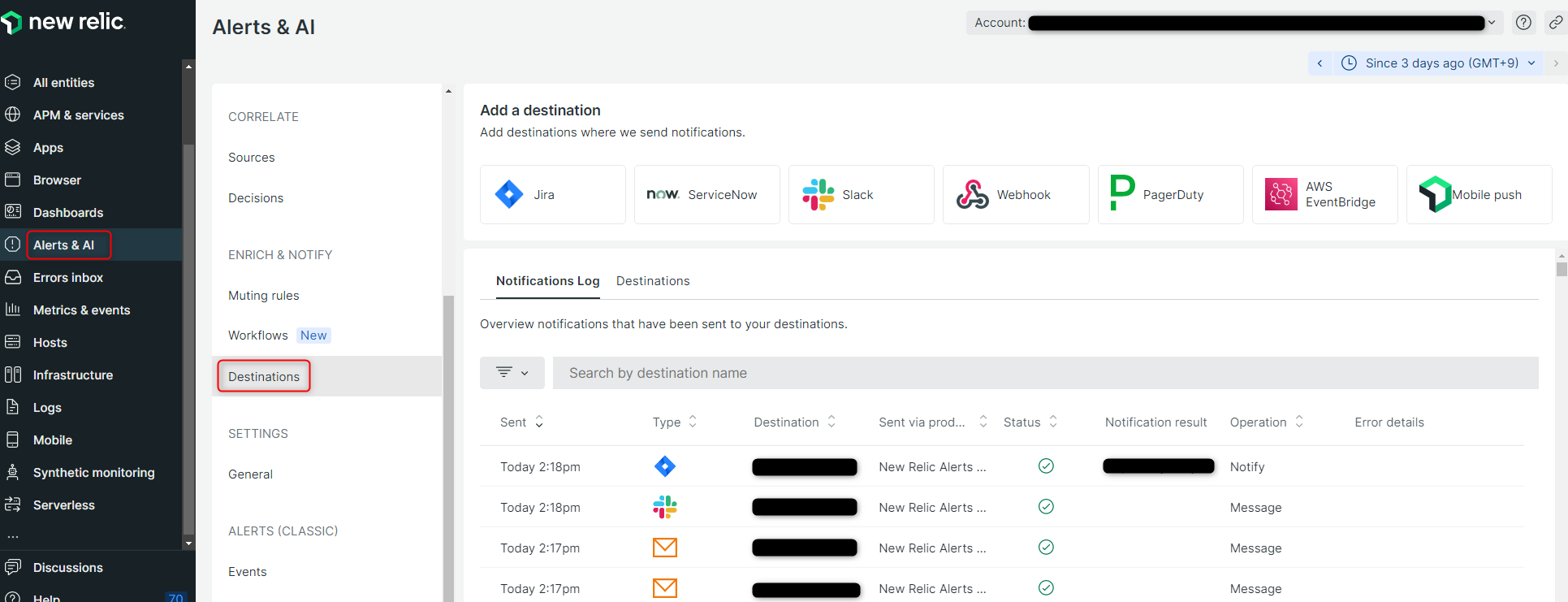
Destinationsの概要
Destinationsは、アラート通知の宛先となるものです。
設定可能な宛先の種別として、EmailやJira、Slackなどがあります。
Alerts & AI ⇒ Destinations と移動して、Destinationsの確認および、Destinationsの追加・削除といった操作が可能です。
なお、宛先の種別のうち、EmailのみDestinationsからではなく後述するWorkflowsから宛先の追加を行う必要があるようです。
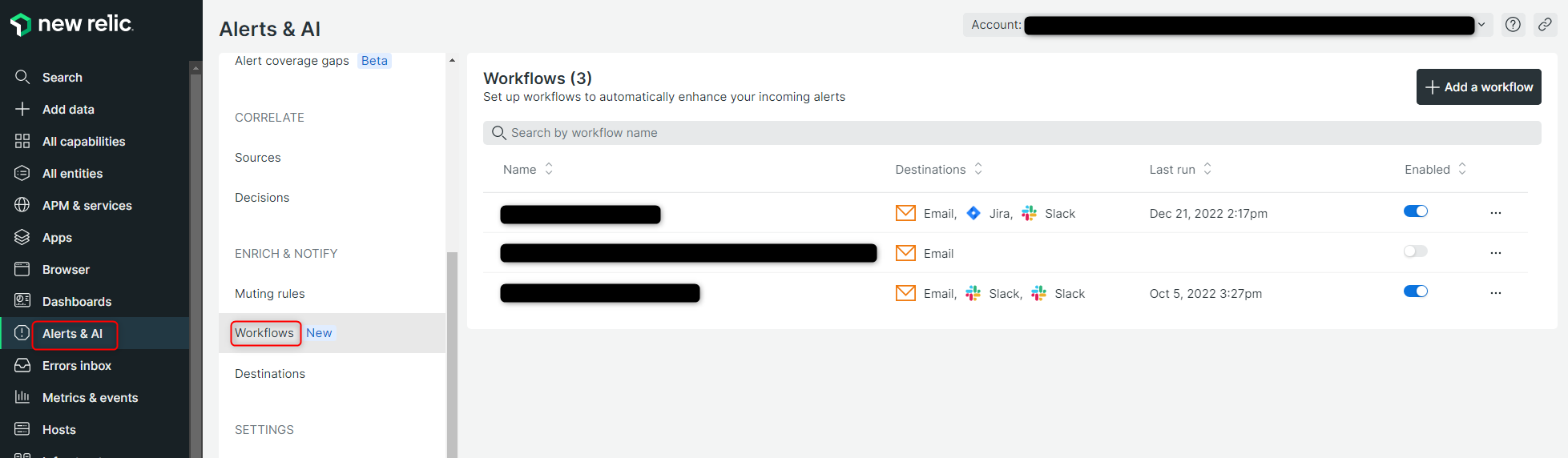
Workflowsの概要
Workflowsでは、NewRelic上で検知されたアラートのうち、どのアラートをどの宛先に通知するかを設定します。
