はじめに
Webサイトのスクリーンショット取得及び、Webスクレイピングを実行する必要があったのですが、下記2つの課題を、CloudWatch Synthetics CanaryとBedrockを利用する事で、ある程度解決してみました。
- 自前でPuppeteer/Selenium実行環境の作成/メンテナンス実施がしんどい
- コンテンツ変更があった際のセレクタ変更対応を行う事がしんどい
スクレイピングの禁止Webサイトについて
サービス利用規約により、自動化された手段、データ収集の禁止が含まれているWebサイトもあるため、利用規約をご確認下さい。
目次
概要
構成図に起こす程でもありませんが、下記のような構成となっております。

CloudWatch Synthetics Canaryとは
CloudWatch Synthetics Canaryとは、実際のユーザーの動きを模倣したスクリプトを定期的に実行する事が可能な、いわゆる合成モニタリングを実施する事が可能なツールとなっています。
CloudWatch ユーザガイド 合成モニタリング
https://docs.aws.amazon.com/ja_jp/AmazonCloudWatch/latest/monitoring/CloudWatch_Synthetics_Canaries.html
Canary の動画デモ が非常に分かりやすい内容となっております。
Webページの差分検知機能等もあり、とても便利です。
合成モニタリングとは
予防的な問題検知、ユーザーエクスペリエンスの保証という観点で、重要な監視と考えています。
リアルユーザモニタリング(RUM) vs 合成モニタリング: 顧客体験を改善するにはどうしたらいいか
https://newrelic.com/jp/blog/how-to-relic/synthetic-versus-real-user-monitoring
手順
Synthetics Canaryの作成
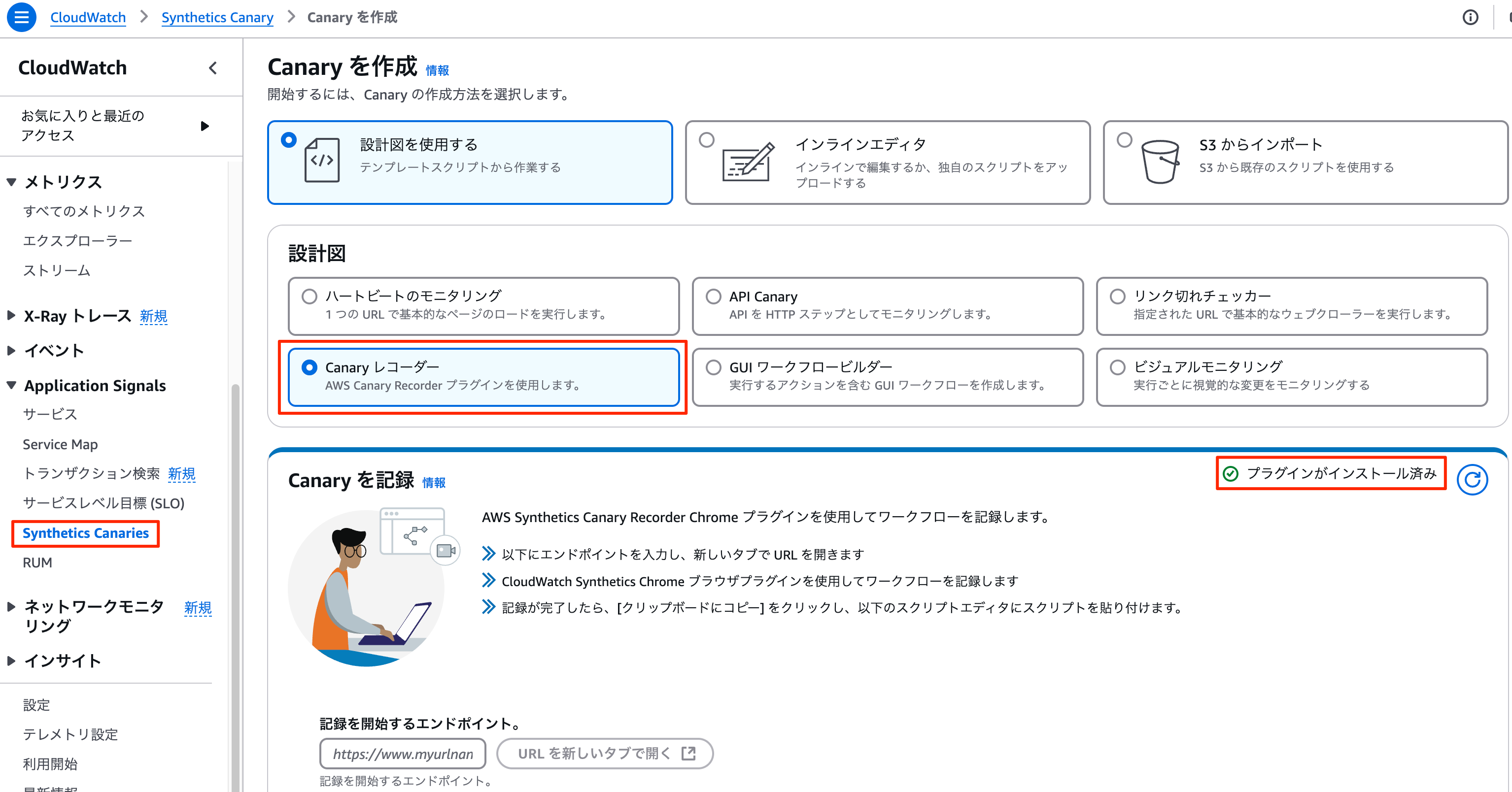
案内にある通り、AWS Synthetics Canary Recorder Chrome プラグインをインストールし、対象のURLを開きます。
プラグインにてUI操作をスクリプト化
プラグインから、レコードを開始した後
ブラウザ操作を行う事で、行った操作がスクリプト化されます。
