はじめに
SageMakerについて学習のためブログ投稿しました。
今回はデータセットを用意するだけで、データに基づいて最適なモデルを自動で構築してくれるSageMaker AutopilotというAutoML機能を使ってみます。
目次
概要
AWS公式が提供しているこちらのチュートリアルに沿って進めていきます。
Amazon SageMaker Studioをセットアップする
SageMaker StudioとはSageMakerで使用できるIDE(統合開発環境)です。
記事の本題とは逸れるので、SageMaker Studioをセットアップした状態からチュートリアルを実施します。
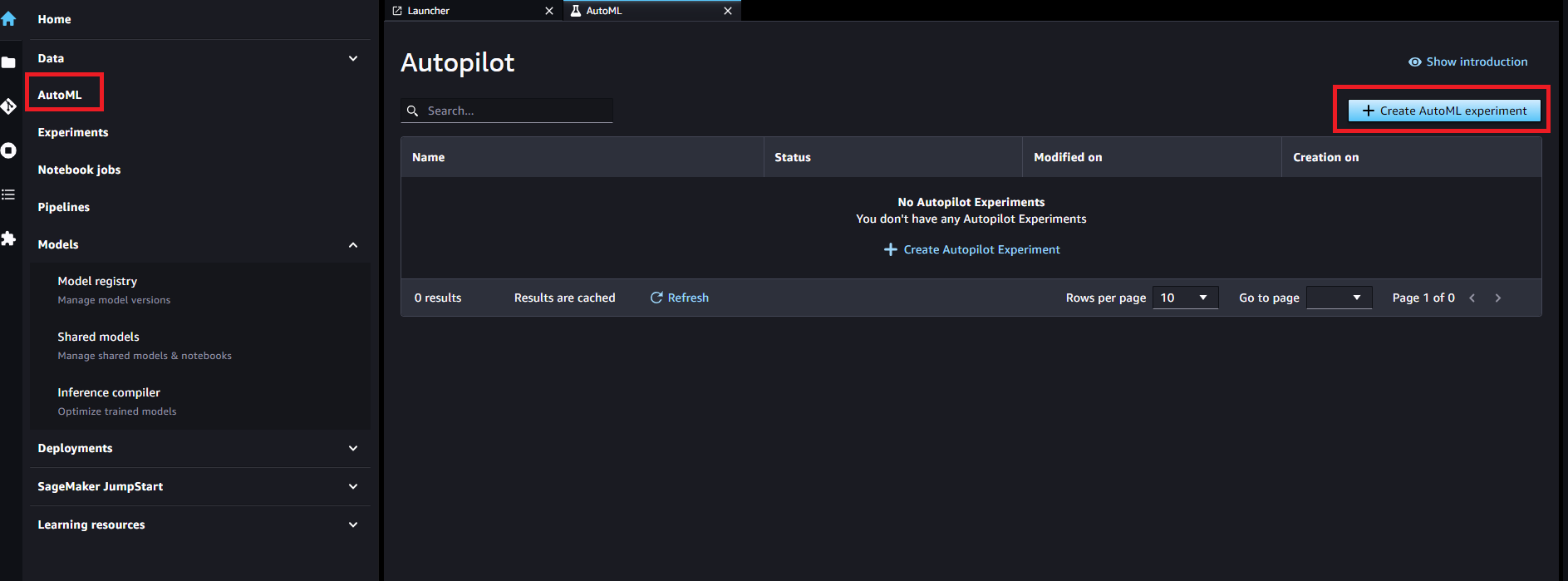
データセットをダウンロードする
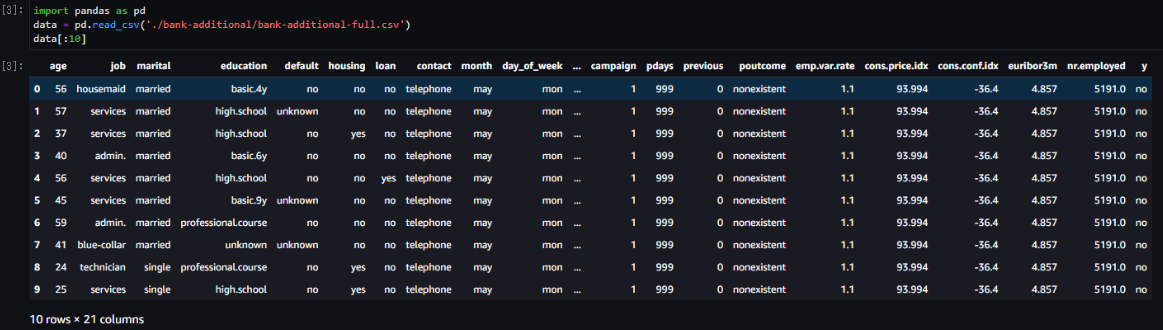
チュートリアルで使用するデータセットをダウンロードして、任意のS3バケットにzip展開しておきましょう。
SageMaker Autopilotを使用する
SageMaker Studioに戻って、SageMaker Autopilotを開始します。
「Create AutoML experiment」から開始します。
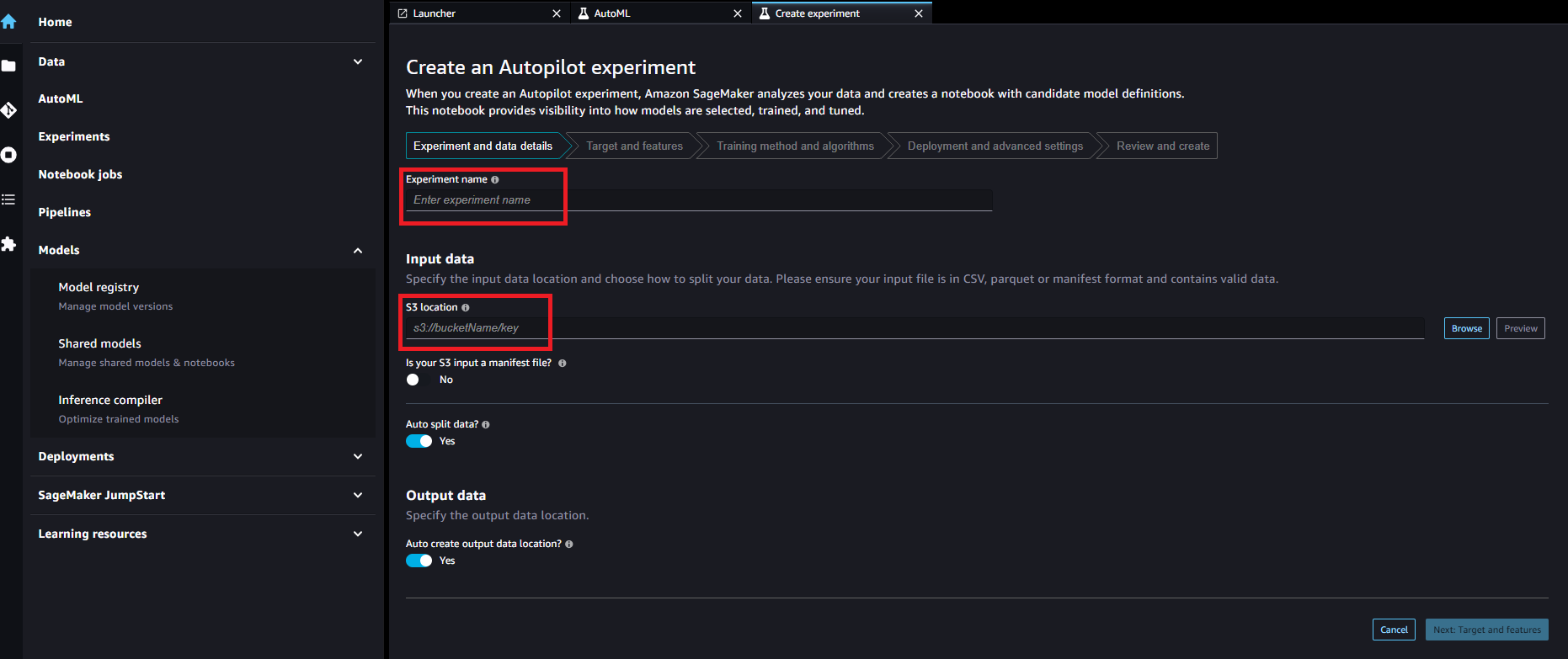