アラートを検知するルールの名前やアラートの緊急度などに基づいて、通知するアラートのフィルタリングを行うことが可能です。
また、宛先については、Destinationsで設定したものの中から選択します。(Emailのみ直接メールアドレスを入力して設定します)
Alerts & AI ⇒ Workflows と移動して、Workflowsの確認・設定が可能です。
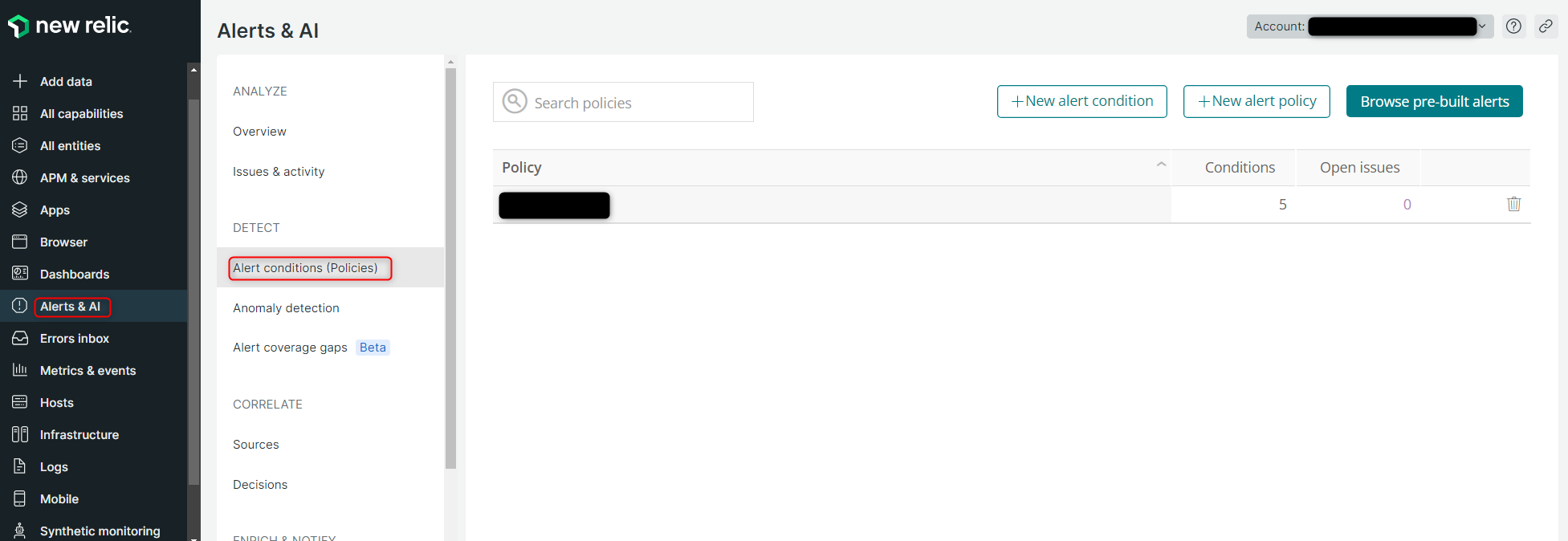
Alert conditions (Policies)の概要
Alert conditions (Policies)では、アラートを検知する条件を設定します。
より正確には、アラートを検知する条件を設定する Condition と、1つ以上のConditionから成る Policy の二つの要素が存在しており、Conditionを作成する際は、必ずPolicyと紐づける必要があります。