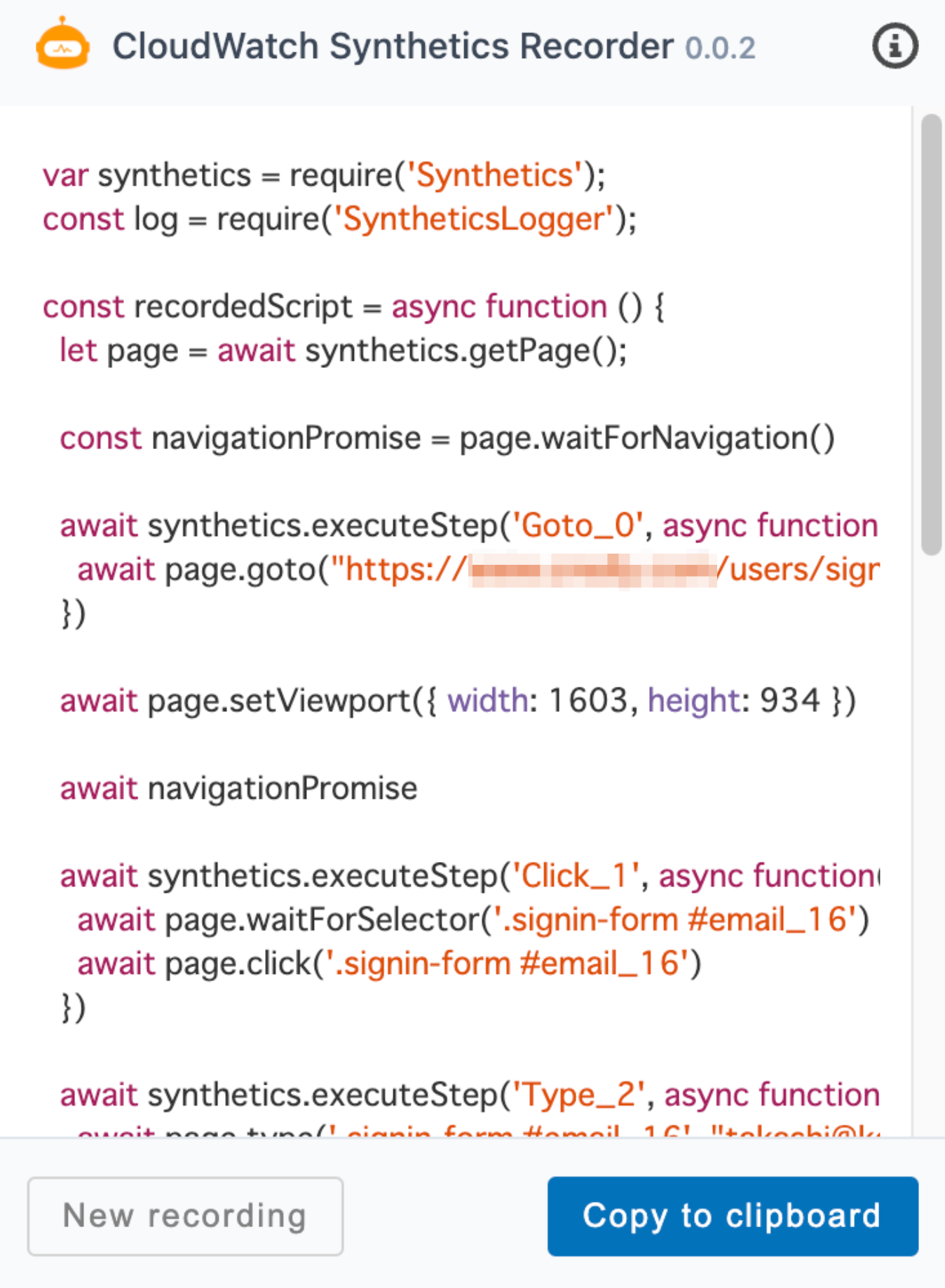
スクリプトを編集しCanaryに設定
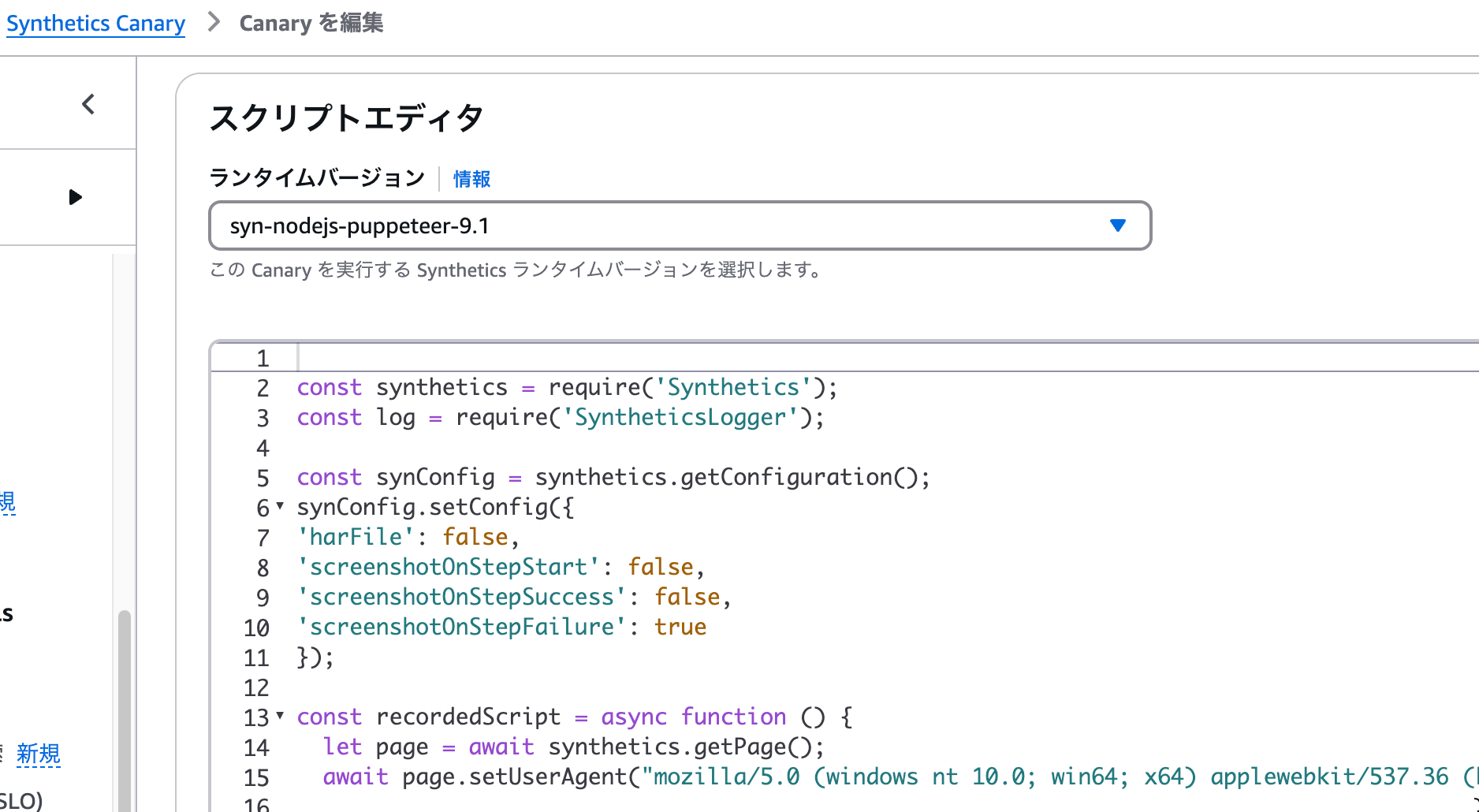
Canaryを作成するとLambdaが作成される事を確認できます。
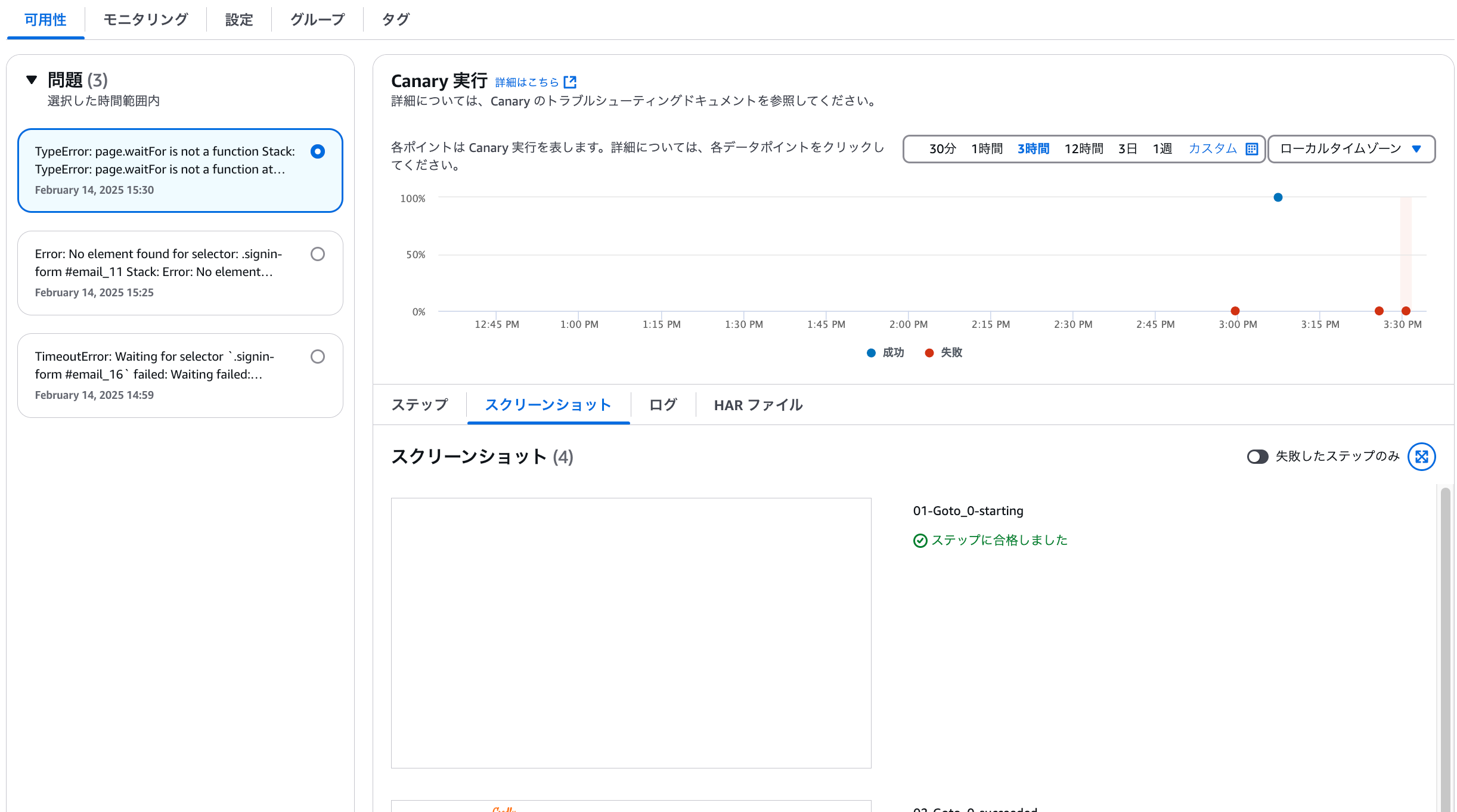
スクリプトの実行結果を確認
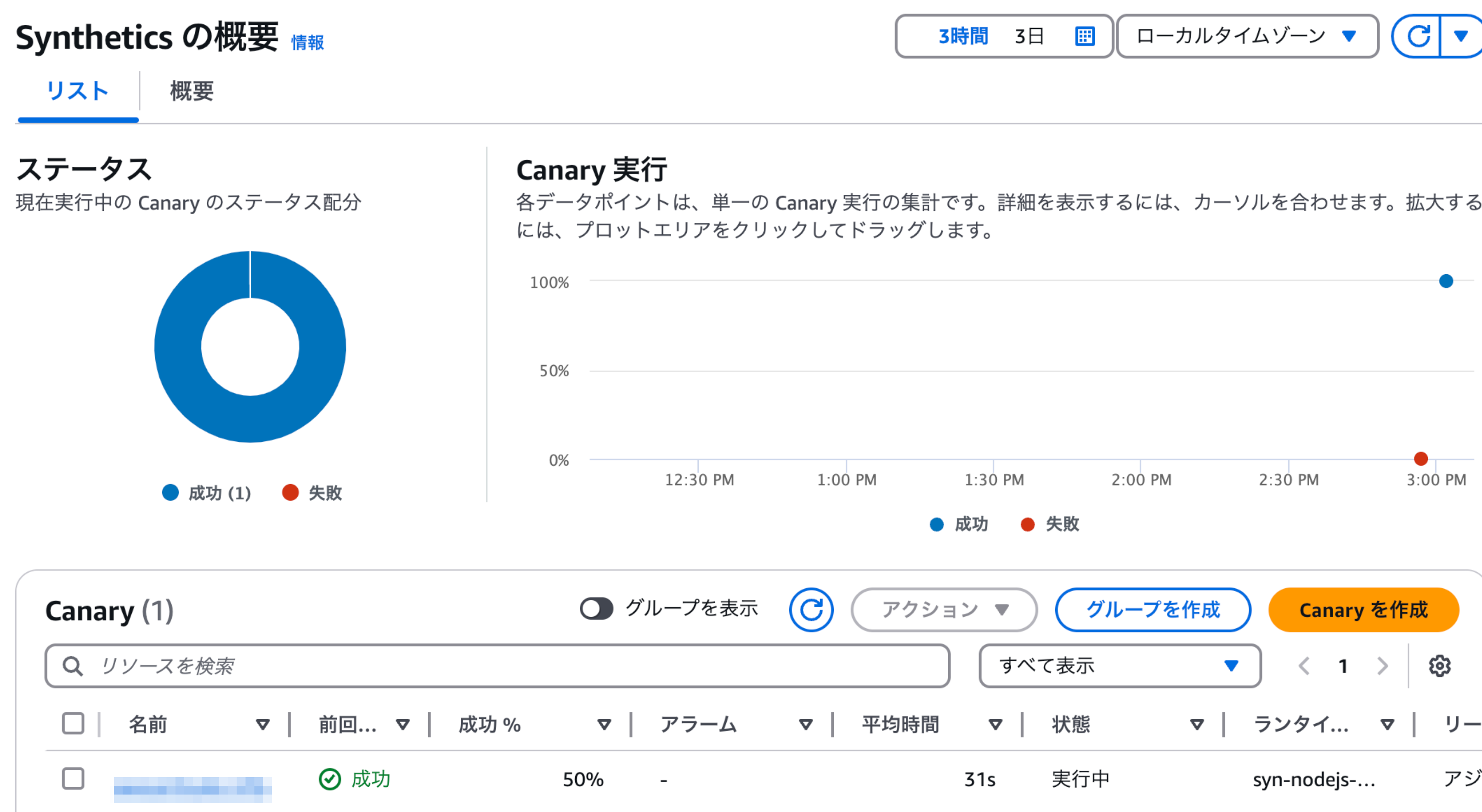
スクリプトの実行結果を確認(詳細)
失敗時の実行結果を、各ステップでスクリーンショット付きで確認する事ができます。
これがとても便利です。
作成されたファイルの確認
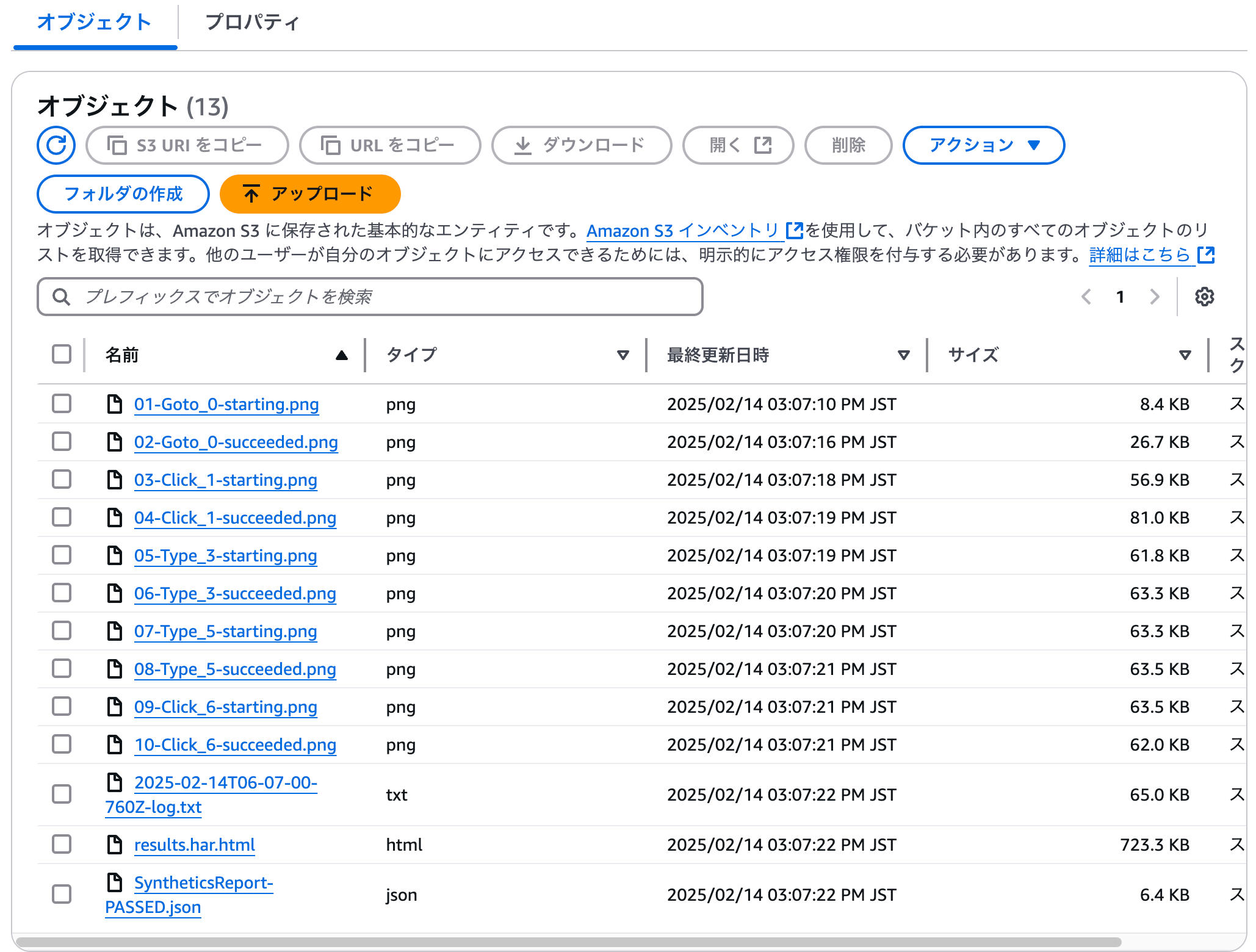
標準設定ですと、synthetics.executeStep の 各ステップでスクリーンショットを取得してくれ、har ファイル等も一緒に作成してくれるため、そこそこの容量となります。
作成したスクリプト (抜粋)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 |
var synthetics = require('Synthetics'); const log = require('SyntheticsLogger'); // 各ステップでのスクリーンショットは取得しない設定、harFileも不要 const synConfig = synthetics.getConfiguration(); synConfig.setConfig({ 'harFile': false, 'screenshotOnStepStart': false, 'screenshotOnStepSuccess': false, 'screenshotOnStepFailure': true }); // UserAgentを設定しないとWAF等で弾かれるWebサイト対策 const recordedScript = async function () { let page = await synthetics.getPage(); await page.setUserAgent("mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/132.0.0.0 