Create an Autopilot experiment(Experiment and data details)
「Input data」には先ほどダウンロードした学習データを選択します。
Create an Autopilot experiment(Target and features)
「Target」には予測するターゲットを選択(y)し、「Features」には学習で使用するデータを選択(今回はy以外の全て)します。
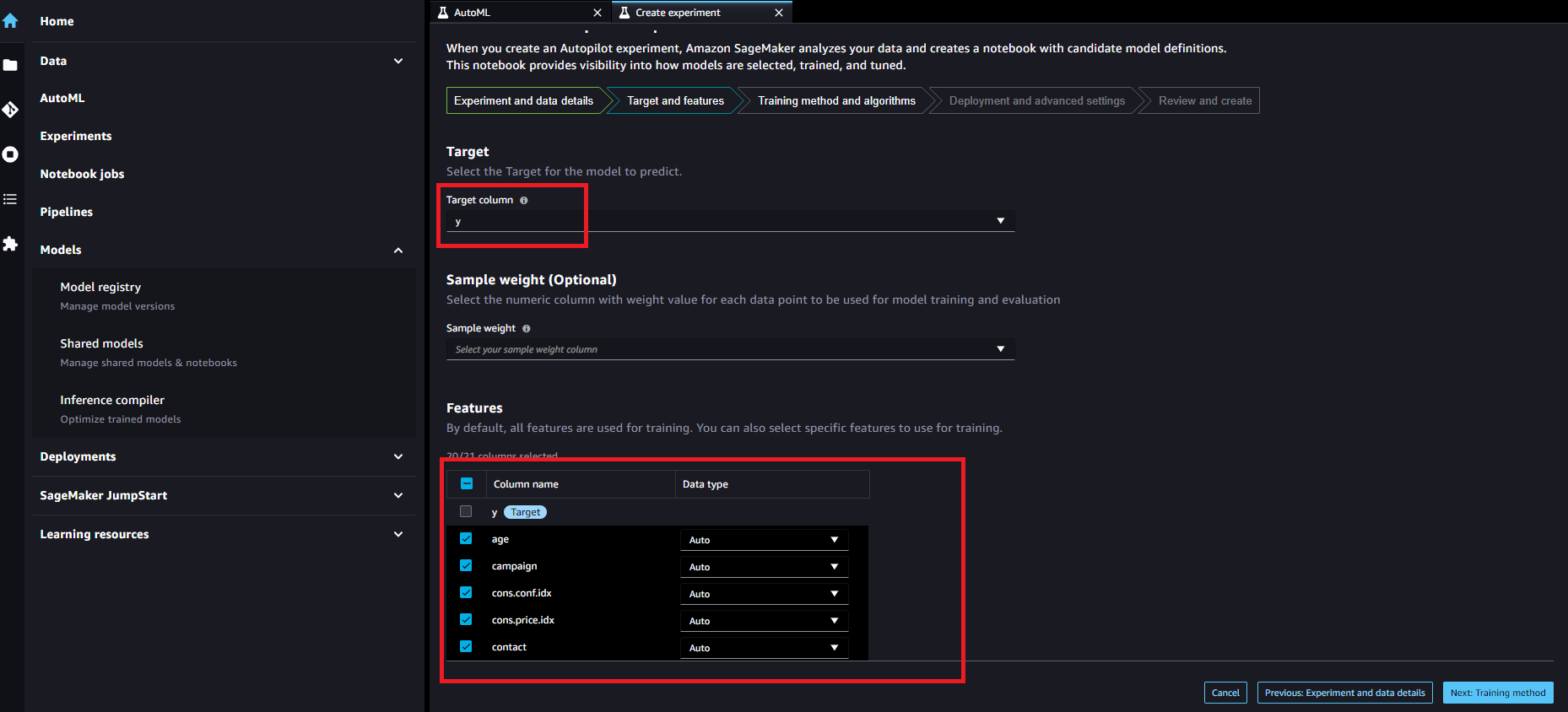
Create an Autopilot experiment(Training method and algorithms)