今回詳細な説明は割愛しますが、Policyでは、紐づいたConditionから発報されたアラートをNewRelic上でどのようにまとめて管理するかといった設定を行います。
Alerts & AI ⇒ Alert conditions (Policies) と移動して、ConditionやPolicyの確認・設定が可能です。
手順
それでは、実際にNewRelicからアラートを発報する設定を導入してみます。
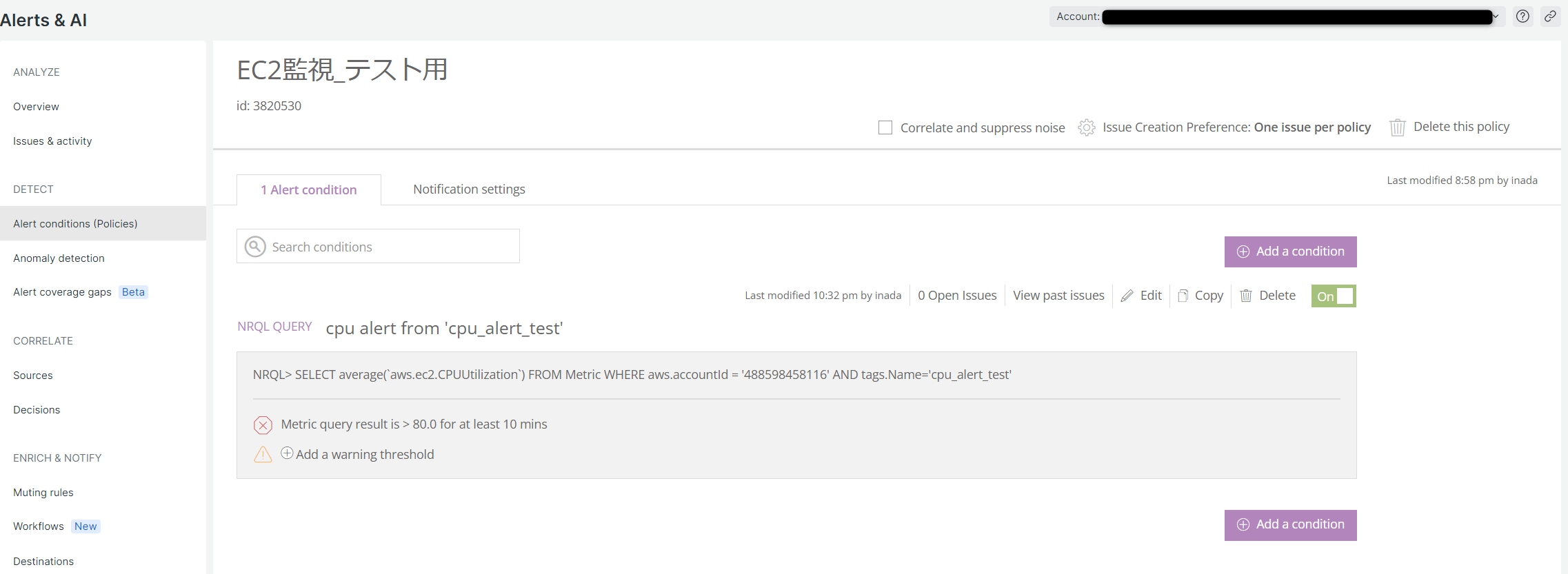
今回は、EC2のCPU使用率80%超過が10分間継続した場合にメール通知がされるような設定を導入してみたいと思います。
まず、Policyの作成から行います。
Alerts & AI ⇒ Alert conditions (Policies) と移動して、New alert policyをクリック。
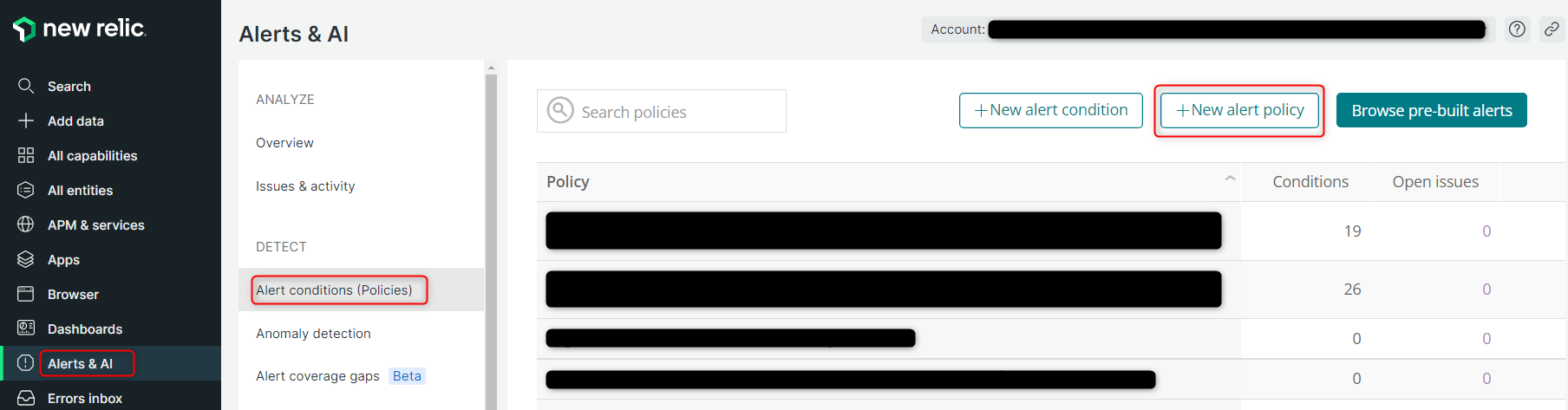
