はじめに
PythonからMySQLにアクセスする際にSQLAlchemyを使用しているのですが、100万件ほどの大量データをINSERTする場合に処理時間が非常に長くかかってしまったため、高速化に取り組んでみました。
目次
実行環境
- requirements.txt
|
1 2 |
sqlalchemy==2.0.23 pymysql==1.1.0 |
- DB
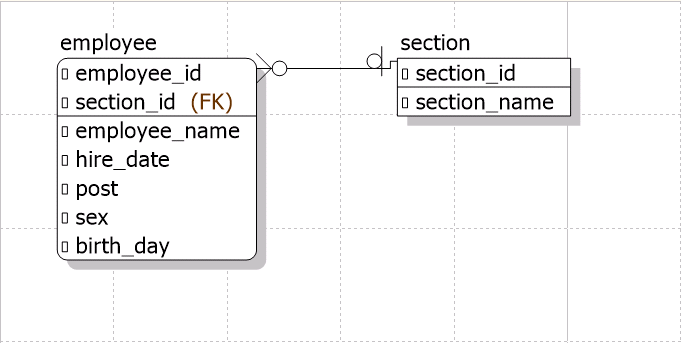
下図のようなシンプルな構成です。
employeeテーブルに100万件INSERTします。
-
Database
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import scoped_session, sessionmaker # 接続先DBの設定 DATABASE = "mysql+pymysql://{username}:{password}@{hostname}/{database}?charset={charset}" # Engine の作成 Engine = create_engine(DATABASE, echo={echo}, pool_recycle={recycle}) Base = declarative_base() # Sessionの作成 session = scoped_session(sessionmaker(autocommit=False, autoflush=False, bind=Engine, info={"in_transaction": False})) |
- Model
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from datetime import datetime from database.database import Base from sqlalchemy import Column from sqlalchemy.dialects.mysql.types import INTEGER, CHAR, VARCHAR, DATETIME class Employee(Base): __tablename__ = "employee" employee_id: Column[int] = Column(INTEGER, primary_key=True, nullable=False, autoincrement=True) section_id: Column[str] = Column(VARCHAR(10), primary_key=True, nullable=False) employee_name: Column[str] = Column(VARCHAR(64), nullable=False) hire_date: Column[datetime] = Column(DATETIME, nullable=False) post: Column[str] = Column(CHAR(2), nullable=False) sex: Column[str] = Column(CHAR(1), nullable=False) birth_day: Column[datetime] = Column(DATETIME, nullable=False) |
- 100万件データ
CSVファイルに100万行のデータを用意してPythonでCSVを読み込みます。
|
1 2 3 4 |
section_id,employee_name,hire_date,post,sex,birth_day SEC0000001,sample_name_1,2023-04-01,0,1,2000-01-01 SEC0000001,sample_name_2,2023-04-01,0,1,2000-01-01 ... |
困ったこと
下記のように1件ずつINSERTしようとすると30分経っても終わらず処理時間がかなり長くなります。
(逐次COMMITしているので当然といえば当然ですが…)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
import csv from datetime import datetime from database.database import session from model.employee import Employee def get_insert_data(): with open("data/employee.csv", newline="") as data: rows = csv.reader(data) next(rows, None) return [ Employee( section_id=row[0], employee_name=row[1], hire_date=row[2], post=row[3], sex=row[4], birth_day=row[5] ) for row in rows ] # 100万件CSVからデータ行をlist形式で取得 rows = get_insert_data() # 開始時間を取得 start_datetime = datetime.now() # 100万件登録(add) for row in rows: session.add(row) session.commit() # 終了時間を取得 finish_datetime = datetime.now() # 処理時間を出力 print("処理時間: " + str(finish_datetime - start_datetime)) |
処理時間:30分以上(途中で中断しました)
高速化してみました
そこで、下記4通りの方法でそれぞれ処理時間を計測してみました。
複数件を一度にINSERTする方法
「add_all」を使用することで複数件を一度にINSERTすることができるようです。
これにより逐次COMMITがなくなり、結果も18分程度と処理時間の改善はされましたが、まだまだ改善の余地はありそうです。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import csv from datetime import datetime from database.database import session from model.employee import Employee def get_insert_data(): with open("data/employee.csv", newline="") as data: rows = csv.reader(data) next(rows, None) return [ Employee( section_id=row[0], employee_name=row[1], hire_date=row[2], post=row[3], sex=row[4], birth_day=row[5] ) for row in rows ] # 100万件CSVからデータ行をlist形式で取得 rows = get_insert_data() # 開始時間を取得 start_datetime = datetime.now() # 100万件登録(add_all) session.add_all(rows) session.commit() # 終了時間を取得 finish_datetime = datetime.now() # 処理時間を出力 print("処理時間: " + str(finish_datetime - start_datetime)) |