safari/537.36") const navigationPromise = page.waitForNavigation() // Login await synthetics.executeStep('Goto_0', async function() { await page.goto("https://test.com/users/sign_in", {waitUntil: 'domcontentloaded', timeout: 30000}) }) await page.setViewport({ width: 1024, height: 768 }) await synthetics.executeStep('Click_1', async function() { await page.waitForSelector('.signin-form input[name="email"]') await page.click('.signin-form input[name="email"]') }) await synthetics.executeStep('Type_1', async function() { await page.type('.signin-form input[name="email"]', "test@test.com") }) await synthetics.executeStep('Click_Login', async function() { await page.waitForSelector('.signin-form > .signin-form__form > .signin-form__submit > .cr-button > .cr-button__content') await page.click('.signin-form > .signin-form__form > .signin-form__submit > .cr-button > .cr-button__content') }) // ページ移動待ち await navigationPromise // 値取得テスト-CloudWatch Logsに出力 await synthetics.executeStep('Click_8', async function() { await page.waitForSelector('body > #root > div > div > div > div.earner-dashboard__activity-snapshot-container > div > div > div:nth-child(1) > div > div.earner-dashboard__activity-snapshot-kpi-value') await page.click('body > #root > div > div > div > div.earner-dashboard__activity-snapshot-container > div > div > div:nth-child(1) > div > div.earner-dashboard__activity-snapshot-kpi-value') }) const value1 = await page.evaluate(() => { const kpiValue = document.querySelector("body > #root > div > div > div > div.earner-dashboard__activity-snapshot-container > div > div > div:nth-child(1) > div > div.earner-dashboard__activity-snapshot-kpi-value"); return kpiValue.textContent; }); data = { "test.com": { "value1": value1 }, } console.log(JSON.stringify(data)); // ページ全体のスクリーンショット取得 // Change browser viewport var width = await page.evaluate(() => document.body.scrollWidth); var height = await page.evaluate(() => document.body.scrollHeight); await page.setViewport({ width: width, height: height }) // Take Screen Shot await synthetics.takeScreenshot('loaded', 'toppage'); }; exports.handler = async () => { return await recordedScript(); }; |