「Training method and algorithms」は「Auto」を選択したままにします。学習時間短縮のためにチューニングしたいアルゴリズムを絞ることができます。
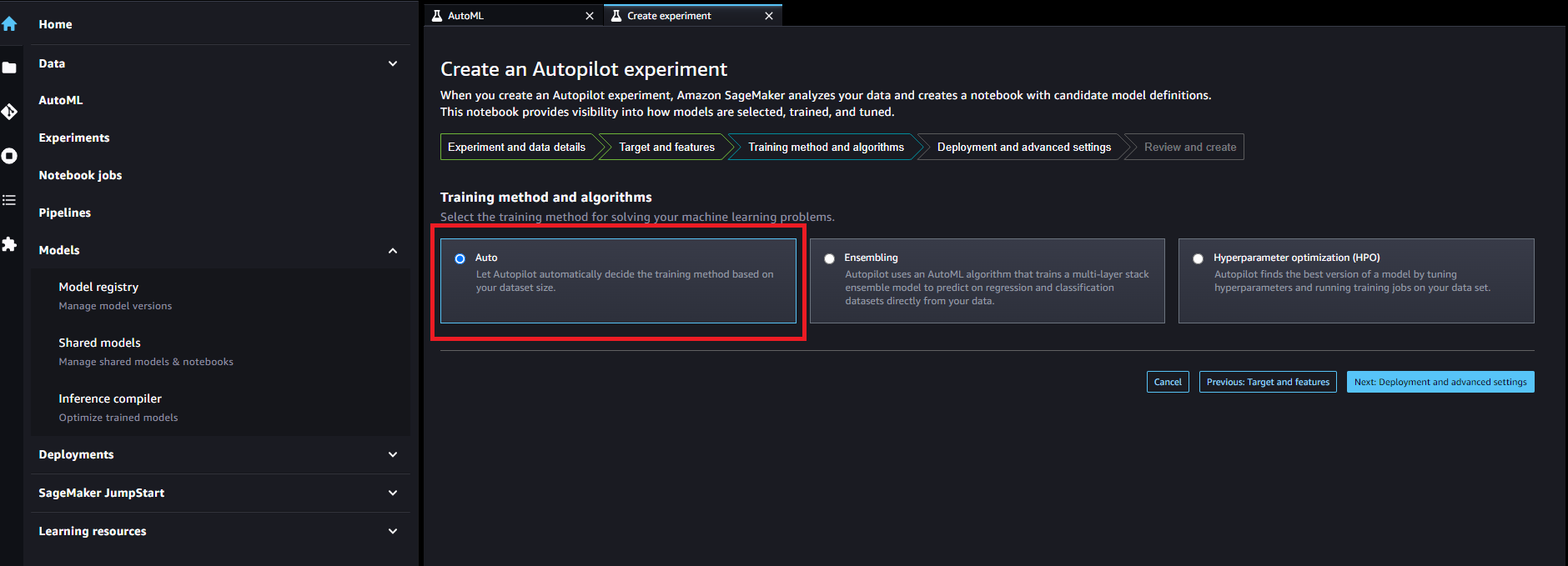
Create an Autopilot experiment(Deployment and advanced settings)
「Auto deploy」を「yes」のままにした場合、一番精度が良いと判断したモデルを自動デプロイ、エンドポイント作成まで実行します。モデルのデプロイとエンドポイント作成を手動で実施したい場合は「no」に変更しましょう。