処理時間:0:18:20.953209(約18分20秒)
一括INSERTする方法
「bulk_save_objects」を使用することで一括INSERTすることができるようです。
これにより処理時間が1分もかからず、かなりの高速化ができました!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
import csv from datetime import datetime from database.database import session from model.employee import Employee def get_insert_data(): with open("data/employee.csv", newline="") as data: rows = csv.reader(data) next(rows, None) return [ Employee( section_id=row[0], employee_name=row[1], hire_date=row[2], post=row[3], sex=row[4], birth_day=row[5] ) for row in rows ] # 100万件CSVからデータ行をlist形式で取得 rows = get_insert_data() # 開始時間を取得 start_datetime = datetime.now() # 100万件登録(bulk_save_objects) session.bulk_save_objects(rows) session.commit() # 終了時間を取得 finish_datetime = datetime.now() # 処理時間を出力 print("処理時間: " + str(finish_datetime - start_datetime)) |
処理時間:0:00:39.395299(約39秒)
Core機能を使用してINSERTする方法
一括INSERTでも十分早いのですが、SQLAlchemyのCore機能である「sqlalchemy.core」を使用することで処理の高速化を実現できます。
これまでと違い、データ型がdict型になります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
import csv from datetime import datetime from database.database import session from model.employee import Employee def get_insert_data_dict(): with open("data/employee.csv", newline="") as data: rows = csv.DictReader(data) return [row for row in rows] # 100万件CSVからデータ行をdict形式で取得 rows = get_insert_data_dict() # 開始時間を取得 start_datetime = datetime.now() # 100万件登録(sqlalchemy.core) session.execute(Employee.__table__.insert(), rows) session.commit() # 終了時間を取得 finish_datetime = datetime.now() # 処理時間を出力 print("処理時間: " + str(finish_datetime - start_datetime)) |
処理時間:0:00:24.264684(約24秒)
INSERTステートメントを使用する方法
SQLAlchemyのINSERTステートメントを使用することで高速化する方法があるようです。
ORM 一括 INSERT ステートメント
どうやらSQLAlchemy 2.0にてinsertステートメントを使用すると一括INSERTモードで処理してくれるようです。
実際に試してみます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
import csv from datetime import datetime from database.database import session from model.employee import Employee from sqlalchemy import insert def get_insert_data_dict(): with open("data/employee.csv", newline="") as data: rows = csv.DictReader(data) return [row for row in rows] # 100万件CSVからデータ行をdict形式で取得 rows = get_insert_data_dict() # 開始時間を取得 start_datetime = datetime.now() # 100万件登録(execute_insert) session.execute(insert(Employee), rows) session.commit() # 終了時間を取得 finish_datetime = datetime.now() # 処理時間を出力 print("処理時間: " + str(finish_datetime - start_datetime)) |
処理時間:0:00:27.155937(約27秒)
まとめ
これまで実施したINSERT方法と処理時間のまとめです。
30分以上かかっていた処理がかなり高速化されました。
| INSERT方法 | 処理時間 |
|---|---|
| 複数件を一度にINSERTする方法 | 約18分20秒 |
| 一括INSERTする方法 | 約39秒 |
| Core機能を使用してINSERTする方法 | 約24秒 |
| INSERTステートメントを使用する方法 | 約27秒 |
ORM機能の維持にこだわらない場合は「Core機能」を使用して、維持したい場合は「INSERTステートメント」を使用すると良さそうです。
投稿者プロフィール
-
2021年4月からスカイアーチに中途入社しました。
AWSともっと仲良くなるべく日々勉強中です。