スクリーンショット解析Lambdaの作成
Synthetics Canary 実行結果保存バケットに下記のような条件で、解析Lambdaを起動するように設定
|
1 2 |
s3.EventType.OBJECT_CREATED, s3.NotificationKeyFilter(prefix="", suffix="loaded-toppage.png"), |
スクリプト (抜粋)
手抜き仕様で、処理されるのが単一ファイルのみなので注意
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 |
import json import boto3 import base64 import os from botocore.exceptions import ClientError def lambda_handler(event, context): print("イベント受信:", json.dumps(event)) # S3イベントからバケット名とオブジェクトキーを取得 bucket_name = event['Records'][0]['s3']['bucket']['name'] object_key = event['Records'][0]['s3']['object']['key'] # オブジェクトキーが *loaded-toppage.png であることを確認 if not object_key.endswith('loaded-toppage.png'): print(f"対象外のファイル: {object_key}") return { 'statusCode': 200, 'body': json.dumps('対象外のファイルのため処理をスキップしました') } try: # S3からファイルを取得 s3_client = boto3.client('s3') response = s3_client.get_object(Bucket=bucket_name, Key=object_key) image_content = response['Body'].read() # 画像をBase64エンコード base64_image = base64.b64encode(image_content).decode('utf-8') # Bedrockクライアントを初期化 bedrock_runtime = boto3.client(service_name='bedrock-runtime') # Anthropic Claude 3 haiku を使用して画像解析 response = bedrock_runtime.invoke_model( modelId='anthropic.claude-3-haiku-20240307-v1:0', body=json.dumps({ "anthropic_version": "bedrock-2023-05-31", "max_tokens": 1000, "messages": [ { "role": "user", "content": [ { "type": "image", "source": { "type": "base64", "media_type": "image/png", "data": base64_image } }, { "type": "text", "text": "この画像を解析しXXXX" } ] } ] }) ) # レスポンスから生成AIの解析結果を抽出 response_body = json.loads(response['body'].read()) ai_analysis = response_body['content'][0]['text'] print("生成AI解析結果:", ai_analysis) return { 'statusCode': 200, 'body': json.dumps({ 'message': 'Image analyzed successfully', 'analysis': ai_analysis }) } except Exception as e: print("エラー発生:", str(e)) return { 'statusCode': 500, 'body': json.dumps({ 'message': 'Error analyzing image', 'error': str(e) }) } |