今回はPolicy名を「EC2監視_テスト用」として、その他の設定はデフォルトで「Set up notifications」をクリック
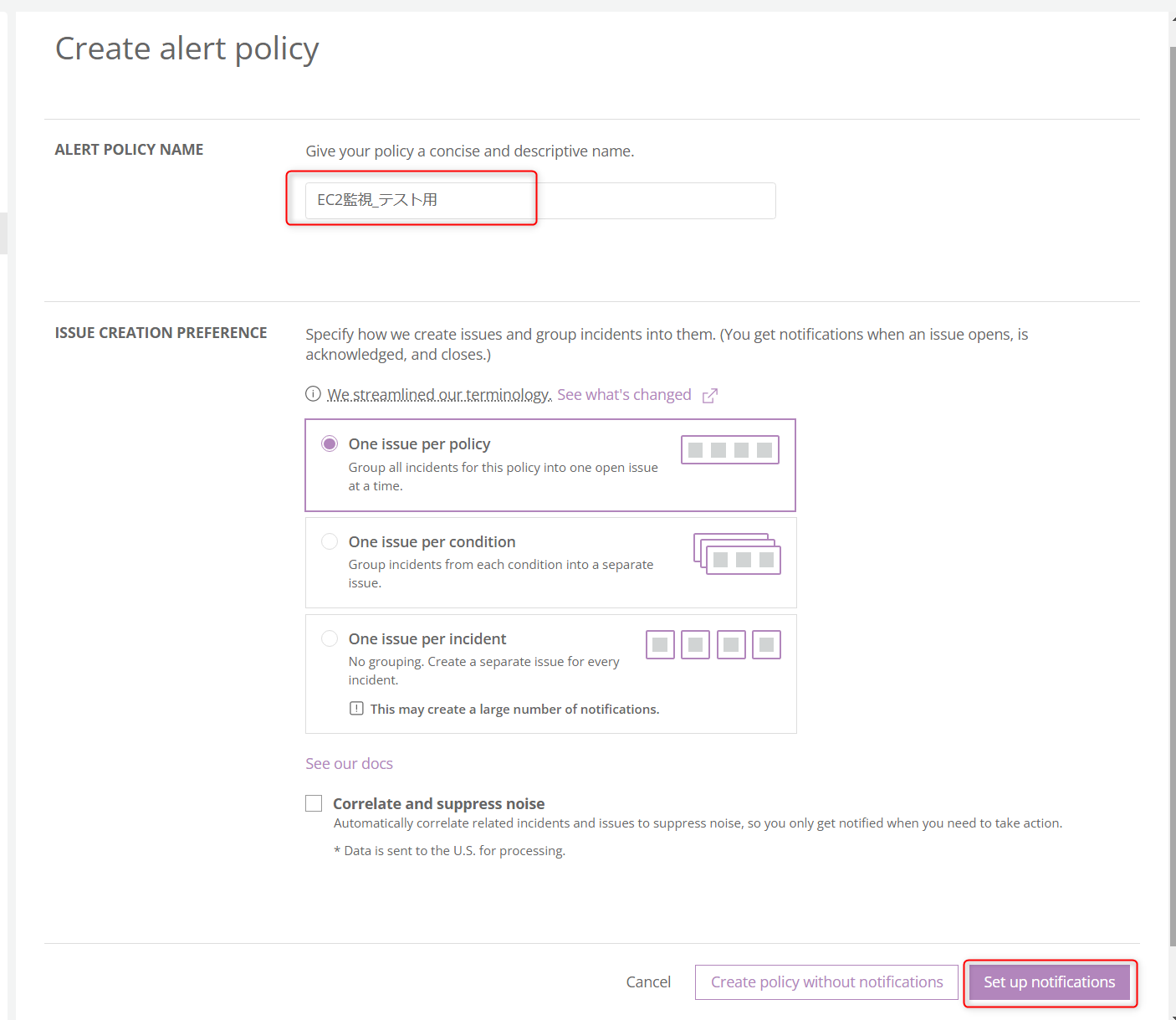
WorkflowsおよびDestinationsをこの画面で合わせて設定できます。
今回はアラート通知を送信したい宛先のメールアドレスを設定して「Activate workflow」をクリック。
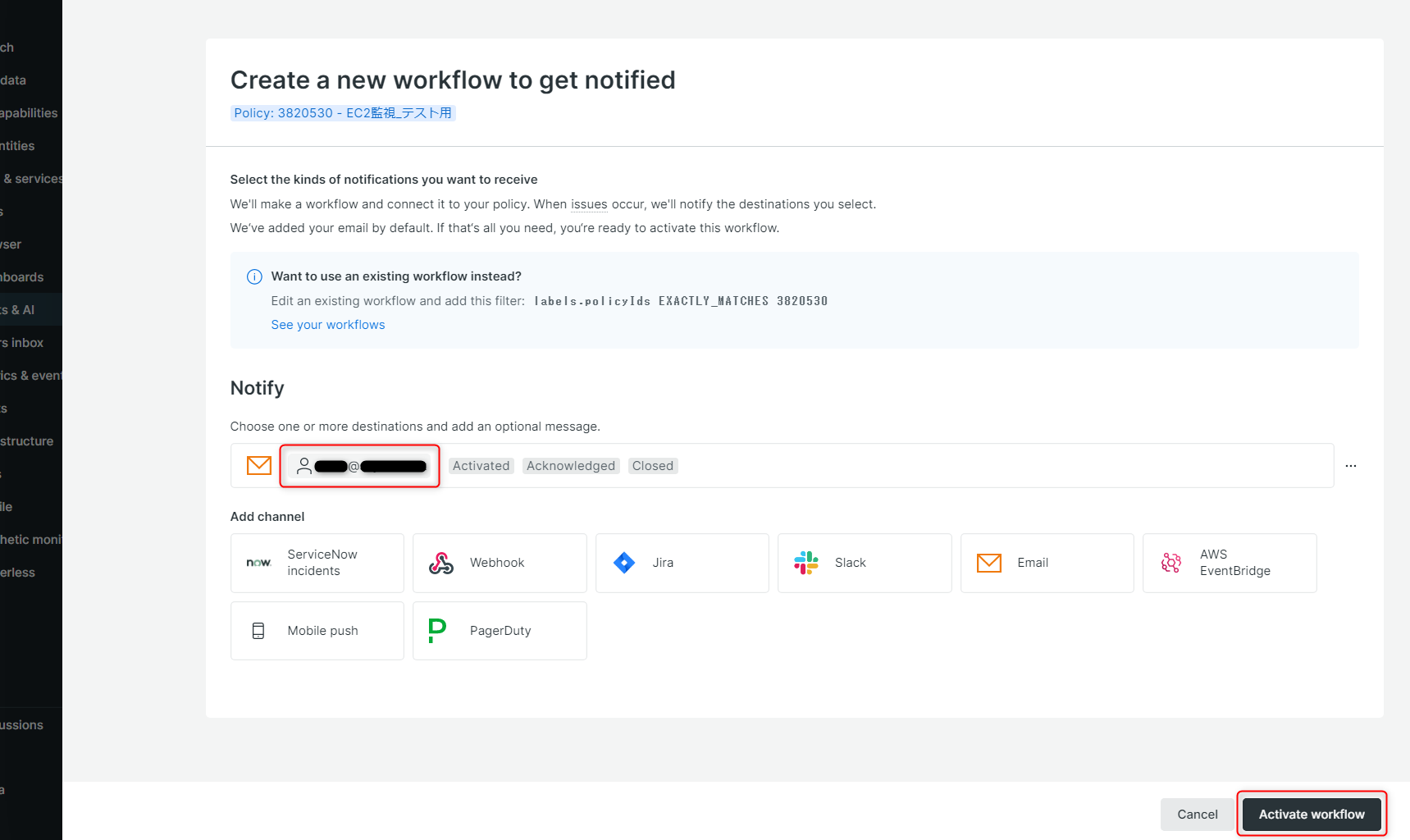
Policyが作成されました。
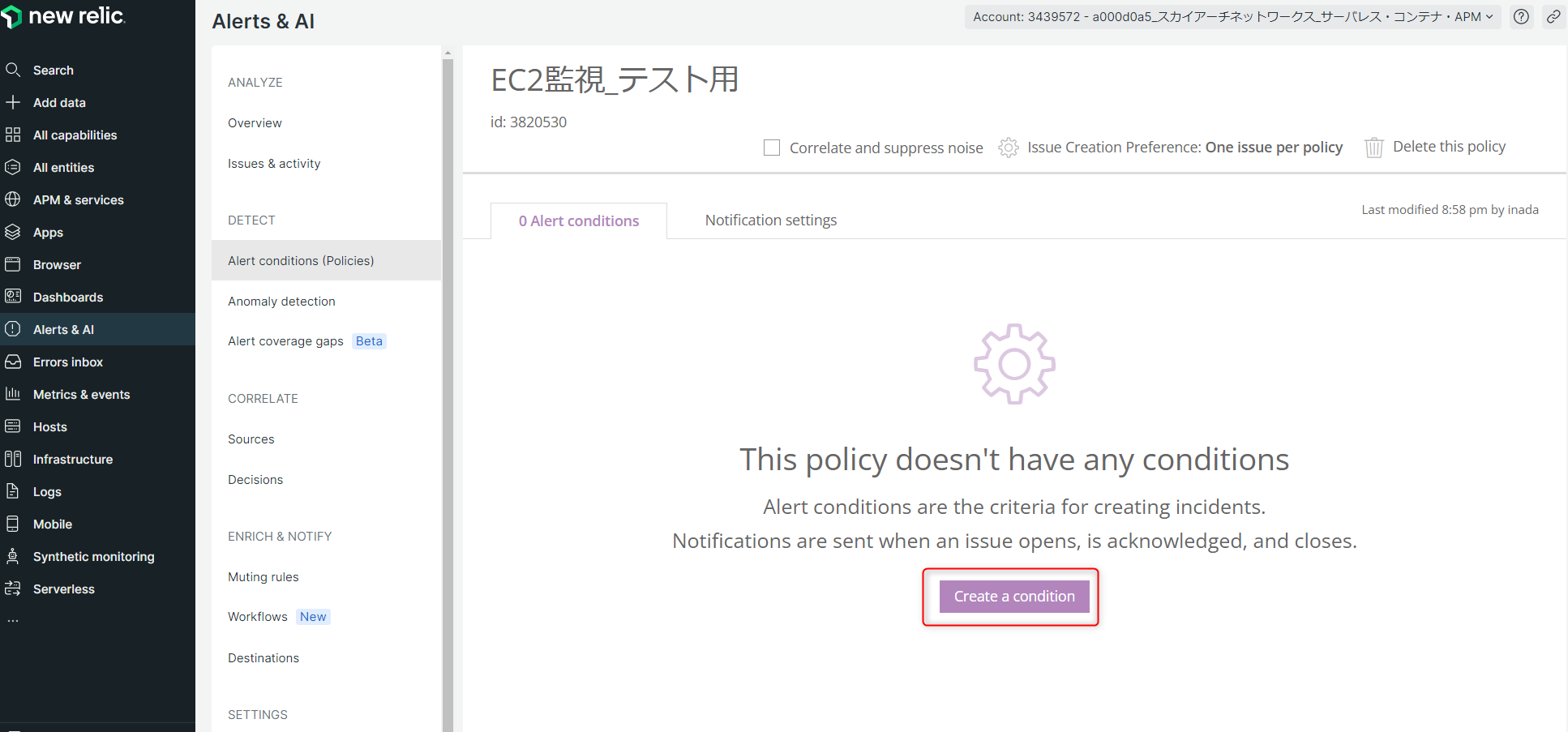
次に、このPolicy配下にConditionを作成します。
「Create a condition」をクリック。
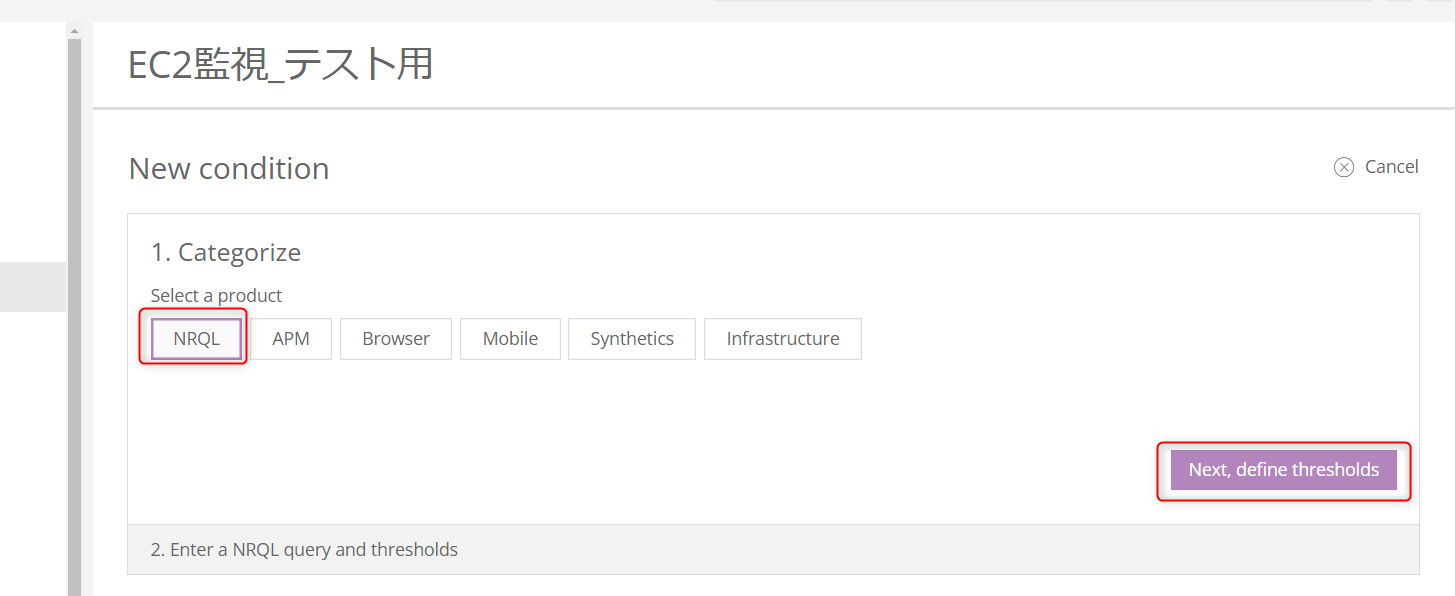
まず、監視する値のカテゴリーを選択します。