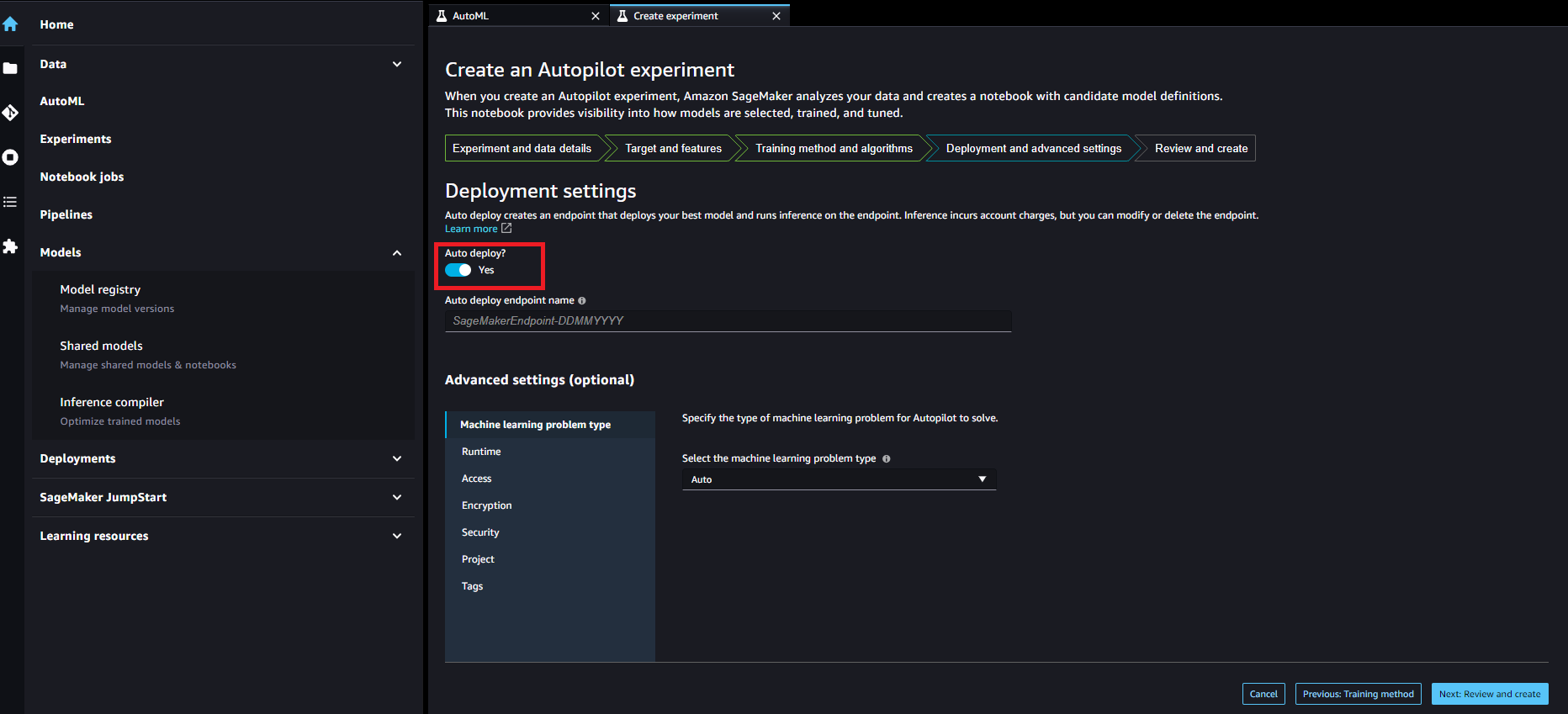
Create an Autopilot experiment(Review and create)
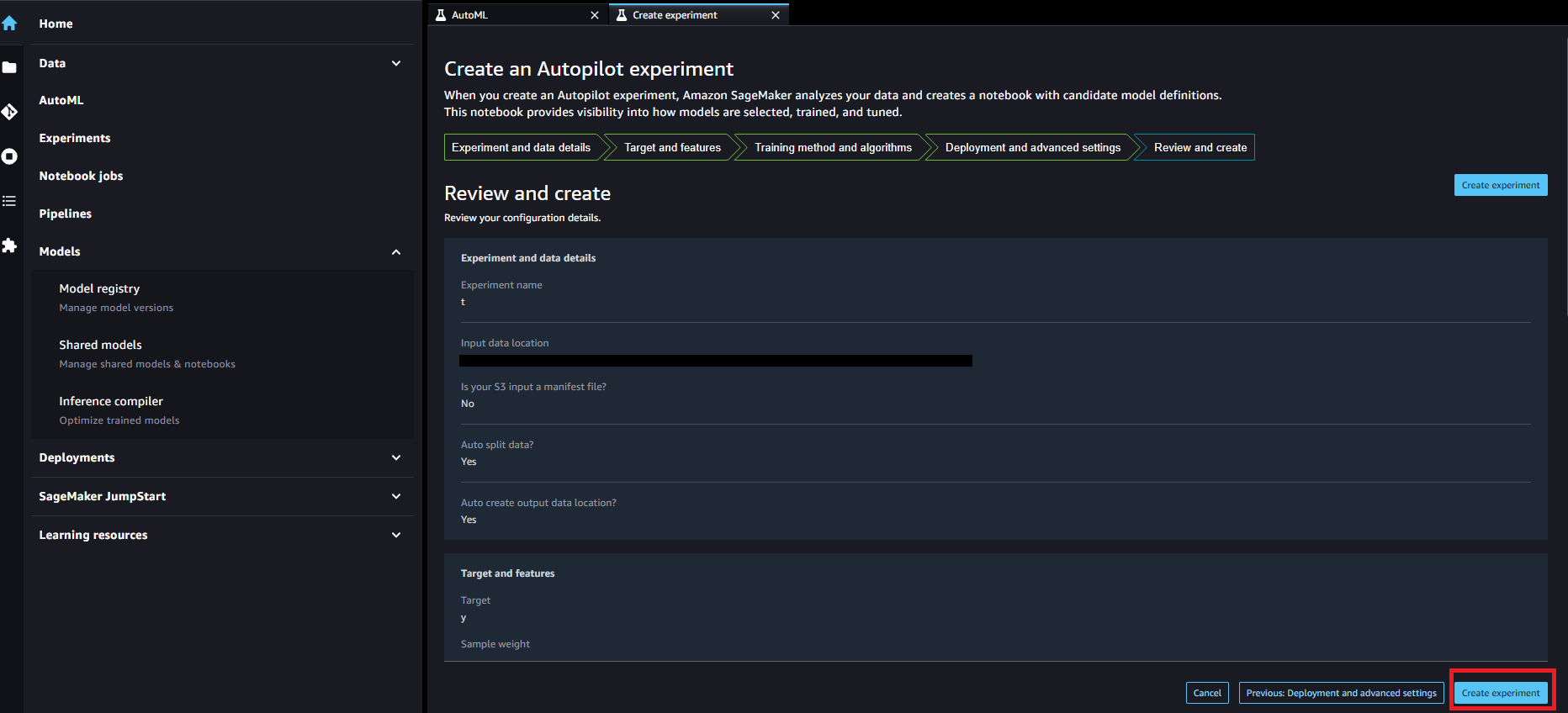
設定内容を最終確認し、問題なければ「Create experiment」を実行して、「Status」がCompletedになるまでしばらく待ちましょう。
作成したモデルを確認する
自動でパラメーターチューニングされて作成されたモデル一覧が確認できます。「Best model」と記載されている一番精度が高いモデルを確認することもできます。