Tips
Synthetics Recorder利用に際して
レコードする際には、プライベートブラウザにて実施する等で、Cookieがない状態からUI操作を行う必要があるWebサイトがあります(Cookie受け入れ許可ダイアログ等)
idが動的に生成されるWebサイト
idが動的に生成されるWebサイトが多いため、name 属性で指定してあげる等
|
1 2 3 |
page.waitForSelector('.signin-form #input_11') ↓ page.waitForSelector('.signin-form input[name="password"]') |
WebページにSyntheticsからアクセスすると Forbidden 等が返却される
国内IP利用 + UserAgent 設定でクリア出来るパターンが多かったです。
自分のuserAgent 確認 console.log(window.navigator.userAgent)
|
1 |
await page.setUserAgent("mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/132.0.0.0 safari/537.36") |
Canaryの設定で気を付ける事
- 実行時間制限が標準のタイムアウト時間だと長いため必要に応じて調整する
- データ保持期間が標準だと1ヶ月等なので、必要に応じて調整する
不要ファイルの作成防止
スクリプトの先頭で下記のような設定をする事で、作成ファイルを絞る事ができました。
|
1 2 3 4 5 6 7 8 |
// 各ステップでのスクリーンショットは取得しない設定、harFileも不要 const synConfig = synthetics.getConfiguration(); synConfig.setConfig({ 'harFile': false, 'screenshotOnStepStart': false, 'screenshotOnStepSuccess': false, 'screenshotOnStepFailure': true }); |
スクリーンショットの大きさ
生成AIにスクリーンショット画像を渡す際に、大きすぎる画像だと良い結果が得られないケースがありました。
適切に領域を切って渡してあげる等工夫が必要と思いました。