今回は「NRQL」を選択し、「Next, define thretholds」をクリックします。
Condition名とNRQLのクエリ文を入力します。
NRQLとは、New Relic Query Languageの略で、NewRelic上のデータをクエリするための、NewRelic独自のクエリ言語です。
NRQLの詳細は別の機会に改めて説明できればと思いますが、今回はAWSのアカウントIDとインスタンスのNameタグ名で対象のデータを絞りこんでいます。
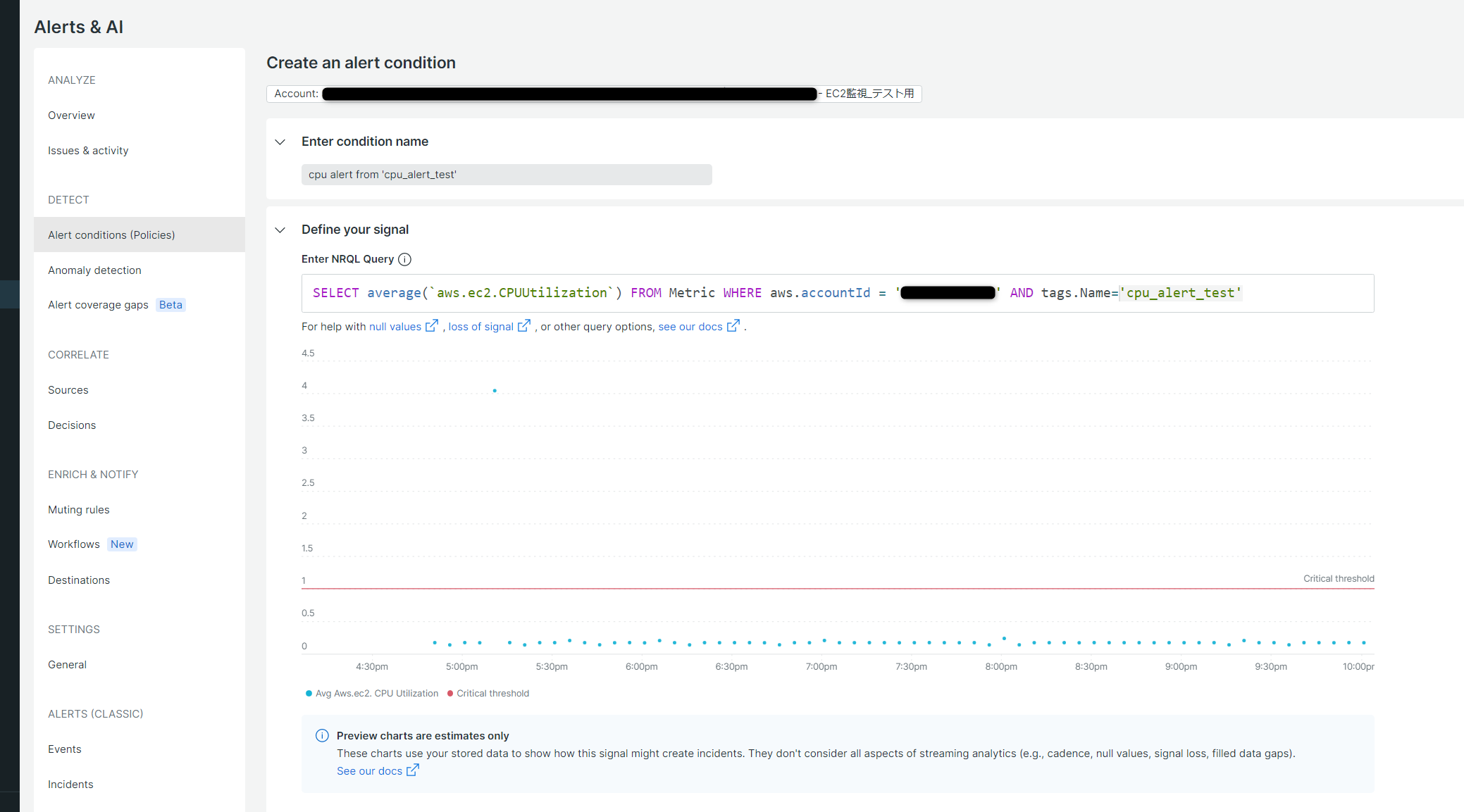
下にスクロールして、アラート発報の閾値の設定を行います。
まず、Threshold typeで閾値のタイプを選択します。
Staticを選択すると固定値の閾値になり、Anomalyを選択すると過去の値を元にして変動する閾値になります。
次に、Priority levelでアラートの緊急度を設定します。(CriticalもしくはWarningから選択)