また、「Open data exploration notebook」からデータセットの分析レポート、「Open candidate generation notebook」からモデル再定義カスタマイズ可能なNotebookを生成することができます。
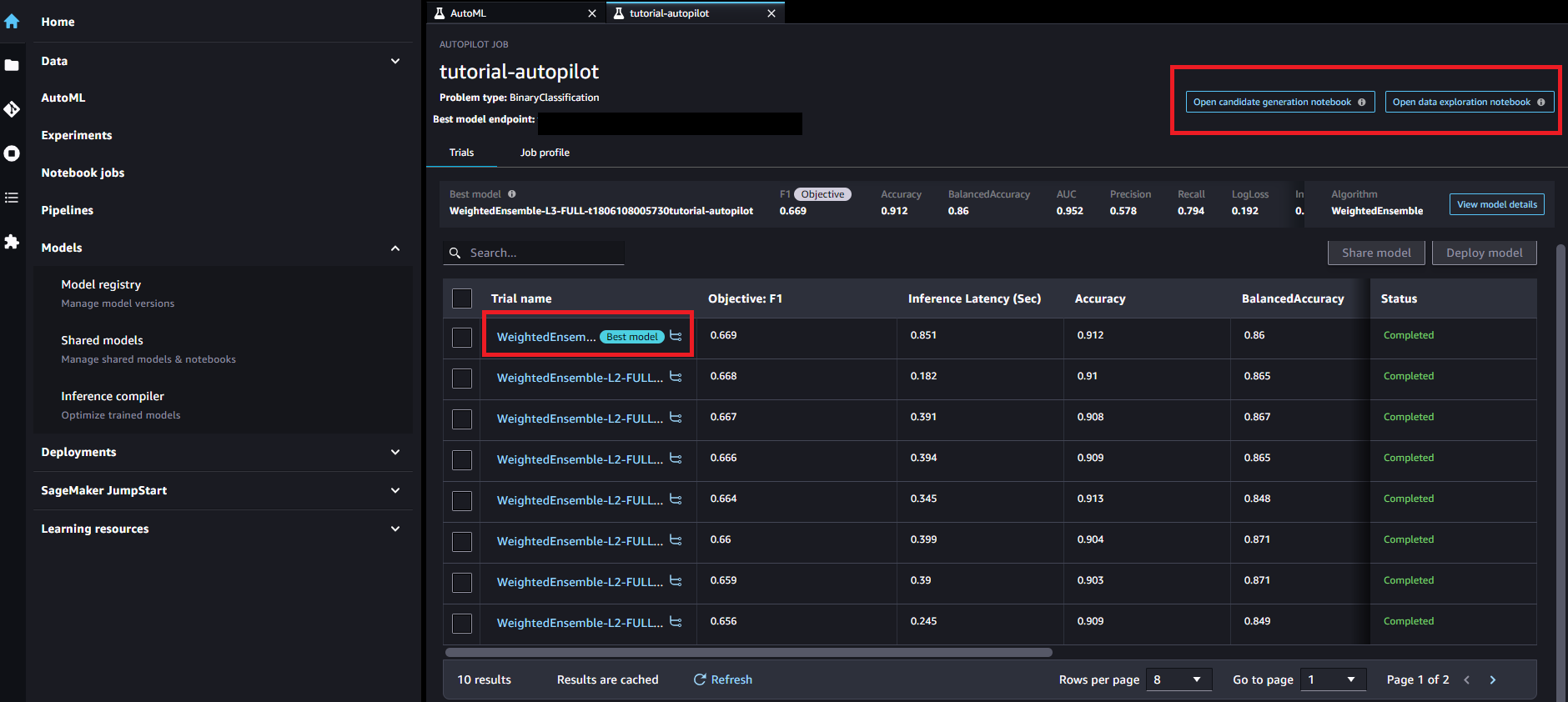
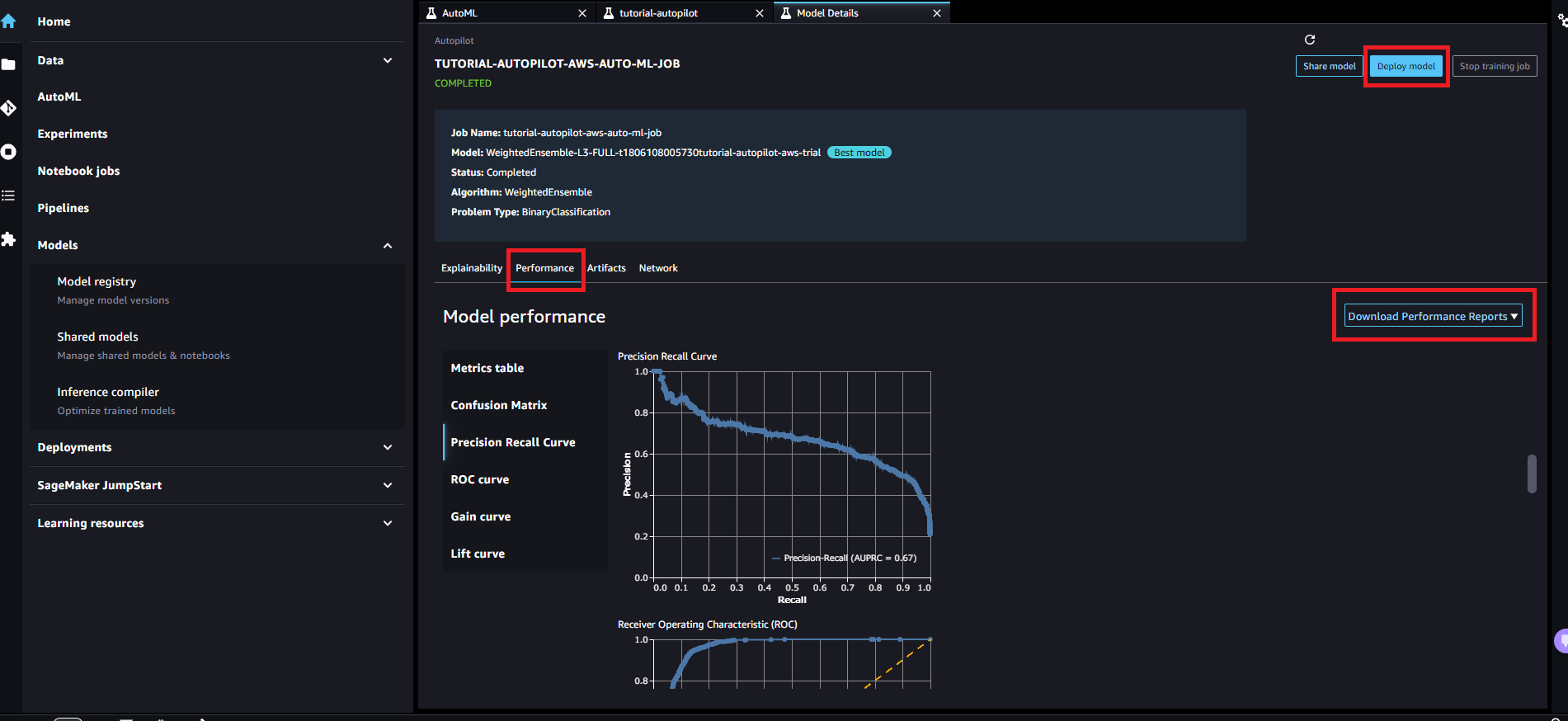
作成されたモデルを選択すると、詳細が確認できます。「Deploy model」から手動デプロイ、エンドポイント作成を実施できます。