|
1 2 3 4 5 |
// ページ全体のスクリーンショット取得 // Change browser viewport var width = await page.evaluate(() => document.body.scrollWidth); var height = await page.evaluate(() => document.body.scrollHeight); await page.setViewport({ width: width, height: height }) |
まとめ
本来の使い方とは少し毛色が異なりますが
自前でLambda Layerを作成/管理する事に比べ、工数の削減を実現できました。
失敗時のデバッグも行いやすいと感じており、とても良いサービスと感じました。
(本記事のスクリプト例とは異なりますが、自分の契約しているサービスがAPIを提供してくれていないため、日に1回動かしております。MFAが強制で有効になると困るなぁとは思っておりますが :sweat_smile:)
一方で、本来の使い方に近いものですと、Synthetics Canary の実態はLambdaのため
StepFunctionsでSynthetics Canary Lambdaを複数起動させて負荷テストを実施するという下記ブログについて良い利用法だなと感じましたので、機会があれば検討してみたいと思います。
参考
Puppeteer を使用した Node.js Canary スクリプト用のライブラリ関数
Amazon CloudWatch Synthetics を使用して負荷テストと合成モニタリング
S3 Image Analysis
Analyzing images in S3 with Claude 3 and AWS Lambda
https://github.com/aws-samples/s3-image-analysis-lambda-claude3/blob/main/README_en.md
投稿者プロフィール
-
Japan AWS Ambassadors 2023, 2024
開発会社での ASP型WEBサービス企画 / 開発 / サーバ運用 を経て
2010年よりスカイアーチネットワークスに在籍しております
機械化/効率化/システム構築を軸に人に喜んで頂ける物作りが大好きです。