その下の、When a query returns a valueでは、アラートの実際の閾値を設定します。
複数の閾値を設定したい場合には、Add thresholdをクリックして、設定の追加が可能です。
また、Add lost signal thresholdをクリックして、データが取得されなくなった場合にアラートを発報するように設定を追加できます。
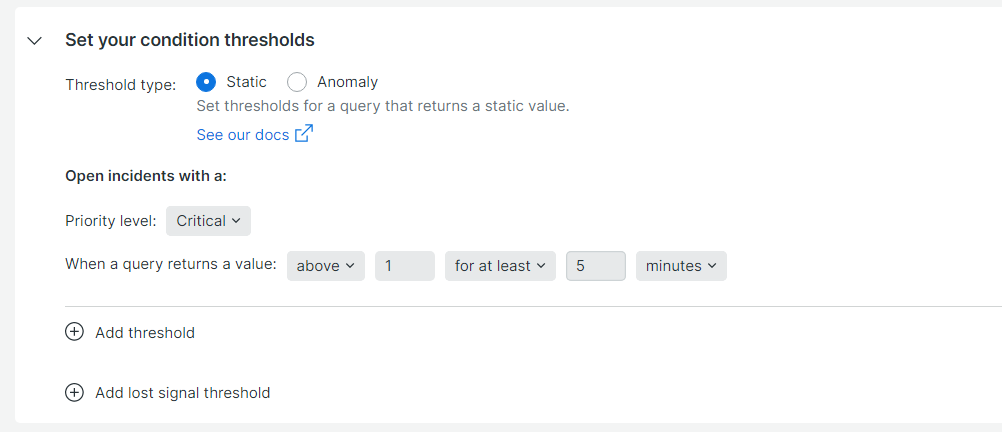
今回は、CPU使用率80%超過が10分間継続した場合にアラートを発報したいので、下記画像のように設定しました。
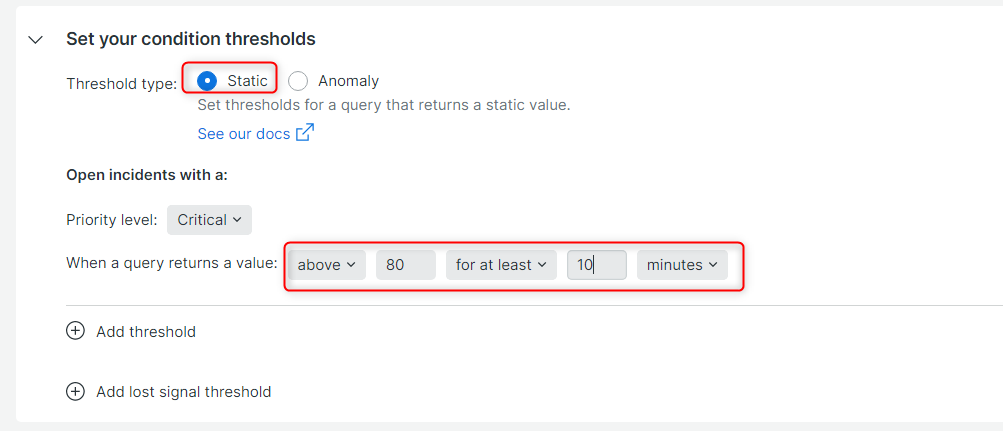
更に下にスクロールして、Window durationをCloudwatchのデータ取得間隔に合わせて5分、その他の箇所はデフォルト値でSave conditionをクリックします。