また、「Performance」タブから、モデルの詳細な精度を図示可して確認することもできます。「Download Performance Reports」から作成されたモデルの詳細レポートを出力することもできます。
まとめ
メリット
- ノーコードで、データセットを投入するだけで利用可能。データ分割、モデル構築、モデル最適化、デプロイまで数クリックで完結する。
- 作成したモデルを再現可能。カスタマイズしてパラメーターチューニング可能なJupyter notebookを生成してくれる。
- データセットの分析レポート、構築したモデルの分析レポートを生成・可視化してくれる。
デメリット
- すべての問題解決ができるわけではない(回帰、二値分類、マルチクラス分類のみ対応している)。
データセットを用意すれば、自動でモデルを構築、モデルを再現可能なNotebook生成、詳細なレポートまで出力してくれるのは非常に至れり尽くせりだと感じました。
また、モデルを細かくカスタマイズしたい場合はNotebook上でコードベースに修正することもできるので、AIに詳しくない非AIエンジニアからAIエンジニアまで幅広いユーザーが利用できる便利なAutoML機能だと思いました。
投稿者プロフィール
最新の投稿
 AWS2023年11月15日SageMaker Autopilotをやってみた(tutorial 編)
AWS2023年11月15日SageMaker Autopilotをやってみた(tutorial 編)