Data aggregation settingsの設定は、NewRelicが受け取ったデータを内部でどのように処理するかに関わる設定なのですが、こちらも少し複雑なので説明は別の機会に回せればと思います。
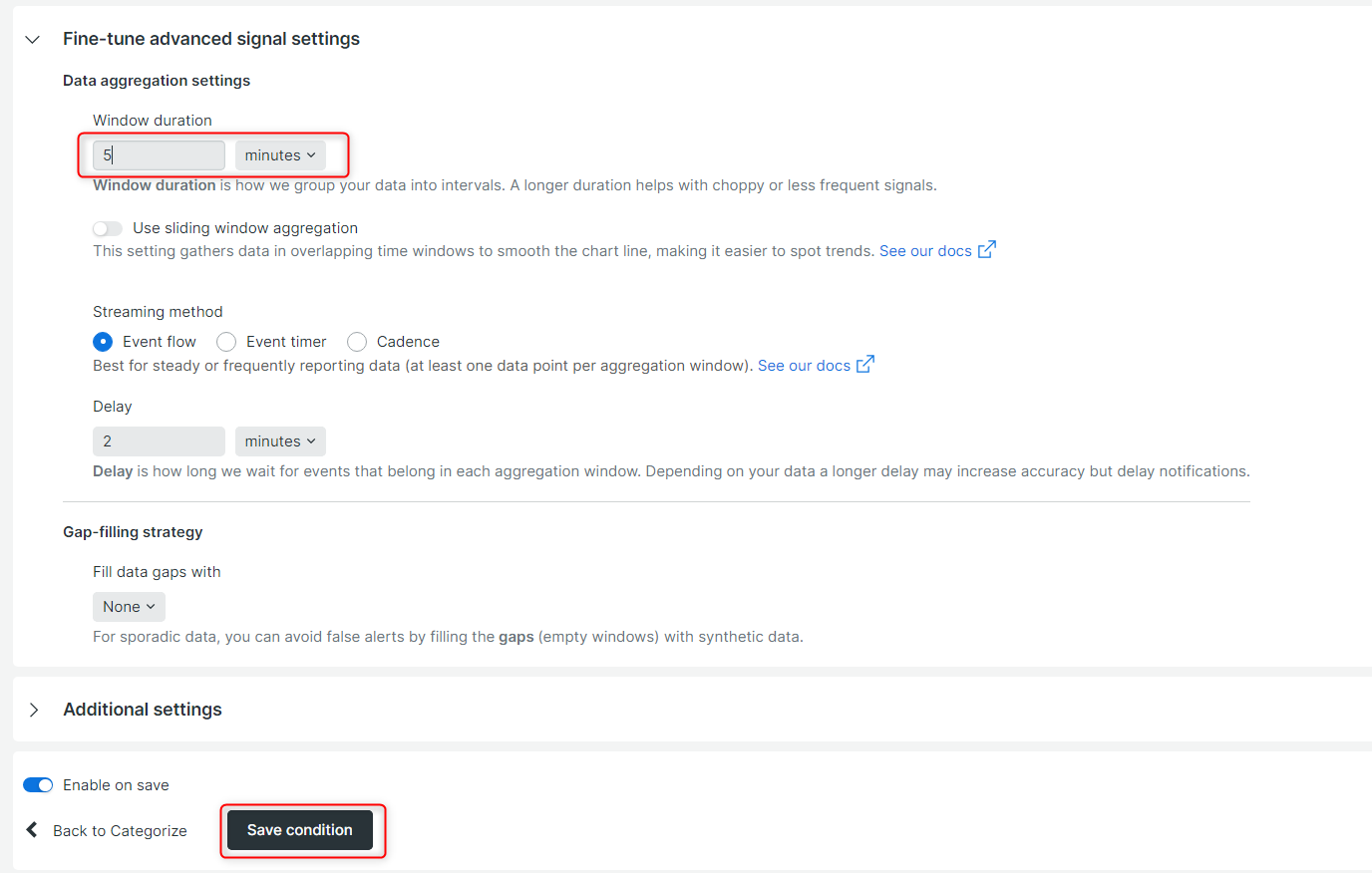
これでConditionが作成されました。
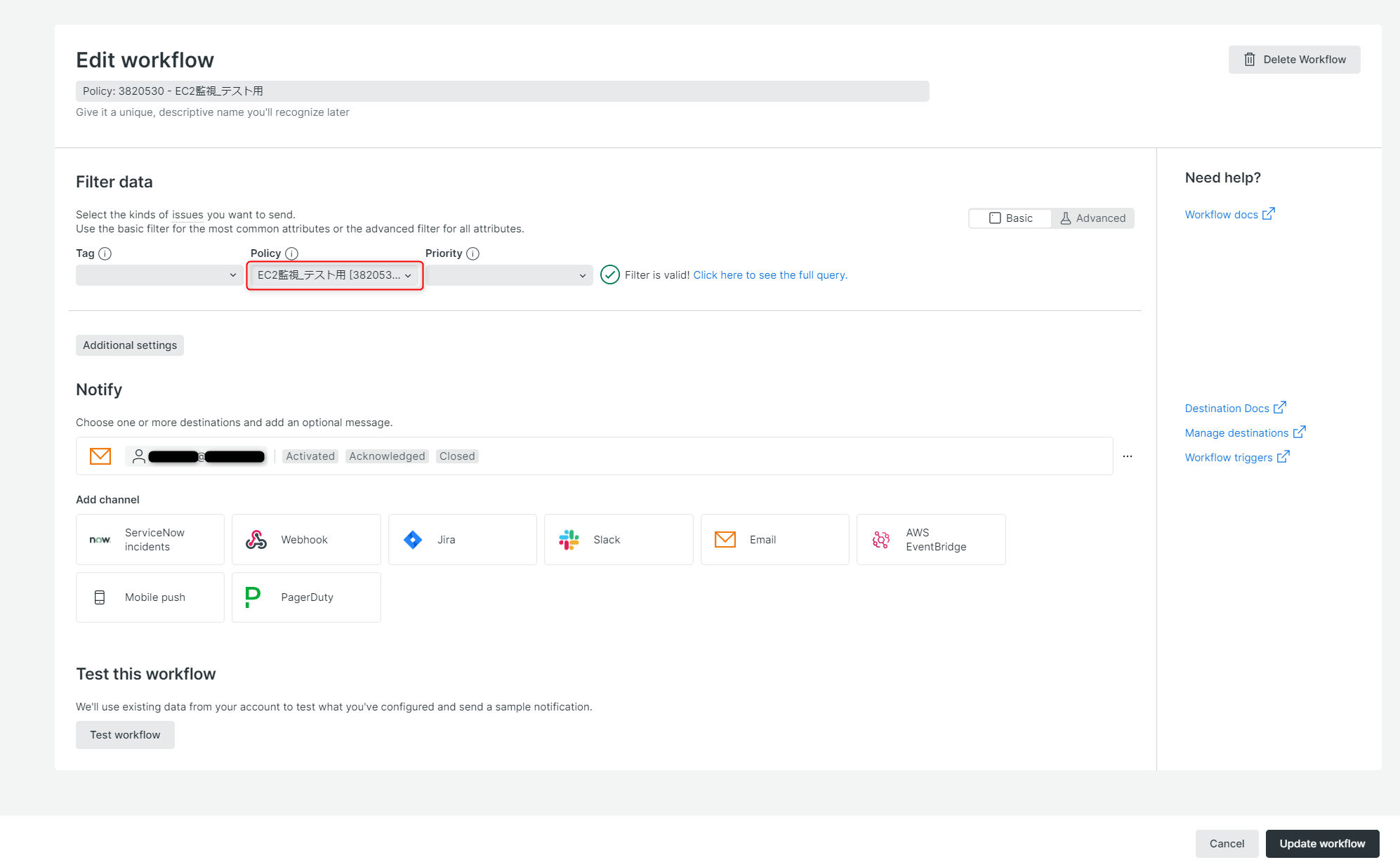
Policyの作成時、Workflows・Destinationsも合わせて作成したので、現時点でアラートの検知およびメール通知がされる状態になっています。
※Policyの方からWorkflowsを作成したためか、Workflowsでのアラートのフィルター条件は、同時に作成したPolicyの名前でフィルターするように設定されていました。
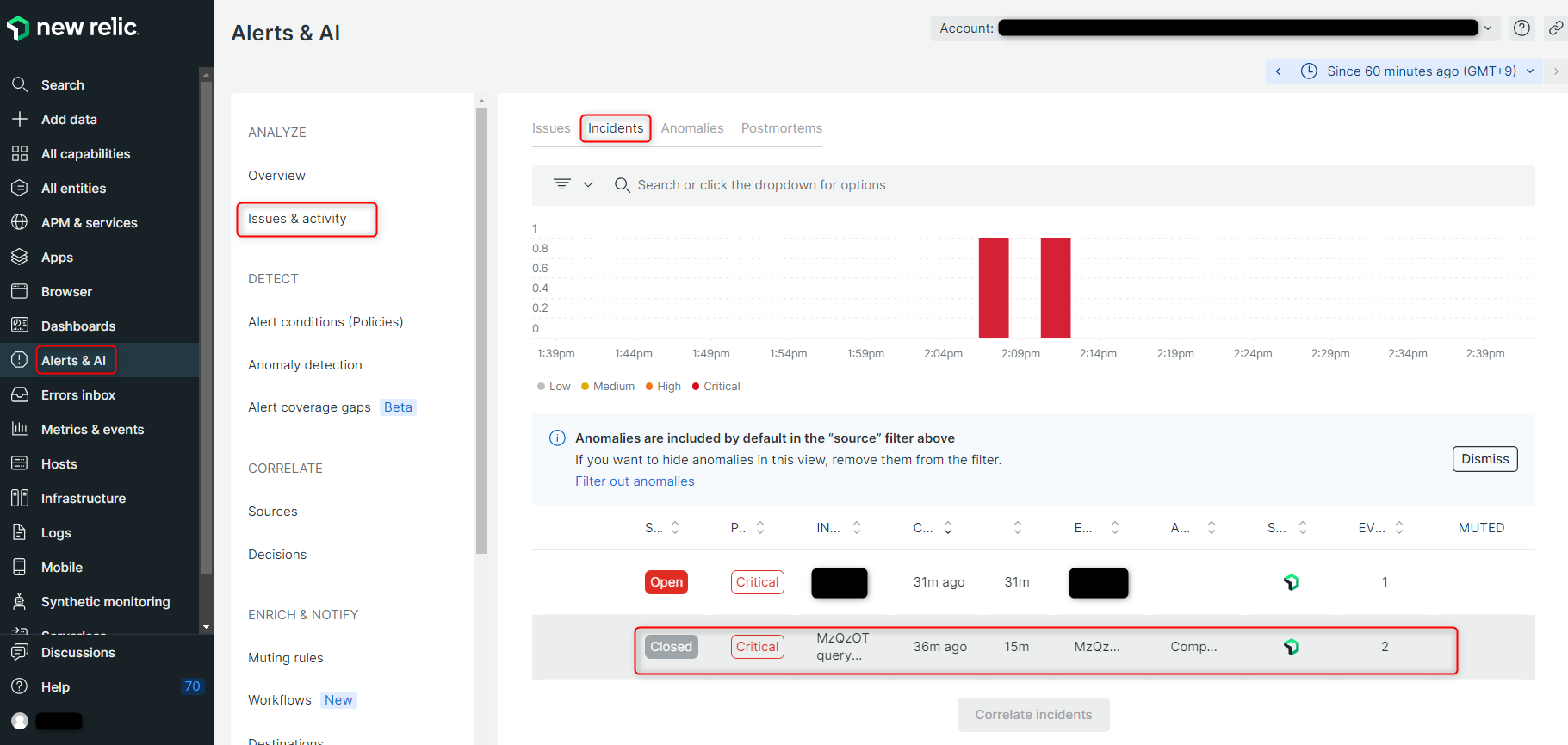
その後、実際に対象のサーバ内でstressコマンドを使用して一時的にCPU使用率を上げたところ、設定したメールアドレス宛にアラート通知(および復旧の通知)が届いたことを確認できました。

Alerts & AI ⇒ Issues & activity ⇒ Incidents と進んで、NewRelic上でも対象のアラートの情報を確認できました。
まとめ
今回NewRelic上でアラートを発報する設定を導入してみました。
必要なデータがNewRelic上に連携されている状態でCondition(Policy)とWorkflows、Destinationsを設定すればアラートの通知を実施できるということは伝えられたのではないかと思いますが、
実際にNewRelic上で独自のアラートを設定していくうえでは、今回説明を省いたNRQLなどの理解も必要になってくるので、今後改めてその辺りを記事にできればと思います。


